서울시 CCTV 및 인구 현황¶
CCTV 현황¶
연도별 서울시 자치구 CCTV 설치 현황 자료는 사이트 https://www.data.go.kr/dataset/3073216/fileData.do에서 다운받을 수 있다. 링크는 변경될 수도 있다. 다운받은 파일은 data 디렉토리에 저장한다.
In [1]: import pandas as pd
...: pd.set_option('max_rows', 10)
...:
In [3]: cctv = pd.read_csv('./data/서울시 자치구 년도별 CCTV 설치 현황.csv', engine='python', encoding='utf-8')
...: cctv
...:
Out[4]:
기관명 소계 2013년도 이전 2014년 2015년 2016년
0 강남구 3238 1292 430 584 932
1 강동구 1010 379 99 155 377
2 강북구 831 369 120 138 204
3 강서구 911 388 258 184 81
4 관악구 2109 846 260 390 613
.. ... ... ... ... ... ...
20 용산구 2096 1368 218 112 398
21 은평구 2108 1138 224 278 468
22 종로구 1619 464 314 211 630
23 중구 1023 413 190 72 348
24 중랑구 916 509 121 177 109
[25 rows x 6 columns]
read_csv 함수가 한글 이름 파일을 부를 때 오류가 나면 위와 같이 engine='python'이라고 적어주고 encoding='utf-8'이라고 적는다. 그런데 가끔씩 헤더가 제대로 나오지 않는 경우가 있는데 이것은 파일 인코딩이 BOM 있음으로 되어 있는 경우 발생할 수 있다. Notepad++ 를 이용해 csv 파일을 열어서 BOM 없음으로 인코딩을 변경하여 저장하고 열면 제대로 열린다.
자료 정보¶
pd.DataFrame.info() 메소드를 이용하여 기본적인 정보를 얻을 수 있다.
In [5]: cctv.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 0 to 24
Data columns (total 6 columns):
기관명 25 non-null object
소계 25 non-null int64
2013년도 이전 25 non-null int64
2014년 25 non-null int64
2015년 25 non-null int64
2016년 25 non-null int64
dtypes: int64(5), object(1)
memory usage: 1.2+ KB
열의 갯수는 6개이고 인덱스의 갯수는 25개 임을 알 수 있다. 즉, 행의 갯수가 25개라는 것이다. 각 열의 정보가 나오는데 non-null의 갯수가 모두 25개씩임을 알 수 있다. 첫번째 열 기관명은 object이고 나머지는 정수형 타입인 것을 알 수 있다. 판다스에서 object 타입은 두 개 이상의 타입이 섞여 있거나 문자열로 이루어진 자료를 나타낸다. 따라서 object로 표시된 자료형은 부차적으로 이상치가 있는지를 확인해야 한다.
pd.unique 함수를 이용해서 object 타입의 열이 어떤 것들로 구성되어 있는지를 확인해보자.
In [6]: pd.unique(cctv.기관명)
Out[6]:
array(['강남구', '강동구', '강북구', '강서구', '관악구', '광진구', '구로구', '금천구', '노원구',
'도봉구', '동대문구', '동작구', '마포구', '서대문구', '서초구', '성동구', '성북구', '송파구',
'양천구', '영등포구', '용산구', '은평구', '종로구', '중구', '중랑구'], dtype=object)
중복되지 않는 것의 갯수를 확인해보자.
In [7]: len(pd.unique(cctv.기관명))
Out[7]: 25
행의 갯수와 같으므로 이상한 것을 발견할 수 없다.
Exercise
- null이 있는 열을 찾아서 null인 값들을 출력하라.
열 제거¶
필요없는 열 소계를 제거하고 매년 더해진 값으로 변경하자. 데이터프레임 drop 메소드는 지정된 열 또는 행 인덱스 이름들을 이용하여 열 또는 행들을 제거할 수 있다.
In [8]: cctv.drop(columns='소계', inplace=True)
...: cctv
...:
Out[9]:
기관명 2013년도 이전 2014년 2015년 2016년
0 강남구 1292 430 584 932
1 강동구 379 99 155 377
2 강북구 369 120 138 204
3 강서구 388 258 184 81
4 관악구 846 260 390 613
.. ... ... ... ... ...
20 용산구 1368 218 112 398
21 은평구 1138 224 278 468
22 종로구 464 314 211 630
23 중구 413 190 72 348
24 중랑구 509 121 177 109
[25 rows x 5 columns]
열 인덱스 이름 변경¶
서울시 인구 자료와 통합하기 위해서 열 인덱스 이름을 변경하자. 열 이름 중에 숫자만 남기고 기관명은 자치구로 변경한다.
In [10]: import re
....: cctv.rename(lambda x: re.sub(r'.*(\d{4}).*', r'\1', x), axis=1, inplace=True)
....: cctv.rename({'기관명': '자치구'}, axis=1, inplace=True)
....: cctv.columns
....:
Out[13]: Index(['자치구', '2013', '2014', '2015', '2016'], dtype='object')
cctv 자료는 매년 설치된 숫자를 나타내므로 누적대수로 변경하자. 자치구를 인덱스로 변경하자.
In [14]: cctv.set_index('자치구', inplace=True)
행에 대해서 누적합을 계산한다.
In [15]: cctv = cctv.cumsum(axis=1)
자치구 열로 복귀한다.
