서울시 범죄 현황¶
서울시 자치구별 5대 범죄(살인, 강도, 강간, 절도, 폭력) 발생과 검거 현황을 분석해 본다.
목표¶
- 압축 파일(zip)을 활용한다.
- 주소를 검색 API를 이용해서 검색하여 정확한 주소명(도로명, 지번명)과 위도/경도를 알아낸다.
자료 불러오기¶
구글에서 서울시 관서별 5대 범죄 현황을 검색하여 data.go.kr 사이트에서 zip 파일을 다운받아 data 폴더에 저장한다.
zip 파일로부터 직접 읽어오자.
In [1]: import zipfile
...: import re
...: import pandas as pd
...: import numpy as np
...: pd.set_option('max_rows', 10)
...:
...: zipref = zipfile.ZipFile('data/관서별_5대범죄_발생_및_검거_현황_2000_2016_.zip', 'r')
...:
파일 인코딩이 cp949이므로 옵션을 설정해야 하고 한글 파일 이름이 깨져서 보이지 않으므로 숫자만 이름으로 선택한다. 사전형으로 저장을 하자.
In [7]: dfs = {re.sub(r'(\d{4}).*', r'\1', fname): pd.read_csv(zipref.open(fname), encoding='cp949') for fname in zipref.namelist() if fname.endswith('.csv')}
...: zipref.close()
...: dfs
...:
Out[9]:
{'2000': 구분 죄종 발생검거 건수 Unnamed: 4 Unnamed: 5 Unnamed: 6 ... Unnamed: 27 Unnamed: 28 Unnamed: 29 Unnamed: 30 Unnamed: 31 Unnamed: 32 Unnamed: 33
0 중부 살인 발생 1 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
1 중부 살인 검거 1 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
2 중부 강도 발생 17 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
3 중부 강도 검거 15 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
4 중부 강간 발생 14 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
.. .. .. ... ... ... ... ... ... ... ... ... ... ... ... ...
305 수서 강간 검거 29 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
306 수서 절도 발생 1183 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
307 수서 절도 검거 352 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
308 수서 폭력 발생 3351 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
309 수서 폭력 검거 2983 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN
[310 rows x 34 columns], '2001': 구분 죄종 발생검거 건수
0 중부 살인 발생 0
1 중부 살인 검거 0
2 중부 강도 발생 17
3 중부 강도 검거 6
4 중부 강간 발생 80
.. .. .. ... ...
305 수서 강간 검거 43
306 수서 절도 발생 1665
307 수서 절도 검거 632
308 수서 폭력 발생 3164
309 수서 폭력 검거 2629
[310 rows x 4 columns], '2002': 구분 죄종 발생검거 건수
0 중부 살인 발생 1.0
1 중부 살인 검거 2.0
2 중부 강도 발생 21.0
3 중부 강도 검거 18.0
4 중부 강간 발생 59.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2003': 구분 죄종 발생검거 건수
0 중부 살인 발생 0
1 중부 살인 검거 0
2 중부 강도 발생 46
3 중부 강도 검거 50
4 중부 강간 발생 70
.. .. .. ... ...
305 수서 강간 검거 30
306 수서 절도 발생 1694
307 수서 절도 검거 1000
308 수서 폭력 발생 2693
309 수서 폭력 검거 2431
[310 rows x 4 columns], '2004': 구분 죄종 발생검거 건수
0 중부 살인 발생 2.0
1 중부 살인 검거 2.0
2 중부 강도 발생 13.0
3 중부 강도 검거 17.0
4 중부 강간 발생 128.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2005': 구분 죄종 발생검거 건수
0 중부 살인 발생 2.0
1 중부 살인 검거 3.0
2 중부 강도 발생 10.0
3 중부 강도 검거 8.0
4 중부 강간 발생 89.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2006': 구분 죄종 발생검거 건수
0 중부 살인 발생 4.0
1 중부 살인 검거 4.0
2 중부 강도 발생 28.0
3 중부 강도 검거 18.0
4 중부 강간 발생 121.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2007': 구분 죄종 발생검거 건수
0 중부 살인 발생 4.0
1 중부 살인 검거 4.0
2 중부 강도 발생 13.0
3 중부 강도 검거 12.0
4 중부 강간 발생 83.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2008': 구분 죄종 발생검거 건수
0 중부 살인 발생 4.0
1 중부 살인 검거 4.0
2 중부 강도 발생 20.0
3 중부 강도 검거 26.0
4 중부 강간 발생 76.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2009': 구분 죄종 발생검거 건수
0 중부 살인 발생 1.0
1 중부 살인 검거 1.0
2 중부 강도 발생 28.0
3 중부 강도 검거 24.0
4 중부 강간 발생 94.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2010': 구분 죄종 발생검거 건수
0 중부 살인 발생 5.0
1 중부 살인 검거 5.0
2 중부 강도 발생 16.0
3 중부 강도 검거 11.0
4 중부 강간 발생 117.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2011': 구분 죄종 발생검거 검거
0 중부 살인 발생 2.0
1 중부 살인 검거 3.0
2 중부 강도 발생 14.0
3 중부 강도 검거 19.0
4 중부 강간 발생 89.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2012': 구분 죄종 발생검거 검거
0 중부 살인 발생 4.0
1 중부 살인 검거 5.0
2 중부 강도 발생 9.0
3 중부 강도 검거 8.0
4 중부 강간 발생 100.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2013': 구분 죄종 발생검거 건수
0 중부 살인 발생 0.0
1 중부 살인 검거 0.0
2 중부 강도 발생 6.0
3 중부 강도 검거 7.0
4 중부 강간 발생 128.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2014': 구분 죄종 발생검거 건수
0 중부 살인 발생 3.0
1 중부 살인 검거 2.0
2 중부 강도 발생 8.0
3 중부 강도 검거 8.0
4 중부 강간 발생 143.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2015': 구분 죄종 발생검거 건수
0 중부 살인 발생 2.0
1 중부 살인 검거 2.0
2 중부 강도 발생 3.0
3 중부 강도 검거 2.0
4 중부 강간 발생 105.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns], '2016': 구분 죄종 발생검거 건수
0 중부 살인 발생 2.0
1 중부 살인 검거 2.0
2 중부 강도 발생 3.0
3 중부 강도 검거 3.0
4 중부 강간 발생 141.0
... ... ... ... ...
65529 NaN NaN NaN NaN
65530 NaN NaN NaN NaN
65531 NaN NaN NaN NaN
65532 NaN NaN NaN NaN
65533 NaN NaN NaN NaN
[65534 rows x 4 columns]}
2000년부터 2016년까지 자료가 들어가 있는데 필요없는 열과 행이 들어가 있다. 이것을 제거하자.
자료 정제¶
Unnamed 열이름들이 몇 개나 있는지를 조사해보자.
In [10]: [(key, sum(df.columns.str.contains('Unn'))) for key, df in dfs.items()]
Out[10]:
[('2009', 0),
('2010', 0),
('2011', 0),
('2012', 0),
('2013', 0),
('2014', 0),
('2015', 0),
('2016', 0),
('2000', 30),
('2001', 0),
('2002', 0),
('2004', 0),
('2005', 0),
('2006', 0),
('2007', 0),
('2008', 0),
('2003', 0)]
2000년도에만 30개가 있는 것을 알 수 있다.
Unnamed 열 이름을 제거하자.
In [11]: [(key, df.drop([x for x in df.columns if 'Un' in x], axis=1, inplace=True)) for key, df in dfs.items()]
Out[11]:
[('2009', None),
('2010', None),
('2011', None),
('2012', None),
('2013', None),
('2014', None),
('2015', None),
('2016', None),
('2000', None),
('2001', None),
('2002', None),
('2004', None),
('2005', None),
('2006', None),
('2007', None),
('2008', None),
('2003', None)]
NA 행으로만 이루어진 행들이 각 파일에 몇 개씩 있나를 조사해보자.