In [16]: cctv.reset_index(inplace=True)
서울시 인구¶
자료 저장¶
서울시 주민등록 인구를 사이트 http://data.seoul.go.kr/dataList/datasetView.do?infId=419&srvType=S&serviceKind=2¤tPageNo=1&searchValue=&searchKey=null에서 다운받는다. 다운받을 때 분기를 2013년 1분기부터 시작하고 파일형식은 xls로 한다. 다운받은 파일을 data 디렉토리에 저장한다.
엑셀을 이용하여 자료를 열어보자. 엑셀이 없으면 리브레오피스를 설치해서 열어볼 수 있다.
자료 읽어 오기¶
엑셀 파일에 여러 행으로 이루어진 헤더가 있을 때는 header 옵션을 지정하여 원하는 행들을 헤더로 읽어올 수 있다.
In [17]: pop = pd.read_excel('data/서울시 주민등록인구 (구별) 통계.xls', header=[0, 1, 2])
In [18]: pop.head()
Out[18]:
기간 자치구 세대 인구 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 합계 한국인 등록외국인 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 계 남자 여자 계 남자 여자 계 남자 여자 인구밀도(명/㎢) 면적(㎢) 세대당인구 65세이상고령자
2013.1/4 합계 4182314 10437737 5155053 5282684 10192057 5037288 5154769 245680 117765 127915 17247 605.2 2.44 1130508
2013.1/4 종로구 74581 170681 84719 85962 162777 81033 81744 7904 3686 4218 7139 23.91 2.18 23853
2013.1/4 중구 61217 140127 70339 69788 132652 66605 66047 7475 3734 3741 14069 9.96 2.17 19100
2013.1/4 용산구 110479 254749 124300 130449 242630 118012 124618 12119 6288 5831 11649 21.87 2.20 33404
2013.1/4 성동구 127035 309312 154328 154984 302038 150875 151163 7274 3453 3821 18353 16.85 2.38 34721
Note
만일 pd.read_excel 함수를 이용해 xls 파일을 읽을 때 헤더가 여러 개인 셀들로 병합되어 있으면 읽는데 에러가 발생할 수도 있다. 우선 pandas의 설치 버전을 확인해 본다. 아나콘다 명령창에서 conda list pandas라고 치면 버전 정보가 나온다. 만일 0.23.4 보다 작으면 최신 버전으로 설치한다. 설치하는 방법은 conda install pandas=0.23.4를 명령창에 입력하면 된다.
자료 정보¶
기본적인 자료 정보를 확인해보자.
In [19]: pop.info()
<class 'pandas.core.frame.DataFrame'>
Index: 572 entries, 2013.1/4 to 2018.2/4
Data columns (total 15 columns):
(자치구, 자치구, 자치구) 572 non-null object
(세대, 세대, 세대) 572 non-null int64
(인구, 합계, 계) 572 non-null int64
(인구, 합계, 남자) 572 non-null int64
(인구, 합계, 여자) 572 non-null int64
(인구, 한국인, 계) 572 non-null int64
(인구, 한국인, 남자) 572 non-null int64
(인구, 한국인, 여자) 572 non-null int64
(인구, 등록외국인, 계) 572 non-null int64
(인구, 등록외국인, 남자) 572 non-null int64
(인구, 등록외국인, 여자) 572 non-null int64
(인구밀도, 인구밀도, 인구밀도(명/㎢)) 572 non-null object
(인구밀도, 인구밀도, 면적(㎢)) 572 non-null object
(세대당인구, 세대당인구, 세대당인구) 572 non-null float64
(65세이상고령자, 65세이상고령자, 65세이상고령자) 572 non-null int64
dtypes: float64(1), int64(11), object(3)
memory usage: 71.5+ KB
행 인덱스의 갯수는 572개이고 열의 갯수는 15개임을 알 수 있다. object 열은 자치구, 인구밀도, 면적이 있고 나머지는 지정된 타입이 있음을 알 수 있다.
지정된 타입의 열만 선택¶
pandas.DataFrame.select_dtypes을 이용하여 원하는 타입의 열들만 골라 낼 수 있다.
In [20]: obj = pop.select_dtypes('object')
null의 갯수를 살펴보자.
In [21]: obj.info()
<class 'pandas.core.frame.DataFrame'>
Index: 572 entries, 2013.1/4 to 2018.2/4
Data columns (total 3 columns):
(자치구, 자치구, 자치구) 572 non-null object
(인구밀도, 인구밀도, 인구밀도(명/㎢)) 572 non-null object
(인구밀도, 인구밀도, 면적(㎢)) 572 non-null object
dtypes: object(3)
memory usage: 17.9+ KB
null의 갯수는 하나도 없는 것을 알 수 있다. 그럼 자치구 열이 이상치가 있는지를 unique 함수를 이용해서 살펴보자.
In [22]: pd.unique(obj['자치구'].squeeze())
Out[22]:
array(['합계', '종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구',
'강북구', '도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구',
'금천구', '영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'],
dtype=object)
여기서 pd.DataFrame.squeeze() 메소드를 사용한 이유는 obj['자치구'] 객체가 데이터프레임이기 때문에 pd.unique 함수를 사용할 수 없어서 squeeze를 이용해서 시리즈로 변형하여 적용한 것이다.
살펴보면 합계 열만 하나 추가되어 있는 것을 알 수 있다. 아래에서 ‘합계’ 행은 모두 제거할 것이다.
다음은 인구밀도 열을 살펴보자. 레벨 2에 있는 인구밀도 이름에는 제곱 킬로미터가 들어가 있어서 텍스트로 표현하기가 까다롭다. 따라서 iloc 접근자를 이용해서 숫자로 접근하자. 또한 apply 메소드를 이용해서 각 성분의 type을 알아내어 몇 가지 타입으로 이루어졌는지를 확인하자.
In [23]: pd.unique(obj.iloc[:, 1].apply(type))
Out[23]: array([<class 'int'>, <class 'str'>], dtype=object)
정수형과 문자열형으로 이루어진 것을 알 수 있다. 문자열 형으로 이루어진 자료들의 형태를 알아보자.
In [24]: pd.unique(obj.iloc[:, 1][obj.iloc[:, 1].apply(lambda x: type(x) == str)])
Out[24]: array(['-'], dtype=object)
즉 - 하나밖에 없는 것을 알 수 있다. 마찬가지로 면적 열에 대해서 살펴보자.
In [25]: pd.unique(obj.iloc[:, 2].apply(type))
....: pd.unique(obj.iloc[:, 2][obj.iloc[:, 2].apply(lambda x: type(x) == str)])
....:
Out[25]: array([<class 'float'>, <class 'int'>, <class 'str'>], dtype=object)
Out[26]: array(['-'], dtype=object)
기간을 시간 객체화¶
인덱스를 판다스 Period 인덱스로 변환하자. Period 객체는 시간을 기간으로 표시한다. Period(freq='Q', year=2018, quarter=1) 형식을 사용하면 2018년 1분기 기간을 의미한다. 즉, 2018년 1월 1일부터 3월 31일까지 기간을 표현한다.
우선 pop 인덱스를 정규표현식을 이용하여 원하는 부분을 골라내어 처리하도록 하자.
In [27]: import re
....: regex = re.compile(r'(\d{4}).(\d)')
....:
In [29]: pop.index = pop.index.map(lambda x: pd.Period(freq='Q', year=int(regex.match(x)[1]),
....: quarter=int(regex.match(x)[2])))
....: pop.index
....:
Out[29]:
PeriodIndex(['2013Q1', '2013Q1', '2013Q1', '2013Q1', '2013Q1', '2013Q1',
'2013Q1', '2013Q1', '2013Q1', '2013Q1',
...
'2018Q2', '2018Q2', '2018Q2', '2018Q2', '2018Q2', '2018Q2',
'2018Q2', '2018Q2', '2018Q2', '2018Q2'],
dtype='period[Q-DEC]', length=572, freq='Q-DEC')
원하는 인덱스는 다음과 같이 선택할 수 있다.
2018년 1분기를 선택하려면 다음과 같이 한다.
In [30]: pop.loc['2018Q1']
Out[30]:
기간 자치구 세대 인구 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 합계 한국인 등록외국인 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 계 남자 여자 계 남자 여자 계 남자 여자 인구밀도(명/㎢) 면적(㎢) 세대당인구 65세이상고령자
2018Q1 합계 4237610 10112070 4948481 5163589 9838892 4817507 5021385 273178 130974 142204 - - 2.32 1382420
2018Q1 종로구 73879 164348 79962 84386 154549 75749 78800 9799 4213 5586 - - 2.09 26429
2018Q1 중구 60903 135139 66582 68557 126082 62376 63706 9057 4206 4851 - - 2.07 21655
2018Q1 용산구 108497 245411 119985 125426 229909 111262 118647 15502 8723 6779 - - 2.12 37238
2018Q1 성동구 134543 314551 154672 159879 306532 150937 155595 8019 3735 4284 - - 2.28 41752
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
2018Q1 관악구 258536 522292 262428 259864 504445 253911 250534 17847 8517 9330 - - 1.95 70807
2018Q1 서초구 174225 445164 213279 231885 440954 211156 229798 4210 2123 2087 - - 2.53 54055
2018Q1 강남구 231219 557865 267314 290551 552976 264834 288142 4889 2480 2409 - - 2.39 65859
2018Q1 송파구 266550 671994 326511 345483 665282 323228 342054 6712 3283 3429 - - 2.50 77978
2018Q1 강동구 177490 438225 217570 220655 434027 215588 218439 4198 1982 2216 - - 2.45 56983
[26 rows x 15 columns]
2013년도 전체를 선택하려면 다음과 같이 한다. 또는 pop['2013']과 같이 해도 된다.
In [31]: pop.loc['2013Q1':'2013Q4']
Out[31]:
기간 자치구 세대 인구 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 합계 한국인 등록외국인 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 계 남자 여자 계 남자 여자 계 남자 여자 인구밀도(명/㎢) 면적(㎢) 세대당인구 65세이상고령자
2013Q1 합계 4182314 10437737 5155053 5282684 10192057 5037288 5154769 245680 117765 127915 17247 605.2 2.44 1130508
2013Q1 종로구 74581 170681 84719 85962 162777 81033 81744 7904 3686 4218 7139 23.91 2.18 23853
2013Q1 중구 61217 140127 70339 69788 132652 66605 66047 7475 3734 3741 14069 9.96 2.17 19100
2013Q1 용산구 110479 254749 124300 130449 242630 118012 124618 12119 6288 5831 11649 21.87 2.20 33404
2013Q1 성동구 127035 309312 154328 154984 302038 150875 151163 7274 3453 3821 18353 16.85 2.38 34721
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
2013Q4 관악구 248006 535128 270512 264616 518028 262248 255780 17100 8264 8836 18097 29.57 2.09 59705
2013Q4 서초구 170594 446541 215771 230770 441763 213285 228478 4778 2486 2292 9501 47 2.59 44674
2013Q4 강남구 230645 569152 273583 295569 563599 270601 292998 5553 2982 2571 14409 39.5 2.44 53461
2013Q4 송파구 257441 674955 330030 344925 668415 326919 341496 6540 3111 3429 19925 33.87 2.60 61745
2013Q4 강동구 186764 487969 243530 244439 483379 241503 241876 4590 2027 2563 19846 24.59 2.59 47812
[104 rows x 15 columns]
행 인덱스를 데이터프레임의 열로 변경하자.