In [12]: [(key, sum(df.isna().all(axis=1))) for key, df in dfs.items()]
Out[12]:
[('2009', 65224),
('2010', 65224),
('2011', 65224),
('2012', 65224),
('2013', 65224),
('2014', 65224),
('2015', 65224),
('2016', 65224),
('2000', 0),
('2001', 0),
('2002', 65224),
('2004', 65224),
('2005', 65224),
('2006', 65224),
('2007', 65224),
('2008', 65224),
('2003', 0)]
2000, 2001, 2003년을 제외하고 동일하게 65224개의 NA행들이 있음을 알 수 있다.
NA 행들을 모두 제거하자. thresh=4를 이용하면 NA가 아닌 항목이 4개 이상인 행들을 남겨둔다.
In [13]: [(key, df.dropna(inplace=True, thresh=4)) for key, df in dfs.items()]
Out[13]:
[('2009', None),
('2010', None),
('2011', None),
('2012', None),
('2013', None),
('2014', None),
('2015', None),
('2016', None),
('2000', None),
('2001', None),
('2002', None),
('2004', None),
('2005', None),
('2006', None),
('2007', None),
('2008', None),
('2003', None)]
각 파일에 연도 열을 추가하자.
In [14]: for key, df in dfs.items():
....: df['연도'] = key
....: dfs
....:
Out[14]:
{'2000': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 1 2000
1 중부 살인 검거 1 2000
2 중부 강도 발생 17 2000
3 중부 강도 검거 15 2000
4 중부 강간 발생 14 2000
.. .. .. ... ... ...
305 수서 강간 검거 29 2000
306 수서 절도 발생 1183 2000
307 수서 절도 검거 352 2000
308 수서 폭력 발생 3351 2000
309 수서 폭력 검거 2983 2000
[310 rows x 5 columns], '2001': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 0 2001
1 중부 살인 검거 0 2001
2 중부 강도 발생 17 2001
3 중부 강도 검거 6 2001
4 중부 강간 발생 80 2001
.. .. .. ... ... ...
305 수서 강간 검거 43 2001
306 수서 절도 발생 1665 2001
307 수서 절도 검거 632 2001
308 수서 폭력 발생 3164 2001
309 수서 폭력 검거 2629 2001
[310 rows x 5 columns], '2002': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 1.0 2002
1 중부 살인 검거 2.0 2002
2 중부 강도 발생 21.0 2002
3 중부 강도 검거 18.0 2002
4 중부 강간 발생 59.0 2002
.. .. .. ... ... ...
305 수서 강간 검거 32.0 2002
306 수서 절도 발생 2120.0 2002
307 수서 절도 검거 1156.0 2002
308 수서 폭력 발생 2803.0 2002
309 수서 폭력 검거 2449.0 2002
[310 rows x 5 columns], '2003': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 0 2003
1 중부 살인 검거 0 2003
2 중부 강도 발생 46 2003
3 중부 강도 검거 50 2003
4 중부 강간 발생 70 2003
.. .. .. ... ... ...
305 수서 강간 검거 30 2003
306 수서 절도 발생 1694 2003
307 수서 절도 검거 1000 2003
308 수서 폭력 발생 2693 2003
309 수서 폭력 검거 2431 2003
[310 rows x 5 columns], '2004': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 2.0 2004
1 중부 살인 검거 2.0 2004
2 중부 강도 발생 13.0 2004
3 중부 강도 검거 17.0 2004
4 중부 강간 발생 128.0 2004
.. .. .. ... ... ...
305 수서 강간 검거 53.0 2004
306 수서 절도 발생 1529.0 2004
307 수서 절도 검거 600.0 2004
308 수서 폭력 발생 2600.0 2004
309 수서 폭력 검거 2338.0 2004
[310 rows x 5 columns], '2005': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 2.0 2005
1 중부 살인 검거 3.0 2005
2 중부 강도 발생 10.0 2005
3 중부 강도 검거 8.0 2005
4 중부 강간 발생 89.0 2005
.. .. .. ... ... ...
305 수서 강간 검거 81.0 2005
306 수서 절도 발생 1441.0 2005
307 수서 절도 검거 893.0 2005
308 수서 폭력 발생 2207.0 2005
309 수서 폭력 검거 2010.0 2005
[310 rows x 5 columns], '2006': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 4.0 2006
1 중부 살인 검거 4.0 2006
2 중부 강도 발생 28.0 2006
3 중부 강도 검거 18.0 2006
4 중부 강간 발생 121.0 2006
.. .. .. ... ... ...
305 수서 강간 검거 87.0 2006
306 수서 절도 발생 890.0 2006
307 수서 절도 검거 716.0 2006
308 수서 폭력 발생 1931.0 2006
309 수서 폭력 검거 1771.0 2006
[310 rows x 5 columns], '2007': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 4.0 2007
1 중부 살인 검거 4.0 2007
2 중부 강도 발생 13.0 2007
3 중부 강도 검거 12.0 2007
4 중부 강간 발생 83.0 2007
.. .. .. ... ... ...
305 수서 강간 검거 117.0 2007
306 수서 절도 발생 815.0 2007
307 수서 절도 검거 506.0 2007
308 수서 폭력 발생 1881.0 2007
309 수서 폭력 검거 1805.0 2007
[310 rows x 5 columns], '2008': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 4.0 2008
1 중부 살인 검거 4.0 2008
2 중부 강도 발생 20.0 2008
3 중부 강도 검거 26.0 2008
4 중부 강간 발생 76.0 2008
.. .. .. ... ... ...
305 수서 강간 검거 99.0 2008
306 수서 절도 발생 1365.0 2008
307 수서 절도 검거 539.0 2008
308 수서 폭력 발생 2138.0 2008
309 수서 폭력 검거 1853.0 2008
[310 rows x 5 columns], '2009': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 1.0 2009
1 중부 살인 검거 1.0 2009
2 중부 강도 발생 28.0 2009
3 중부 강도 검거 24.0 2009
4 중부 강간 발생 94.0 2009
.. .. .. ... ... ...
305 수서 강간 검거 80.0 2009
306 수서 절도 발생 1570.0 2009
307 수서 절도 검거 745.0 2009
308 수서 폭력 발생 2201.0 2009
309 수서 폭력 검거 1908.0 2009
[310 rows x 5 columns], '2010': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 5.0 2010
1 중부 살인 검거 5.0 2010
2 중부 강도 발생 16.0 2010
3 중부 강도 검거 11.0 2010
4 중부 강간 발생 117.0 2010
.. .. .. ... ... ...
305 수서 강간 검거 84.0 2010
306 수서 절도 발생 1584.0 2010
307 수서 절도 검거 604.0 2010
308 수서 폭력 발생 1944.0 2010
309 수서 폭력 검거 1646.0 2010
[310 rows x 5 columns], '2011': 구분 죄종 발생검거 검거 연도
0 중부 살인 발생 2.0 2011
1 중부 살인 검거 3.0 2011
2 중부 강도 발생 14.0 2011
3 중부 강도 검거 19.0 2011
4 중부 강간 발생 89.0 2011
.. .. .. ... ... ...
305 수서 강간 검거 109.0 2011
306 수서 절도 발생 1780.0 2011
307 수서 절도 검거 422.0 2011
308 수서 폭력 발생 2000.0 2011
309 수서 폭력 검거 1516.0 2011
[310 rows x 5 columns], '2012': 구분 죄종 발생검거 검거 연도
0 중부 살인 발생 4.0 2012
1 중부 살인 검거 5.0 2012
2 중부 강도 발생 9.0 2012
3 중부 강도 검거 8.0 2012
4 중부 강간 발생 100.0 2012
.. .. .. ... ... ...
305 수서 강간 검거 86.0 2012
306 수서 절도 발생 1820.0 2012
307 수서 절도 검거 464.0 2012
308 수서 폭력 발생 1920.0 2012
309 수서 폭력 검거 1519.0 2012
[310 rows x 5 columns], '2013': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 0.0 2013
1 중부 살인 검거 0.0 2013
2 중부 강도 발생 6.0 2013
3 중부 강도 검거 7.0 2013
4 중부 강간 발생 128.0 2013
.. .. .. ... ... ...
305 수서 강간 검거 94.0 2013
306 수서 절도 발생 1696.0 2013
307 수서 절도 검거 470.0 2013
308 수서 폭력 발생 1817.0 2013
309 수서 폭력 검거 1512.0 2013
[310 rows x 5 columns], '2014': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 3.0 2014
1 중부 살인 검거 2.0 2014
2 중부 강도 발생 8.0 2014
3 중부 강도 검거 8.0 2014
4 중부 강간 발생 143.0 2014
.. .. .. ... ... ...
305 수서 강간 검거 115.0 2014
306 수서 절도 발생 1555.0 2014
307 수서 절도 검거 407.0 2014
308 수서 폭력 발생 1709.0 2014
309 수서 폭력 검거 1394.0 2014
[310 rows x 5 columns], '2015': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 2.0 2015
1 중부 살인 검거 2.0 2015
2 중부 강도 발생 3.0 2015
3 중부 강도 검거 2.0 2015
4 중부 강간 발생 105.0 2015
.. .. .. ... ... ...
305 수서 강간 검거 124.0 2015
306 수서 절도 발생 1439.0 2015
307 수서 절도 검거 666.0 2015
308 수서 폭력 발생 1819.0 2015
309 수서 폭력 검거 1559.0 2015
[310 rows x 5 columns], '2016': 구분 죄종 발생검거 건수 연도
0 중부 살인 발생 2.0 2016
1 중부 살인 검거 2.0 2016
2 중부 강도 발생 3.0 2016
3 중부 강도 검거 3.0 2016
4 중부 강간 발생 141.0 2016
.. .. .. ... ... ...
305 수서 강간 검거 144.0 2016
306 수서 절도 발생 1149.0 2016
307 수서 절도 검거 789.0 2016
308 수서 폭력 발생 1666.0 2016
309 수서 폭력 검거 1431.0 2016
[310 rows x 5 columns]}
디비 저장¶
각 파일의 열 이름을 살펴보자.
In [15]: [(key, df.columns) for key, df in dfs.items()]
Out[15]:
[('2009', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2010', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2011', Index(['구분', '죄종', '발생검거', '검거', '연도'], dtype='object')),
('2012', Index(['구분', '죄종', '발생검거', '검거', '연도'], dtype='object')),
('2013', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2014', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2015', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2016', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2000', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2001', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2002', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2004', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2005', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2006', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2007', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2008', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object')),
('2003', Index(['구분', '죄종', '발생검거', '건수', '연도'], dtype='object'))]
2011, 2012년도 열 이름이 다른 해와 다르게 검거라고 되어 있다. 이것을 건수로 변경하자.
In [16]: [(key, df.rename(columns={'검거': '건수'}, inplace=True)) for key, df in dfs.items()]
Out[16]:
[('2009', None),
('2010', None),
('2011', None),
('2012', None),
('2013', None),
('2014', None),
('2015', None),
('2016', None),
('2000', None),
('2001', None),
('2002', None),
('2004', None),
('2005', None),
('2006', None),
('2007', None),
('2008', None),
('2003', None)]
다음은 pd.concat 함수를 이용해서 데이터프레임을 모두 하나로 합친다. 사전형이 입력되면 사전형의 키값이 인덱스로 변환된다.
In [17]: crime = pd.concat(dfs)
....: crime.info()
....:
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 5270 entries, (2000, 0) to (2016, 309)
Data columns (total 5 columns):
구분 5270 non-null object
죄종 5270 non-null object
발생검거 5270 non-null object
건수 5270 non-null float64
연도 5270 non-null object
dtypes: float64(1), object(4)
memory usage: 223.9+ KB
연도 열이 문자열이므로 정수형으로 변경하고 건수 열도 정수형으로 변경하자.
In [19]: crime.연도 = crime.연도.astype('int')
....: crime.건수 = crime.건수.astype('int')
....:
구분 열이름을 경찰서로 변경하자.
In [21]: crime.rename(columns={'구분': '경찰서'}, inplace=True)
각 열의 내용을 살펴보자.
In [22]: crime.select_dtypes('object').apply(lambda x: pd.Series(x.unique()))
Out[22]:
경찰서 죄종 발생검거
0 중부 살인 발생
1 종로 강도 검거
2 남대문 강간 NaN
3 서대문 절도 NaN
4 혜화 폭력 NaN
.. ... ... ...
26 노원 NaN NaN
27 방배 NaN NaN
28 은평 NaN NaN
29 도봉 NaN NaN
30 수서 NaN NaN
[31 rows x 3 columns]
커다란 문제는 보이지 않는 것 같다.
NA가 있는지 살펴보자.
In [23]: sum(crime.isna().any())
Out[23]: 0
디비에 저장하자.
In [24]: import sqlite3
....: conn = sqlite3.connect('./data/seoul.sqlite3')
....: crime.to_sql('crime', conn, index=False)
....: conn.close()
....:
편의를 위해서 앞 장에서 pop.sqlite3 디비에 저장했던 테이블들을 seoul.sqlite3 디비에 저장하자.
In [25]: con_pop = sqlite3.connect('./data/pop.sqlite3')
....: pop = pd.read_sql("select * from pop", con_pop)
....: cctv = pd.read_sql("select * from cctv", con_pop)
....: con_pop.close()
....: conn = sqlite3.connect('./data/seoul.sqlite3')
....: pop.to_sql("pop", conn)
....: cctv.to_sql("cctv", conn)
....: conn.close()
....:
VWorld API 이용 주소 검색¶
VWorld 지도 검색 API를 이용해서 주소를 입력하면 지번 및 도로명 및 위/경도를 알아낼 수 있다. VWorld API를 이용하기 위해서는 먼저 회원가입 후 인증키를 받아야 한다. 사용법은 웹사이트를 참고하면 된다.
인증키를 받았다고 가정하면 다음과 같이 검색과 결과를 받을 수 있다.
In [26]: import requests
....: resp = requests.get('http://api.vworld.kr/req/search?key=인증키입력부분&reque
....: st=search&size=10&type=place&query=강남경찰서&format=json')
....: resp.json()
....:
Out[26]:
{'response': {'page': {'current': '1', 'size': '10', 'total': '2'},
'record': {'current': '10', 'total': '16'},
'result': {'crs': 'EPSG:4326',