In [32]: pop.reset_index(col_fill='기간', inplace=True)
....: pop
....:
Out[33]:
기간 index 자치구 세대 인구 인구밀도 세대당인구 65세이상고령자
기간 기간 자치구 세대 합계 한국인 등록외국인 인구밀도 세대당인구 65세이상고령자
기간 기간 자치구 세대 계 남자 여자 계 남자 여자 계 남자 여자 인구밀도(명/㎢) 면적(㎢) 세대당인구 65세이상고령자
0 2013Q1 합계 4182314 10437737 5155053 5282684 10192057 5037288 5154769 245680 117765 127915 17247 605.2 2.44 1130508
1 2013Q1 종로구 74581 170681 84719 85962 162777 81033 81744 7904 3686 4218 7139 23.91 2.18 23853
2 2013Q1 중구 61217 140127 70339 69788 132652 66605 66047 7475 3734 3741 14069 9.96 2.17 19100
3 2013Q1 용산구 110479 254749 124300 130449 242630 118012 124618 12119 6288 5831 11649 21.87 2.20 33404
4 2013Q1 성동구 127035 309312 154328 154984 302038 150875 151163 7274 3453 3821 18353 16.85 2.38 34721
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
567 2018Q2 관악구 259681 521960 262235 259725 504048 253600 250448 17912 8635 9277 - - 1.94 71317
568 2018Q2 서초구 174268 443989 212679 231310 439844 210596 229248 4145 2083 2062 - - 2.52 54614
569 2018Q2 강남구 229160 551888 264332 287556 546952 261815 285137 4936 2517 2419 - - 2.39 66011
570 2018Q2 송파구 268325 673161 327051 346110 666439 323741 342698 6722 3310 3412 - - 2.48 79093
571 2018Q2 강동구 177605 437050 216814 220236 432749 214740 218009 4301 2074 2227 - - 2.44 57680
[572 rows x 16 columns]
0레벨 열 이름을 기간으로 변경하자.
In [34]: pop.rename(columns={'index': '기간'}, inplace=True)
....: pop.head()
....:
Out[35]:
기간 기간 자치구 세대 인구 인구밀도 세대당인구 65세이상고령자
기간 기간 자치구 세대 합계 한국인 등록외국인 인구밀도 세대당인구 65세이상고령자
기간 기간 자치구 세대 계 남자 여자 계 남자 여자 계 남자 여자 인구밀도(명/㎢) 면적(㎢) 세대당인구 65세이상고령자
0 2013Q1 합계 4182314 10437737 5155053 5282684 10192057 5037288 5154769 245680 117765 127915 17247 605.2 2.44 1130508
1 2013Q1 종로구 74581 170681 84719 85962 162777 81033 81744 7904 3686 4218 7139 23.91 2.18 23853
2 2013Q1 중구 61217 140127 70339 69788 132652 66605 66047 7475 3734 3741 14069 9.96 2.17 19100
3 2013Q1 용산구 110479 254749 124300 130449 242630 118012 124618 12119 6288 5831 11649 21.87 2.20 33404
4 2013Q1 성동구 127035 309312 154328 154984 302038 150875 151163 7274 3453 3821 18353 16.85 2.38 34721
열 인덱스의 이름을 없애자.
In [36]: pop.columns.set_names([None, None, None], inplace=True)
....: pop.head()
....:
Out[37]:
기간 자치구 세대 인구 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 합계 한국인 등록외국인 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 계 남자 여자 계 남자 여자 계 남자 여자 인구밀도(명/㎢) 면적(㎢) 세대당인구 65세이상고령자
0 2013Q1 합계 4182314 10437737 5155053 5282684 10192057 5037288 5154769 245680 117765 127915 17247 605.2 2.44 1130508
1 2013Q1 종로구 74581 170681 84719 85962 162777 81033 81744 7904 3686 4218 7139 23.91 2.18 23853
2 2013Q1 중구 61217 140127 70339 69788 132652 66605 66047 7475 3734 3741 14069 9.96 2.17 19100
3 2013Q1 용산구 110479 254749 124300 130449 242630 118012 124618 12119 6288 5831 11649 21.87 2.20 33404
4 2013Q1 성동구 127035 309312 154328 154984 302038 150875 151163 7274 3453 3821 18353 16.85 2.38 34721
합계 행 제거¶
자치구 열중에서 합계 행을 제거하자.