'items': [{'address': {'parcel': '서울특별시 강남구 삼성동 171-2',
'road': '서울특별시 강남구 테헤란로113길 12'},
'category': '정부행정기관 > 치안/안보부처 > 경찰청',
'id': 'AA0000557912',
'point': {'x': '127.067194351542', 'y': '37.5090497296493'},
'title': '서울강남경찰서'},
{'address': {'parcel': '', 'road': ''},
'category': '교통시설 > 버스터미널/정류장 > 정류장',
'id': 'AA0009688456',
'point': {'x': '127.067120000476', 'y': '37.5098699998996'},
'title': '강남경찰서.강남운전면허시험장정류장'},
{'address': {'parcel': '', 'road': ''},
'category': '교통시설 > 버스터미널/정류장 > 정류장',
'id': 'AA0009688883',
'point': {'x': '127.065949999596', 'y': '37.509770000102'},
'title': '강남경찰서면허시험장정류장'},
{'address': {'parcel': '', 'road': ''},
'category': '교통시설 > 버스터미널/정류장 > 정류장',
'id': 'AA0009684034',
'point': {'x': '127.065989999507', 'y': '37.5095599998675'},
'title': '강남경찰서.강남운전면허시험장정류장'},
{'address': {'parcel': '서울특별시 강남구 논현동 42-6',
'road': '서울특별시 강남구 학동로17길 13'},
'category': '정부행정기관 > 치안/안보부처 > 경찰청',
'id': 'AA0009154677',
'point': {'x': '127.026024819286', 'y': '37.5135511178908'},
'title': '서울강남경찰서논현1파출소'},
{'address': {'parcel': '서울특별시 강남구 논현동 58-13', 'road': '서울특별시강남구 학동로 169'},
'category': '정부행정기관 > 치안/안보부처 > 경찰청',
'id': 'AA0010029010',
'point': {'x': '127.029322774658', 'y': '37.5138635184868'},
'title': '서울강남경찰서논현1파출소'},
{'address': {'parcel': '서울특별시 강남구 대치동 997', 'road': '서울특별시강남구 테헤란로 624'},
'category': '교통시설 > 버스터미널/정류장 > 정류장',
'id': 'AA0009645290',
'point': {'x': '127.066001999827', 'y': '37.5095529998435'},
'title': '강남경찰서.강남운전면허시험장정류장'},
{'address': {'parcel': '서울특별시 강남구 삼성동 107-3',
'road': '서울특별시 강남구 영동대로112길 6'},
'category': '정부행정기관 > 치안/안보부처 > 경찰청',
'id': 'AA0000562500',
'point': {'x': '127.060689561917', 'y': '37.5149115385337'},
'title': '서울강남경찰서삼성1파출소'},
{'address': {'parcel': '서울특별시 강남구 삼성동 170-5',
'road': '서울특별시 강남구 테헤란로113길 7'},
'category': '도로시설 > 진출입시설 > 미분류',
'id': 'AA0009770678',
'point': {'x': '127.066222045683', 'y': '37.5108711388763'},
'title': '강남경찰서(임시)입구'},
{'address': {'parcel': '서울특별시 강남구 삼성동 170-8',
'road': '서울특별시 강남구 테헤란로 623'},
'category': '교통시설 > 버스터미널/정류장 > 정류장',
'id': 'AA0009641451',
'point': {'x': '127.065794000155', 'y': '37.5099129996285'},
'title': '강남경찰서면허시험장정류장'}],
'type': 'place'},
'service': {'name': 'search',
'operation': 'search',
'time': '13(ms)',
'version': '2.0'},
'status': 'OK'}}
요청 매개변수¶
검색 API 2.0을 사용하고 있으며 key는 발급받은 인증키, format은 응답 받을 형식으로 json과 xml을 사용할 수 있다. request는 search이어야 한다. size는 한 페이지에 출력될 갯수를 나타낸다. 최소 1, 최대 1000까지 사용할 수 있다. page는 결과값이 많아서 여러 페이지일 때 어떤 페이지를 선택할 것인가를 나타내는 것이다. 기본값은 1, 즉 첫 페이지이다. query는 검색할 키워드를 넣는 부분이다. type는 place와 address 두 가지를 선택할 수 있는데 place는 장소 이름으로 검색하는 것이고 address는 비교적 정확한 주소를 넣어야 검색이 된다. category는 type에서 address를 선택했을 때 필수적으로 입력해야 하는 부분으로 도로명일 때는 road를 선택하고 지번 주소는 parcel을 선택한다. type이 place일 때는 자연수를 입력해야하는데 아직 정해지지 않은 것 같다.
응답 변수¶
응답 결과 정보 중에서 record의 total은 전체 검색된 결과의 수를 나타내고 current는 현재 페이지에 보여지고 있는 결과의 수를 나타낸다. page의 total은 검색 결과의 전체 페이지 수이고 current는 현재 보여지고 있는 페이지 번호, size는 페이지당 보여지는 결과의 수를 나타낸다. result의 crs는 응답결과 좌표계의 종류를 의미한다. status의 OK는 결과가 있는 경우, NOT_FOUND는 검색 결과가 없는 경우, ERROR는 오류가 발생된 경우이다.
질의 문자열 주소 검색¶
문자열을 입력하면 문자열 반환된 결과의 항목 중 title과 정확히 일치하는 것 중에서 주소와 경위도 리스트를 반환하는 함수를 만들자. 매개변수 key에는 발급받은 본인의 인증키를 입력해야 한다.
In [27]: def getAddressCoords(key, queryString, page=1, size=50):
....: qStmt = "key=" + key + "&request=search&type=place&page=" + str(page) + "&size=" + str(size) + "&query=" + queryString + "&format=json"
....: url = "http://api.vworld.kr/req/search?" + qStmt
....:
....: resp = requests.get(url)
....: res_json = resp.json()
....: response = res_json['response']
....: itemlist = []
....: if response['status'] == 'OK':
....: items = response['result']['items']
....: for item in items:
....: if item['title'].strip() == queryString:
....: itemlist.append(dict(경찰서=item['title'], 주소=item['address']['road'], 경위도=item['point']))
....: return itemlist
....:
다음과 같이 사용하면 된다.
In [28]: import requests
....: getAddressCoords("본인인증키", "서울강북경찰서")
....:
Out[28]:
[{'경위도': {'x': '127.027356706417', 'y': '37.6374446425296'},
'경찰서': '서울강북경찰서',
'주소': '서울특별시 강북구 오패산로 406'}]
경찰서 소속 자치구 및 경위도¶
위에서 만든 함수를 이용해서 서울시 경찰서가 속한 자치구와 경위도 자료를 만들어 보자.
디비에서 경찰서 이름만 뽑아낸다.
In [29]: import sqlite3
....: conn = sqlite3.connect('./data/seoul.sqlite3')
....: plc_stn = pd.read_sql("SELECT DISTINCT 경찰서 FROM crime", conn)
....: conn.close()
....: plc_stn
....:
Out[33]:
경찰서
0 중부
1 종로
2 남대문
3 서대문
4 혜화
.. ...
26 노원
27 방배
28 은평
29 도봉
30 수서
[31 rows x 1 columns]
지도 검색 사이트에 정확한 질의를 위해서 이름을 수정한다.
In [34]: stn_name = "서울" + plc_stn + "경찰서"
....: stn_name
....:
Out[35]:
경찰서
0 서울중부경찰서
1 서울종로경찰서
2 서울남대문경찰서
3 서울서대문경찰서
4 서울혜화경찰서
.. ...
26 서울노원경찰서
27 서울방배경찰서
28 서울은평경찰서
29 서울도봉경찰서
30 서울수서경찰서
[31 rows x 1 columns]
모든 경찰서에 대해서 주소 및 경위도 리스트는 다음과 같다. 마찬가지로 아래 인증키 부분에 자신의 인증키를 입력한다.
In [36]: res = []
....: for name in stn_name.squeeze():
....: res.extend(getAddressCoords("인증키", name))
....: res
....:
Out[36]:
[{'경위도': {'x': '126.990020918921', 'y': '37.5636320332824'},
'경찰서': '서울중부경찰서',
'주소': '서울특별시 중구 수표로 27'},
{'경위도': {'x': '126.984669638716', 'y': '37.5752966541743'},
'경찰서': '서울종로경찰서',
'주소': '서울특별시 종로구 율곡로 46'},
{'경위도': {'x': '126.973548995951', 'y': '37.5548113303817'},
'경찰서': '서울남대문경찰서',
'주소': '서울특별시 중구 남대문로5가 한강대로 410'},
{'경위도': {'x': '126.967010318625', 'y': '37.5646882605718'},
'경찰서': '서울서대문경찰서',
'주소': '서울특별시 서대문구 통일로 113'},
{'경위도': {'x': '126.998912193137', 'y': '37.5718852513784'},
'경찰서': '서울혜화경찰서',
'주소': '서울특별시 종로구 창경궁로 112-16'},
{'경위도': {'x': '126.966858988641', 'y': '37.5409370273683'},
'경찰서': '서울용산경찰서',
'주소': '서울특별시 용산구 원효로89길 24'},
{'경위도': {'x': '127.016215814566', 'y': '37.5899801887989'},
'경찰서': '서울성북경찰서',
'주소': '서울특별시 성북구 보문로 170'},
{'경위도': {'x': '127.045794546032', 'y': '37.5851575211424'},
'경찰서': '서울동대문경찰서',
'주소': '서울특별시 동대문구 약령시로21길 29'},
{'경위도': {'x': '126.953979398128', 'y': '37.5508321344531'},
'경찰서': '서울마포경찰서',
'주소': '서울특별시 마포구 마포대로 183'},
{'경위도': {'x': '126.901006328686', 'y': '37.5259558027604'},
'경찰서': '서울영등포경찰서',
'주소': '서울특별시 영등포구 국회대로 608 영등포경찰서'},
{'경위도': {'x': '127.036377645509', 'y': '37.5617654993203'},
'경찰서': '서울성동경찰서',
'주소': '서울특별시 성동구 왕십리광장로 9'},
{'경위도': {'x': '126.942813709977', 'y': '37.5131633261019'},
'경찰서': '서울동작경찰서',
'주소': '서울특별시 동작구 노량진로 148'},
{'경위도': {'x': '127.079268260508', 'y': '37.5458138364559'},
'경찰서': '서울광진경찰서',
'주소': '서울특별시 광진구 광나루로 447'},
{'경위도': {'x': '126.921268264495', 'y': '37.6021987191145'},
'경찰서': '서울서부경찰서',
'주소': '서울특별시 은평구 은평로9길 15'},
{'경위도': {'x': '127.027356706417', 'y': '37.6374446425296'},
'경찰서': '서울강북경찰서',
'주소': '서울특별시 강북구 오패산로 406'},
{'경위도': {'x': '126.90997796841', 'y': '37.481417602623'},
'경찰서': '서울금천경찰서',
'주소': '서울특별시 관악구 남부순환로 1435'},
{'경위도': {'x': '127.104468066862', 'y': '37.6182542869542'},
'경찰서': '서울중랑경찰서',
'주소': '서울특별시 중랑구 신내역로3길 40-10'},
{'경위도': {'x': '127.067194351542', 'y': '37.5090497296493'},
'경찰서': '서울강남경찰서',
'주소': '서울특별시 강남구 테헤란로113길 12'},
{'경위도': {'x': '126.950979422302', 'y': '37.4743761890679'},
'경찰서': '서울관악경찰서',
'주소': '서울특별시 관악구 관악로5길 33'},
{'경위도': {'x': '126.850605671634', 'y': '37.551287755715'},
'경찰서': '서울강서경찰서',
'주소': '서울특별시 강서구 화곡로 308'},
{'경위도': {'x': '127.127014346882', 'y': '37.5286751523262'},
'경찰서': '서울강동경찰서',
'주소': '서울특별시 강동구 성내로13길 12'},
{'경위도': {'x': '127.03221766715', 'y': '37.6017154977445'},
'경찰서': '서울종암경찰서',
'주소': '서울특별시 성북구 종암로 135'},
{'경위도': {'x': '126.886723746883', 'y': '37.494790994579'},
'경찰서': '서울구로경찰서',
'주소': '서울특별시 구로구 가마산로 235'},
{'경위도': {'x': '127.005161641666', 'y': '37.4957431981887'},
'경찰서': '서울서초경찰서',
'주소': '서울특별시 서초구 반포대로 179'},
{'경위도': {'x': '126.865594675255', 'y': '37.5166761915281'},
'경찰서': '서울양천경찰서',
'주소': '서울특별시 양천구 목동동로 99'},
{'경위도': {'x': '127.127006491873', 'y': '37.5020022551097'},
'경찰서': '서울송파경찰서',
'주소': '서울특별시 송파구 중대로 221 송파경찰서'},
{'경위도': {'x': '127.071268346957', 'y': '37.6423087554946'},
'경찰서': '서울노원경찰서',
'주소': '서울특별시 노원구 노원로 283 노원경찰서'},
{'경위도': {'x': '126.982996672093', 'y': '37.481568037107'},
'경찰서': '서울방배경찰서',
'주소': '서울특별시 서초구 방배천로 54'},
{'경위도': {'x': '126.928154701241', 'y': '37.6285962717838'},
'경찰서': '서울은평경찰서',
'주소': '서울특별시 은평구 연서로 365'},
{'경위도': {'x': '127.052640617791', 'y': '37.6537663696334'},
'경찰서': '서울도봉경찰서',
'주소': '서울특별시 도봉구 노해로 403'},
{'경위도': {'x': '127.077143894471', 'y': '37.4935487332215'},
'경찰서': '서울수서경찰서',
'주소': '서울특별시 강남구 개포로 617'}]
데이터프레임으로 변경하자.
In [37]: stn_info = pd.DataFrame(res)
주소에서 구를 추출하여 자치구 열을 추가하자.
In [38]: stn_info['자치구'] = stn_info.주소.str.extract(r'\s(.*구)')
자료를 합치기 전에 이름을 변경하자.
In [39]: stn_info.rename(columns={'경찰서': '검색명'}, inplace=True)
자료를 합치자.
In [40]: police = pd.concat([plc_stn, stn_info], axis=1)
디비 저장¶
디비에 저장하기 위해 자료를 손질한다. 경위도를 경도와 위도로 분리해서 저장하자. 디비에 사전형으로는 저장할 수 없기 때문이다.
In [41]: police['경도'] = police.경위도.map(lambda x: x['x']).astype('float')
....: police['위도'] = police.경위도.map(lambda x: x['y']).astype('float')
....:
경위도 열을 제거하자.
In [43]: police.drop(columns='경위도', inplace=True)
....: police
....:
Out[44]:
경찰서 검색명 주소 자치구 경도 위도
0 중부 서울중부경찰서 서울특별시 중구 수표로 27 중구 126.990021 37.563632
1 종로 서울종로경찰서 서울특별시 종로구 율곡로 46 종로구 126.984670 37.575297
2 남대문 서울남대문경찰서 서울특별시 중구 남대문로5가 한강대로 410 중구 126.973549 37.554811
3 서대문 서울서대문경찰서 서울특별시 서대문구 통일로 113 서대문구 126.967010 37.564688
4 혜화 서울혜화경찰서 서울특별시 종로구 창경궁로 112-16 종로구 126.998912 37.571885
.. ... ... ... ... ... ...
26 노원 서울노원경찰서 서울특별시 노원구 노원로 283 노원경찰서 노원구 127.071268 37.642309
27 방배 서울방배경찰서 서울특별시 서초구 방배천로 54 서초구 126.982997 37.481568
28 은평 서울은평경찰서 서울특별시 은평구 연서로 365 은평구 126.928155 37.628596
29 도봉 서울도봉경찰서 서울특별시 도봉구 노해로 403 도봉구 127.052641 37.653766
30 수서 서울수서경찰서 서울특별시 강남구 개포로 617 강남구 127.077144 37.493549
[31 rows x 6 columns]
경찰서 관할구 중 누락된 구가 없는지를 살펴보자. 우선 인구 테이블에 있는 자치구를 불러와서 관할구와 비교해본다.
In [45]: conn = sqlite3.connect('./data/seoul.sqlite3')
....: gu = pd.read_sql("SELECT DISTINCT 자치구 FROM pop", conn)
....:
np.setdiff1d 함수를 이용해서 두 배열들의 집합차를 살펴보자.
In [47]: np.setdiff1d(gu.squeeze().unique(), police.자치구.unique())
Out[47]: array(['금천구'], dtype=object)
금천구가 누락된 것을 알 수 있다. 금천경찰서를 살펴보면 주소지가 관악구로 되어있는 것을 알 수 있다. 하지만 관할구역은 금천구이므로 금천구로 자치구를 변경하자.
In [48]: police.loc[police.경찰서 == '금천', '자치구'] = "금천구"
....: police.자치구
....:
Out[49]:
0 중구
1 종로구
2 중구
3 서대문구
4 종로구
...
26 노원구
27 서초구
28 은평구
29 도봉구
30 강남구
Name: 자치구, Length: 31, dtype: object
자치구별 관할 경찰서를 살펴보자.
In [50]: police.set_index(['자치구', '경찰서']).sort_index()['검색명']
Out[50]:
자치구 경찰서
강남구 강남 서울강남경찰서
수서 서울수서경찰서
강동구 강동 서울강동경찰서
강북구 강북 서울강북경찰서
강서구 강서 서울강서경찰서
...
종로구 종로 서울종로경찰서
혜화 서울혜화경찰서
중구 남대문 서울남대문경찰서
중부 서울중부경찰서
중랑구 중랑 서울중랑경찰서
Name: 검색명, Length: 31, dtype: object
갯수를 세보자.
In [51]: police.pivot_table(index='자치구', values='검색명', aggfunc=lambda x: x.count()).sort_values('검색명', ascending=False)
Out[51]:
검색명
자치구
강남구 2
중구 2
종로구 2
은평구 2
성북구 2
.. ...
광진구 1
관악구 1
강서구 1
강북구 1
중랑구 1
[25 rows x 1 columns]
디비에 저장하자.