In [38]: pop = pop[pop.loc[:, ('자치구', '자치구', '자치구')] != '합계']
....: pop
....:
Out[39]:
기간 자치구 세대 인구 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 합계 한국인 등록외국인 인구밀도 세대당인구 65세이상고령자
기간 자치구 세대 계 남자 여자 계 남자 여자 계 남자 여자 인구밀도(명/㎢) 면적(㎢) 세대당인구 65세이상고령자
1 2013Q1 종로구 74581 170681 84719 85962 162777 81033 81744 7904 3686 4218 7139 23.91 2.18 23853
2 2013Q1 중구 61217 140127 70339 69788 132652 66605 66047 7475 3734 3741 14069 9.96 2.17 19100
3 2013Q1 용산구 110479 254749 124300 130449 242630 118012 124618 12119 6288 5831 11649 21.87 2.20 33404
4 2013Q1 성동구 127035 309312 154328 154984 302038 150875 151163 7274 3453 3821 18353 16.85 2.38 34721
5 2013Q1 광진구 158987 383806 188983 194823 371170 183297 187873 12636 5686 6950 22494 17.06 2.33 36427
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
567 2018Q2 관악구 259681 521960 262235 259725 504048 253600 250448 17912 8635 9277 - - 1.94 71317
568 2018Q2 서초구 174268 443989 212679 231310 439844 210596 229248 4145 2083 2062 - - 2.52 54614
569 2018Q2 강남구 229160 551888 264332 287556 546952 261815 285137 4936 2517 2419 - - 2.39 66011
570 2018Q2 송파구 268325 673161 327051 346110 666439 323741 342698 6722 3310 3412 - - 2.48 79093
571 2018Q2 강동구 177605 437050 216814 220236 432749 214740 218009 4301 2074 2227 - - 2.44 57680
[550 rows x 16 columns]
또는 drop 메소드를 이용해서 pop.drop(pop[(pop.loc[:, '자치구'] == '합계').squeeze()].index, inplace=True)와 같이 해도 된다.
2013년 1분기 자료 분석¶
2013년도 1분기 자료만 선택하자.
In [40]: idx = pd.IndexSlice
In [41]: pop2013q1 = pop.loc[pop.loc[:, ('기간', '기간', '기간')] == pd.Period('2013Q1'), idx[:, ['자치구', '합계'], ['자치구', '계']]]
....: pop2013q1
....:
Out[42]:
자치구 인구
자치구 합계
자치구 계
1 종로구 170681
2 중구 140127
3 용산구 254749
4 성동구 309312
5 광진구 383806
.. ... ...
21 관악구 540467
22 서초구 442600
23 강남구 568982
24 송파구 676551
25 강동구 491770
[25 rows x 2 columns]
열 인덱스의 1, 2레벨을 제거하자.
In [43]: pop2013q1.columns = pop2013q1.columns.droplevel(level=[1, 2])
....: pop2013q1.head()
....:
Out[44]:
자치구 인구
1 종로구 170681
2 중구 140127
3 용산구 254749
4 성동구 309312
5 광진구 383806
seaborn 패키지를 이용하여 그래프를 그려보자. 한글을 사용할 수 있도록 글씨체를 변경한다.
In [45]: from matplotlib import font_manager, rc
....: font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
....: rc('font', family=font_name)
....:
sns.barplot의 반환값은 matplotlib의 axes 객체이다.
In [48]: import seaborn as sns
....: ax = sns.barplot(data=pop2013q1, x='자치구', y='인구')
....: ax.set_title('서울시 2013년 1분기 인구');
....: ax.set_xticklabels(ax.get_xticklabels(), rotation=70);
....: ax.figure.tight_layout()
....:
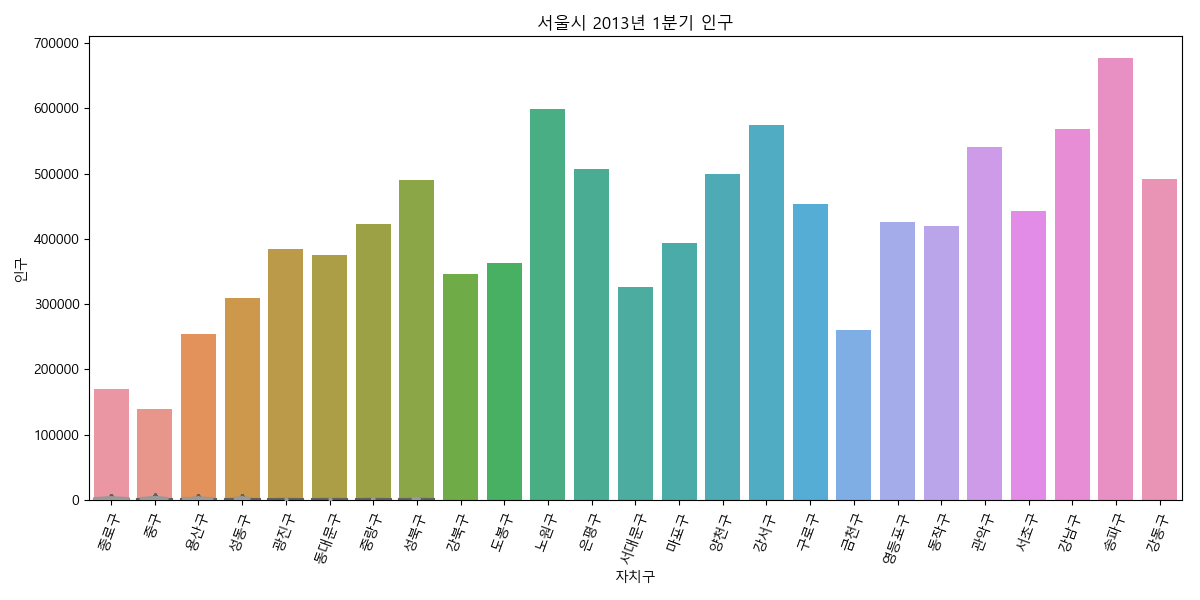
figure.tight_layout 메소드는 불필요한 공간과 필요한 공간들을 계산해서 보여준다.
차례로 정렬해서 보여주자. order 옵션을 이용한다.
In [53]: ax.clear()
....: ax = sns.barplot(x='자치구', y='인구', data=pop2013q1, order=pop2013q1.sort_values('인구')['자치구'])
....: ax.set_title('서울시 2013년 1분기 인구');
....: ax.set_xticklabels(ax.get_xticklabels(), rotation=70);
....: ax.figure.tight_layout()
....:
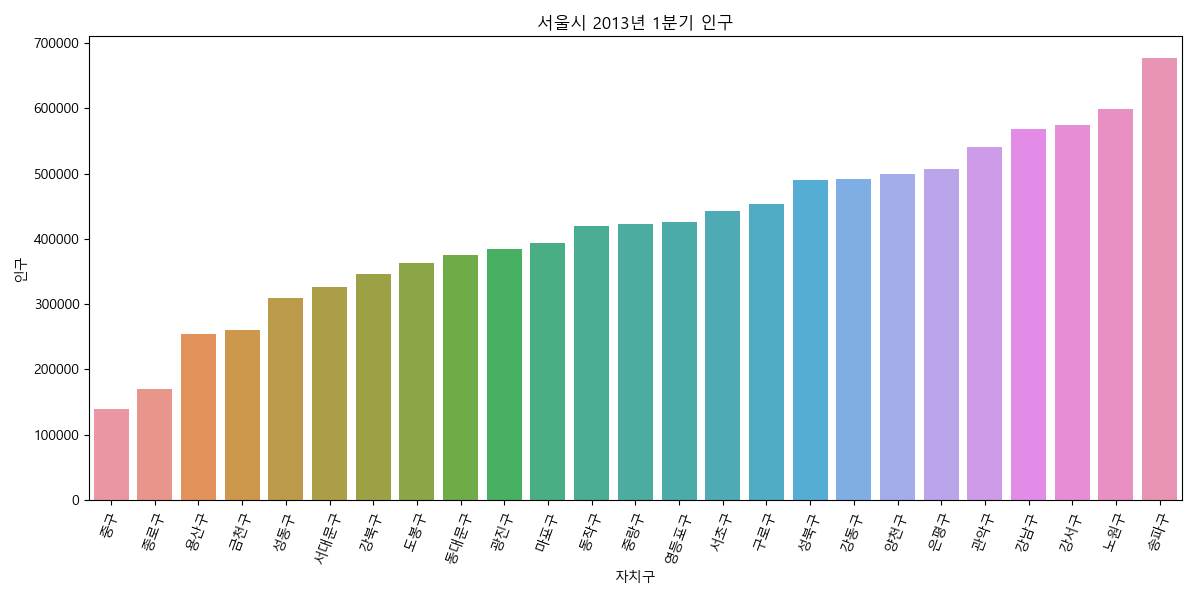
기간, 자치구, 인구, 고령자 열¶
기간, 자치구, 인구, 65세이상고령자만 간추리자.
In [58]: pop1 = pop.loc[:,['기간', '자치구', '인구', '65세이상고령자']]
열 이름 변경¶
열 이름을 변경하자.
In [59]: pop1.rename(columns={'65세이상고령자': '고령자', '등록외국인': '외국인'}, inplace=True)
연도 추가¶
연도 열을 추가하자.
In [60]: pop1[('연도', '연도', '연도')] = pop1[('기간', '기간', '기간')].map(lambda x: x.year)
....: pop1.head()
....:
Out[61]:
기간 자치구 인구 고령자 연도
기간 자치구 합계 한국인 외국인 고령자 연도
기간 자치구 계 남자 여자 계 남자 여자 계 남자 여자 고령자 연도
1 2013Q1 종로구 170681 84719 85962 162777 81033 81744 7904 3686 4218 23853 2013
2 2013Q1 중구 140127 70339 69788 132652 66605 66047 7475 3734 3741 19100 2013
3 2013Q1 용산구 254749 124300 130449 242630 118012 124618 12119 6288 5831 33404 2013
4 2013Q1 성동구 309312 154328 154984 302038 150875 151163 7274 3453 3821 34721 2013
5 2013Q1 광진구 383806 188983 194823 371170 183297 187873 12636 5686 6950 36427 2013
연도별 평균 인구¶
년도별 평균 인구수는 다음과 같다.
In [62]: pyear = pop1.groupby([('연도', '연도', '연도')]).agg('mean')
....: pyear.head()
....:
Out[63]:
인구 고령자
합계 한국인 외국인 고령자
계 남자 여자 계 남자 여자 계 남자 여자 고령자
(연도, 연도, 연도)
2013 416616.23 205667.22 210949.01 406789.53 200934.14 205855.39 9826.70 4733.08 5093.62 45955.58
2014 415250.77 204711.15 210539.62 404968.44 199724.41 205244.03 10282.33 4986.74 5295.59 48095.63
2015 413475.44 203471.00 210004.44 402570.45 198189.44 204381.01 10904.99 5281.56 5623.43 50153.99
2016 409842.58 201274.23 208568.35 398942.90 196046.02 202896.88 10899.68 5228.21 5671.47 51607.68
2017 406589.89 199215.66 207374.23 395902.23 194135.34 201766.89 10687.66 5080.32 5607.34 53792.81
그래프로 그려보자.