In [52]: conn = sqlite3.connect('./data/seoul.sqlite3')
....: police.to_sql('police_station', conn)
....: conn.close()
....:
TODO: 범죄 현황 그래프
지역 경계¶
지역 경계 지도를 이용해서 지도에 표시한다. 지역 경계 정보는 브이월드 또는 통계지리정보서비스를 통해서 얻을 수 있다. 여기서는 브이월드 API를 이용해본다.
법정동 코드¶
지역 경계 지도를 구하기 위해서는 법정동 코드가 필요하다.
정부 행정표준코드관리시스템에 접속한 후 코드 검색 > 자주 찾는 코드에서 법정동을 선택하여 법정동 코드 전체 자료를 다운받아 data 폴더에 저장한다.
압축을 해제한다. 압축 파일 이름이 한글로 되어 있고 인코딩이 utf-8이 아니어서 깨져 보인다. 따라서 파일 이름을 다음과 같이 변경한다.
In [53]: import zipfile
....: import os
....: zipref = zipfile.ZipFile('./data/법정동코드 전체자료.zip', 'r')
....: for fname in zipref.namelist():
....: zipref.extract(fname, './data')
....: os.rename('./data/' + fname, './data/' + fname.encode('cp437').decode('cp949'))
....:
파일을 읽어 들인다.
In [54]: df = pd.read_csv('./data/법정동코드 전체자료.txt', sep='\t', dtype={'법정동코드': str}, engine
....: ='python')
....:
폐지된 코드를 제거한다.
In [55]: df = df[df.폐지여부.str.contains('존재')]
폐지여부 열을 제거하자.
In [56]: df.drop(columns='폐지여부', inplace=True)
법정동을 시도/시군구/읍면동/리 별로 구분을 하자. 모든 구획 열의 값을 리로 설정한다.
In [57]: df['구획'] = '리'
법정동은 처음 2자리는 시도, 다음 3자리는 시군구, 다음 3자리는 읍면동, 마지막 2자리는 리를 나타낸다. 따라서 마지막 2자리가 모두 0인 코드는 읍면동 이상이다. 즉, 읍면동, 시군구, 시도가 될 수 있다.
In [58]: df['구획'][df.법정동코드.str.match(r'\d{8}0{2}')] = '읍면동'
마지막 5자리가 모두 0이면 시군구 이상이다.
In [59]: df['구획'][df.법정동코드.str.match(r'\d{5}0{5}')] = '시군구'
뒤 8자리가 모두 0이면 시도를 나타내는 것이고 세종특별자치시는 예외적으로 3611000000이다.
In [60]: df['구획'][df.법정동코드.str.match(r'\d{2}0{8}|36110{6}')] = '시도'
읍면동 구획의 법정동명의 끝 문자를 살펴보자.
In [61]: df[df.구획.str.match(r'읍면동')]['법정동명'].map(lambda x: re.search(r'.*(.)$', x)[1]).unique(
....: )
....:
Out[61]: array(['동', '로', '가', '읍', '면', ' '], dtype=object)
끝 문자중 공백문자가 있는 것을 알 수 있다. 이것을 제거하자.
In [62]: df.법정동명 = df.법정동명.str.strip()
....: df[df.구획.str.match(r'읍면동')]['법정동명'].map(lambda x: re.search(r'.*(.)$', x)[1]).unique(
....: )
....:
Out[63]: array(['동', '로', '가', '읍', '면'], dtype=object)
디비에 저장하자.
In [64]: conn = sqlite3.connect('./data/seoul.sqlite3')
....: df.to_sql('legal_dong', conn)
....: conn.close()
....:
지역 경계 획득¶
브이월드 API를 이용해서 법정동 코드를 사용해 지역 경계 정보를 얻어 온다. 브이월드 서비스 중 데이터 API 레퍼런스를 이용해서 지역 경계 정보를 얻어 올 수 있다. 4개의 서비스로 구분해서 질의를 할 수 있다. 기본 url은 다음과 같다.:
http://api.vworld.kr/req/data?service=data&request=GetFeature&
시도는 data 값에 LT_C_ADSIDO_INFO, 시군구는 LT_C_ADSIGG_INFO, 읍면동은 LT_C_ADEMD_INFO, 리는 LT_C_ADRI_INFO를 대입하면 된다. domain 값에는 인증할 때 입력한 도메인 주소를 적어 주어야 한다. key에는 본인 인증키 값을 넣어 주고 attrFilter값에 속성명과 연산자 속성값을 콜론으로 구분해서 대입한다. 더 자세한 사항들은 웹페이지를 참조한다.
읍면동 경계¶
읍면동 지역 경계를 얻기 위해서는 data=LT_C_ADEMD_INFO을 사용하고 attrFilter=emd_cd 또는 attrFilter=emd_kor_nm을 이용한다. emd_cd는 법정동 코드이고 emd_kor_nm은 법정동 이름이다.
예를 들어 속성명이 emd_cd``(읍면동 법정코드)이고 천안시 신부동(법정 코드명은 ``44131118)을 검색한다면 attrFilter는 다음과 같이 설정 한다.
attrFilter=emd_cd:=:44131118
또는 이름으로 검색을 하고 싶으면 다음과 같이 한다.
attrFilter=emd_kor_nm:=:신부동
충남 천안시 신부동을 법정동 코드를 이용하여 검색하려면 다음과 같다. 여기서 key와 domain 값을 본인의 키와 도메인 이름으로 대입하는 것을 잊지 말자.
In [65]: import requests
....: url = "http://api.vworld.kr/req/data?service=data&request=GetFeature&data=LT_C_ADEMD_INFO&key=본인인증키&domain=인증시입력한도메인&attrFilter=emd_cd:=:44131118"
....: res = requests.get(url)
....: res.json()
....:
Out[39]
{'response': {'page': {'current': '1', 'size': '10', 'total': '1'}
'record': {'current': '1', 'total': '1'}
'result': {'featureCollection': {'bbox': [127.14905068928854
36.813623388526494
127.17636925005063
36.83769590850596]
'features': [{'geometry': {'coordinates': [[[[127.17522234436002
36.82270325471661]
[127.17517087238659, 36.822488660509]
[127.17508430881621, 36.82217545589959]
... 중간 생략 ...
[127.17479339720188, 36.82379635782791]
[127.17513122120647, 36.822917147077035]
[127.17522234436002, 36.82270325471661]]]]
'type': 'MultiPolygon'}
'id': 'LT_C_ADEMD_INFO.28013'
'properties': {'emd_cd': '44131118'
'emd_eng_nm': 'Sinbu-dong'
'emd_kor_nm': '신부동'
'full_nm': '충청남도 천안시동남구 신부동'}
'type': 'Feature'}]
'type': 'FeatureCollection'}}
'service': {'name': 'data'
'operation': 'GetFeature'
'time': '29(ms)'
'version': '2.0'}
'status': 'OK'}}
서울시 자치구 경계¶
서울특별시 자치구들에 대한 경계를 얻어와서 디비에 저장하자.
법정동 테이블에서 서울시 자치구만 뽑아내자.
In [66]: import sqlite3
....: conn = sqlite3.connect('./data/seoul.sqlite3')
....: seoul = conn.execute("select 법정동코드, 법정동명 from legal_dong where 법정동명 like '%서울%' and \
....: 구획 = '시군구'").fetchall()
....: conn.close()
....:
각 자치구의 지역 경계 정보를 가져와서 사전형으로 저장한다.
In [70]: dfs = {}
....: url = "http://api.vworld.kr/req/data?service=data&request=GetFeature&data=LT_C_ADSIGG_INFO&key=본인인증키&domain=인증시입력한도메인&attrFilter=full_nm:=:{gu}"
....: for code, fullname in seoul:
....: gu = re.sub(r".*\s(.*)", r"\1", fullname)
....: dfs[gu] = requests.get(url.format(gu=fullname)).json()
....:
필요한 정보만 뽑아서 JSON 문자열로 저장한다.
In [71]: import json
....: for gu, geoinfo in dfs.items():
....: dfs[gu] = json.dumps(geoinfo['response']['result']['featureCollection'])
....:
시리즈 형식으로 변형 후 데이터프레임으로 변형한다.
In [72]: geo = pd.Series(dfs).reset_index()
....: geo.columns = ['자치구', 'geojson']
....:
디비에 저장하자.
In [74]: conn = sqlite3.connect('./data/seoul.sqlite3')
....: geo.to_sql('geoinfo', conn)
....: conn.close()
....:
Folium 이용 지도 표시¶
Folium 은 Open Street Map과 같은 지도데이터에 Leaflet.js를 이용하여 위치정보를 시각화하기 위한 라이브러리다. 기본적으로 GeoJSON 형식 또는 topoJSON 형식으로 데이터를 지정하면, 오버레이를 통해 마커의 형태로 위치 정보를 지도상에 표현할 수 있다.
folium 설치¶
In [75]: conda install folium -c conda-forge
폴리움 사용은 location에 위도, 경도를 지정함으로 지도의 가운데 위치를 설정한다. 다음은 서울시 중구를 지도의 중앙에 위치시킨 것이다.
In [76]: import folium
....: m = folium.Map(location=(37.557939871241885, 126.99417336148036), zoom_start=13,)
....: m
....:
다음은 디비에서 종로구 경계 정보를 가져와 폴리움을 이용해서 지도에 표시하는 예이다.
In [78]: import sqlite3
....: import json
....: conn = sqlite3.connect('./data/seoul.sqlite3')
....: jongro = pd.read_sql('select geojson from geoinfo where 자치구 = "종로구"', conn)
....: conn.close()
....: jongro_geo = json.loads(jongro.geojson[0])
....: (lon, lat) = ((jongro_geo['bbox'][0] + jongro_geo['bbox'][2]) / 2, (jongro_geo['bbox'][1] + jongro_geo['bbox'][3]) / 2 )
....: m.location = (lat, lon)
....: m.zoom_start = 12
....: folium.GeoJson(jongro_geo, name='geojson').add_to(m)
....: m
....:
2015년 자료 분석¶
2015년도 자료를 분석해 보자.
2015년 범죄 자료와 경찰서 자료를 받아 온다. 각 자치구별로 분석을 원하기 때문에 경찰서 자료에 있는 자치구 정보가 필요하다.
In [80]: import sqlite3
....: conn = sqlite3.connect('./data/seoul.sqlite3')
....: crime = pd.read_sql("select * from crime where 연도 = 2015", conn)
....: stn = pd.read_sql("select 경찰서, 자치구 from police_station", conn)
....: conn.close()
....:
두 자료를 합치자.
In [85]: df = crime.merge(stn, on='경찰서')
pivot_table을 이용해서 자치구별로 합산을 계산한다.
In [86]: dfp = df.pivot_table(index=['자치구'], columns=['발생검거', '죄종'], values='건수', \
....: aggfunc=np.sum)
....: dfp
....:
Out[87]:
발생검거 검거 발생
죄종 강간 강도 살인 절도 폭력 강간 강도 살인 절도 폭력
자치구
강남구 349 18 10 1650 3705 449 21 13 3850 4284
강동구 123 8 3 789 2248 156 6 4 2366 2712
강북구 126 13 8 618 2348 153 14 7 1434 2649
강서구 191 13 8 1260 2718 262 13 7 2096 3207
관악구 221 14 8 827 2642 320 12 9 2706 3298
.. ... .. .. ... ... ... .. .. ... ...
용산구 173 14 5 587 1704 194 14 5 1557 2050
은평구 141 6 3 711 2306 166 9 3 1914 2653
종로구 161 9 5 837 1931 211 11 6 2184 2293
중구 111 6 2 859 1964 170 9 3 2548 2224
중랑구 148 9 12 829 2407 187 11 13 2135 2847
[25 rows x 10 columns]
검거율을 계산하자.
In [88]: arrest = dfp['검거'] / dfp['발생'] * 100
....: arrest
....:
Out[89]:
죄종 강간 강도 살인 절도 폭력
자치구
강남구 77.728285 85.714286 76.923077 42.857143 86.484594
강동구 78.846154 133.333333 75.000000 33.347422 82.890855
강북구 82.352941 92.857143 114.285714 43.096234 88.637222
강서구 72.900763 100.000000 114.285714 60.114504 84.752105
관악구 69.062500 116.666667 88.888889 30.561715 80.109157
.. ... ... ... ... ...
용산구 89.175258 100.000000 100.000000 37.700706 83.121951
은평구 84.939759 66.666667 100.000000 37.147335 86.920467
종로구 76.303318 81.818182 83.333333 38.324176 84.212822
중구 65.294118 66.666667 66.666667 33.712716 88.309353
중랑구 79.144385 81.818182 92.307692 38.829040 84.545135
[25 rows x 5 columns]
검거율이 100이 넘는 것도 보인다. 100으로 맞춘다.
In [90]: arrest[arrest > 100] = 100
범죄 발생 건수를 최대, 최소 스케일링을 해서 각 열마다 0부터 1사이의 값으로 변경하자.
In [91]: scaled = dfp - dfp.min()
....: scaled /= scaled.max()
....: scaled
....:
Out[93]:
발생검거 검거 발생
죄종 강간 강도 살인 절도 폭력 강간 강도 살인 절도 폭력
자치구
강남구 1.000000 0.652174 0.8 1.000000 1.000000 1.000000 0.941176 0.916667 1.000000 1.000000
강동구 0.073770 0.217391 0.1 0.265358 0.393422 0.155620 0.058824 0.166667 0.467528 0.437969
강북구 0.086066 0.434783 0.6 0.119454 0.435054 0.146974 0.529412 0.416667 0.133118 0.415445
강서구 0.352459 0.434783 0.6 0.667235 0.589092 0.461095 0.470588 0.416667 0.370649 0.614945
관악구 0.475410 0.478261 0.6 0.297782 0.557452 0.628242 0.411765 0.583333 0.589523 0.647479
.. ... ... ... ... ... ... ... ... ... ...
용산구 0.278689 0.478261 0.3 0.093003 0.166944 0.265130 0.529412 0.250000 0.177252 0.201287
은평구 0.147541 0.130435 0.1 0.198805 0.417569 0.184438 0.235294 0.083333 0.305346 0.416875
종로구 0.229508 0.260870 0.3 0.306314 0.261449 0.314121 0.352941 0.333333 0.402225 0.288166
중구 0.024590 0.130435 0.0 0.325085 0.275187 0.195965 0.235294 0.083333 0.532831 0.263497
중랑구 0.176230 0.260870 1.0 0.299488 0.459617 0.244957 0.352941 0.916667 0.384643 0.486235
[25 rows x 10 columns]
인덱스를 다중으로 변경하자.
In [94]: midx = pd.MultiIndex.from_product([['검거율'], arrest.columns.values])
....: arrest.columns = midx
....:
발생 건수에 대한 스케일링과 검거율을 합치자.
In [96]: pd.concat([scaled[['발생']], arrest], axis=1)
Out[96]:
발생검거 발생 검거율
죄종 강간 강도 살인 절도 폭력 강간 강도 살인 절도 폭력
자치구
강남구 1.000000 0.941176 0.916667 1.000000 1.000000 77.728285 85.714286 76.923077 42.857143 86.484594
강동구 0.155620 0.058824 0.166667 0.467528 0.437969 78.846154 100.000000 75.000000 33.347422 82.890855
강북구 0.146974 0.529412 0.416667 0.133118 0.415445 82.352941 92.857143 100.000000 43.096234 88.637222
강서구 0.461095 0.470588 0.416667 0.370649 0.614945 72.900763 100.000000 100.000000 60.114504 84.752105
관악구 0.628242 0.411765 0.583333 0.589523 0.647479 69.062500 100.000000 88.888889 30.561715 80.109157
.. ... ... ... ... ... ... ... ... ... ...