In [64]: pyear = pyear.reset_index()
....: ax.clear()
....: ax = sns.pointplot(data=pyear, x=('연도', '연도', '연도'), y=('인구', '합계', '계'))
....: ax.set_title('서울시 연도별 평균 인구')
....: ax.set_xlabel('연도')
....: ax.set_ylabel('인구')
....:
Out[67]: Text(0.5,1,'서울시 연도별 평균 인구')
Out[68]: Text(0.5,28.0781,'연도')
Out[69]: Text(28.0625,0.5,'인구')
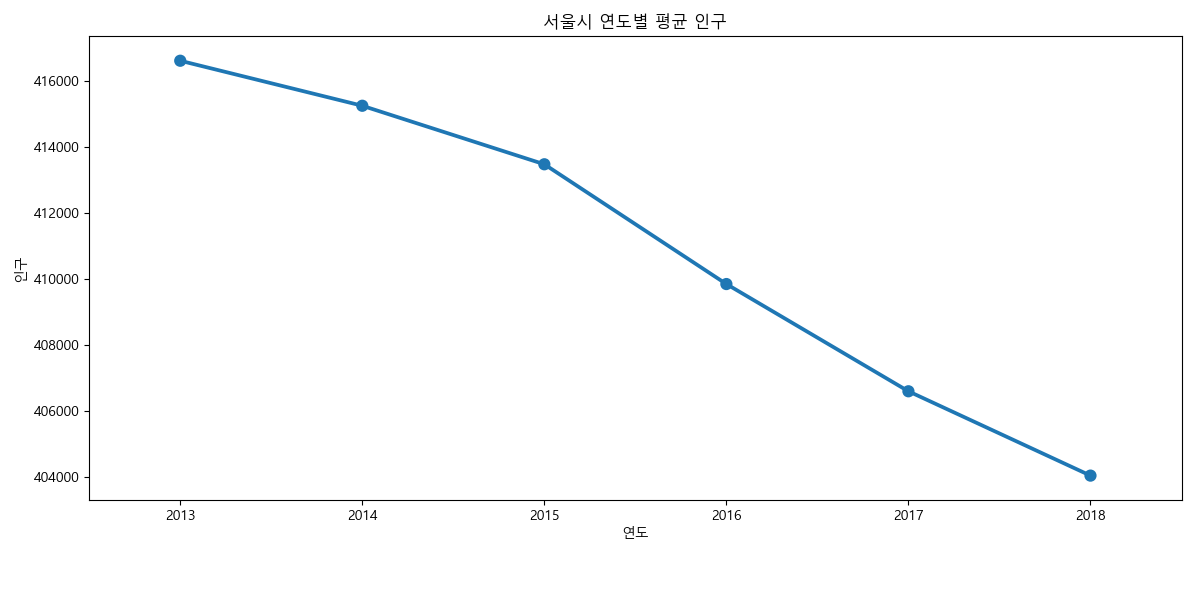
자치구별 평균 인구¶
연도별 자치구별 평균 인구수를 구하자.
In [70]: pop_year_gu = pop1.groupby([('연도', '연도', '연도'), ('자치구', '자치구', '자치구')]).agg('mean')
....: pop_year_gu.head()
....:
Out[71]:
인구 고령자
합계 한국인 외국인 고령자
계 남자 여자 계 남자 여자 계 남자 여자 고령자
(연도, 연도, 연도) (자치구, 자치구, 자치구)
2013 강남구 568740.50 273372.00 295368.50 562984.50 270253.00 292731.50 5756.00 3119.00 2637.00 52363.00
강동구 489935.50 244664.00 245271.50 485206.50 242590.25 242616.25 4729.00 2073.75 2655.25 46857.75
강북구 343989.75 169604.25 174385.50 340749.75 168392.50 172357.25 3240.00 1211.75 2028.25 47696.75
강서구 574508.50 282051.25 292457.25 568303.50 278946.25 289357.25 6205.00 3105.00 3100.00 58282.00
관악구 538154.25 272205.75 265948.50 520870.50 263908.75 256961.75 17283.75 8297.00 8986.75 58694.50
인덱스를 열로 변경하자.
In [72]: yg = pop_year_gu.reset_index()
....: yg.head()
....:
Out[73]:
연도 자치구 인구 고령자
연도 자치구 합계 한국인 외국인 고령자
연도 자치구 계 남자 여자 계 남자 여자 계 남자 여자 고령자
0 2013 강남구 568740.50 273372.00 295368.50 562984.50 270253.00 292731.50 5756.00 3119.00 2637.00 52363.00
1 2013 강동구 489935.50 244664.00 245271.50 485206.50 242590.25 242616.25 4729.00 2073.75 2655.25 46857.75
2 2013 강북구 343989.75 169604.25 174385.50 340749.75 168392.50 172357.25 3240.00 1211.75 2028.25 47696.75
3 2013 강서구 574508.50 282051.25 292457.25 568303.50 278946.25 289357.25 6205.00 3105.00 3100.00 58282.00
4 2013 관악구 538154.25 272205.75 265948.50 520870.50 263908.75 256961.75 17283.75 8297.00 8986.75 58694.50
그래프를 그려보자.
In [74]: sns.relplot(x=('연도', '연도', '연도'), y=('인구', '합계', '계'),
....: data=yg, kind='line', hue=('자치구', '자치구', '자치구'))
....:
Out[74]: <seaborn.axisgrid.FacetGrid at 0x156b37f9278>
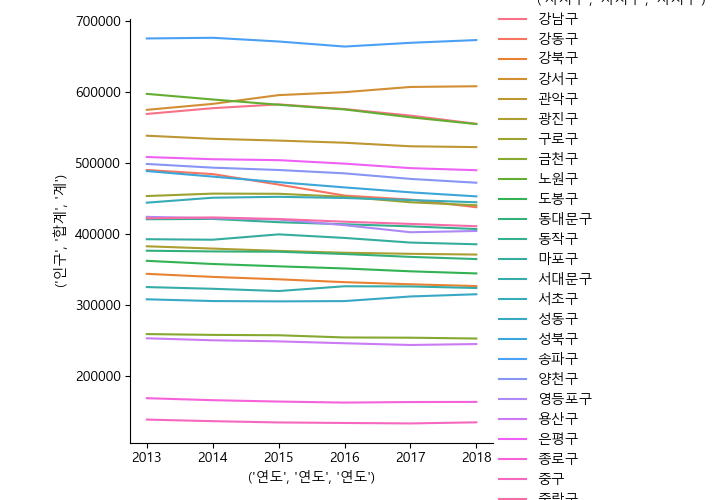
범위가 넓어서 인구의 증가를 알아보기 어렵다. 각각의 y 축의 범위를 다르게 설정하고 그려보자.
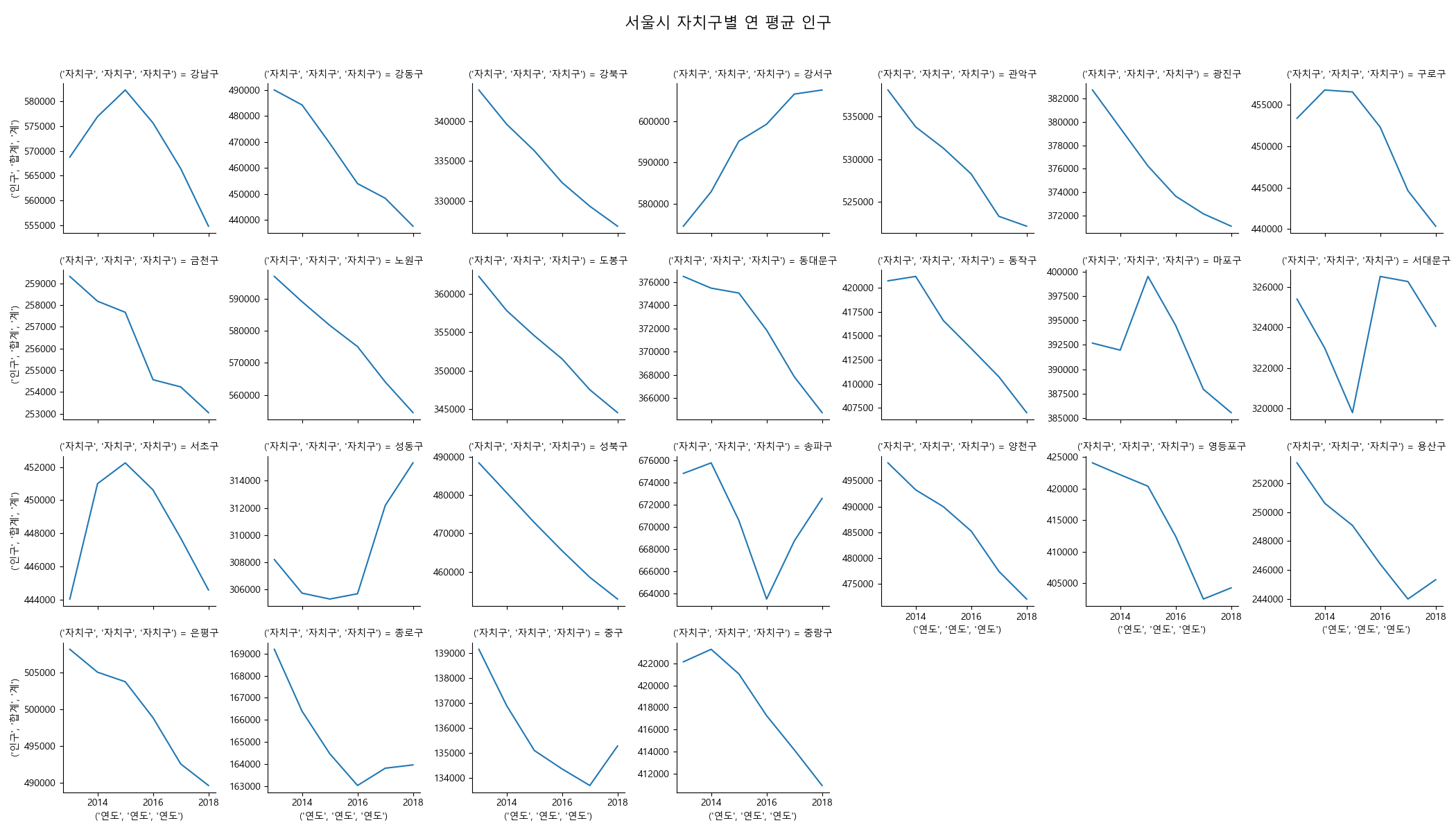
In [75]: g = sns.FacetGrid(yg, col=('자치구', '자치구', '자치구'), col_wrap=7, sharey=False)
....: g.map(sns.lineplot, ('연도', '연도', '연도'), ('인구', '합계', '계'))
....: g.fig.suptitle('서울시 자치구별 연 평균 인구', size=16)
....: g.fig.subplots_adjust(top=.9)
....:
Out[76]: <seaborn.axisgrid.FacetGrid at 0x156b2e36390>
Out[77]: Text(0.5,0.98,'서울시 자치구별 연 평균 인구')