용산구 0.265130 0.529412 0.250000 0.177252 0.201287 89.175258 100.000000 100.000000 37.700706 83.121951
은평구 0.184438 0.235294 0.083333 0.305346 0.416875 84.939759 66.666667 100.000000 37.147335 86.920467
종로구 0.314121 0.352941 0.333333 0.402225 0.288166 76.303318 81.818182 83.333333 38.324176 84.212822
중구 0.195965 0.235294 0.083333 0.532831 0.263497 65.294118 66.666667 66.666667 33.712716 88.309353
중랑구 0.244957 0.352941 0.916667 0.384643 0.486235 79.144385 81.818182 92.307692 38.829040 84.545135
[25 rows x 10 columns]
heatmap을 이용해서 검거율 상황을 살펴보자. 정렬을 위해 임시로 order 열을 하나 만들자.
In [97]: arrest['order'] = arrest.sum(axis=1)
seaborn을 이용해서 heatmap을 그리자.
In [98]: from matplotlib import font_manager, rc
....: font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
....: rc('font', family=font_name)
....: import seaborn as sns
....: ax = sns.heatmap(arrest.sort_values('order', ascending=False).iloc[:, :5], annot=True, fmt='.2f')
....: ax.set_xlabel('')
....: ax.set_title('범죄 검거 비율')
....: ax.figure.tight_layout()
....:
Out[103]: Text(0.5,27.4219,'')
Out[104]: Text(0.5,1,'범죄 검거 비율')
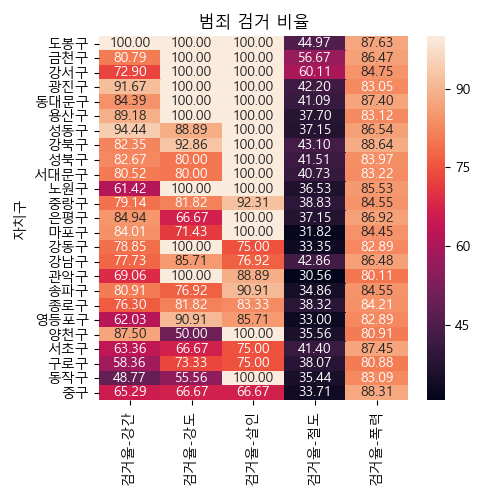
정규화된 발생 건수에 대한 히트맵을 그려보자.
In [106]: nrm = scaled['발생']
.....: nrm['order'] = nrm.sum(axis=1)
.....: ax.figure.clear()
.....: ax = sns.heatmap(nrm.sort_values('order', ascending=False).iloc[:, :5], annot=True, fmt='.2f')
.....: ax.set_title('범죄 비율')
.....: ax.figure.tight_layout()
.....:
Out[110]: Text(0.5,1,'범죄 비율')
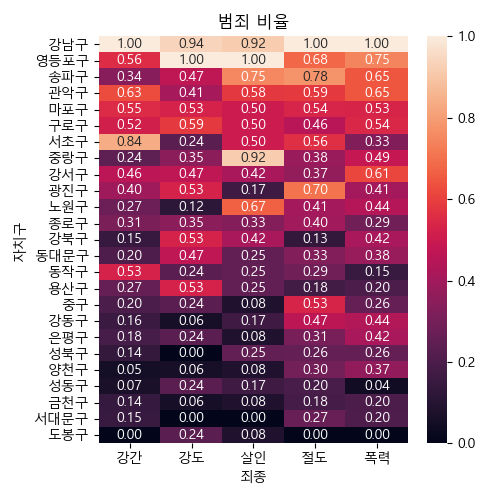
자료 지도 표시¶
폴리움을 이용해서 각 자치구별 자료를 지도에 표시한다.
디비에 있는 서울시 모든 자치구 경계 자료를 가져온다.
In [112]: conn = sqlite3.connect('./data/seoul.sqlite3')
.....: cur = conn.cursor()
.....: geo = cur.execute("SELECT geojson from geoinfo").fetchall()
.....:
자치구 경계를 하나로 합친다.
In [115]: import json
.....: seoul_geo = None
.....: for item, in geo:
.....: gu = json.loads(item)
.....: if seoul_geo == None:
.....: seoul_geo = gu
.....: else:
.....: seoul_geo['features'].extend(gu['features'])
.....:
서울시 모든 구의 경계 지도이다.
In [118]: import folium
.....: choro_map = folium.Map(location=(37.557939871241885, 126.99417336148036), zoom_start=11,)
.....: choro_map.choropleth(geo_data=seoul_geo)
.....:
범죄 발생 건수로 지도에 표시하자.
In [120]: crime_occurence = dfp['발생'].reset_index()
.....: crime_occurence.head()
.....:
Out[121]:
죄종 자치구 강간 강도 살인 절도 폭력
0 강남구 449 21 13 3850 4284
1 강동구 156 6 4 2366 2712
2 강북구 153 14 7 1434 2649
3 강서구 262 13 7 2096 3207
4 관악구 320 12 9 2706 3298
2015년 서울시 자치구별 강간 발생 건수이다.
In [122]: choro_map = folium.Map(location=(lat, lon), zoom_start=10)
.....: choro_map.choropleth(geo_data=seoul_geo, \
.....: data=crime_occurence, \
.....: columns=['자치구', '강간'], \
.....: fill_color='YlOrRd', \
.....: key_on='feature.properties.sig_kor_nm', \
.....: name="강간", \
.....: legend_name='2015년 서울시 자치구 강간 발생 건수')
.....: choro_map
.....:
2015년 서울시 자치구별 강간, 살인 발생 건수이다.
In [123]: choro_map.choropleth(geo_data=seoul_geo, \
.....: data=crime_occurence, \
.....: columns=['자치구', '살인'], \
.....: fill_color='YlOrRd', \
.....: key_on='feature.properties.sig_kor_nm', \
.....: name="살인 건수", \
.....: legend_name='2015년 서울시 자치구 살인 발생 건수')
.....: folium.LayerControl().add_to(choro_map)
.....: choro_map
.....:
경찰서 위치를 지도에 표시하자.
경찰서 경위도 정보를 가져온다.
In [124]: conn = sqlite3.connect('./data/seoul.sqlite3')
.....: stn = pd.read_sql("select 경찰서, 자치구, 위도, 경도 from police_station", conn)
.....: conn.close()
.....:
In [127]: map_police = folium.Map(location=(lat, lon), zoom_start=10)
.....: for _, row in stn.iterrows():
.....: folium.Marker(
.....: location=(row['위도'], row['경도']),
.....: popup=row['경찰서']
.....: ).add_to(map_police)
.....: map_police
.....:
강간 검거율을 지도에 표시하자.
검거율 자료에서 0레벨을 삭제하자.
In [128]: arrest.columns = arrest.columns.droplevel(level=0)
.....: arrest
.....:
Out[129]:
강간 강도 살인 절도 폭력
자치구
강남구 77.728285 85.714286 76.923077 42.857143 86.484594 369.707384
강동구 78.846154 100.000000 75.000000 33.347422 82.890855 370.084431
강북구 82.352941 92.857143 100.000000 43.096234 88.637222 406.943540
강서구 72.900763 100.000000 100.000000 60.114504 84.752105 417.767372
관악구 69.062500 100.000000 88.888889 30.561715 80.109157 368.622261
.. ... ... ... ... ... ...
용산구 89.175258 100.000000 100.000000 37.700706 83.121951 409.997915
은평구 84.939759 66.666667 100.000000 37.147335 86.920467 375.674229
종로구 76.303318 81.818182 83.333333 38.324176 84.212822 363.991830
중구 65.294118 66.666667 66.666667 33.712716 88.309353 320.649519
중랑구 79.144385 81.818182 92.307692 38.829040 84.545135 376.644434
[25 rows x 6 columns]
경찰서 위치 정보와 검거율을 합치자.
In [130]: stn_arrest = arrest.merge(stn, on='자치구')
CircleMarker의 반지름의 단위는 픽셀이다.
In [131]: map_stn_arrest = folium.Map(location=(lat, lon), zoom_start=12)
.....: for _, row in stn_arrest.iterrows():
.....: folium.CircleMarker(
.....: location=(row['위도'], row['경도']),
.....: radius=int(row['강간']) / 2,
.....: popup=row['경찰서'],
.....: tooltip=str(int(row['강간']))+'%',
.....: color='#3186cc',
.....: fill=True,
.....: fill_color='#3186cc',
.....: ).add_to(map_stn_arrest)
.....: map_stn_arrest
.....: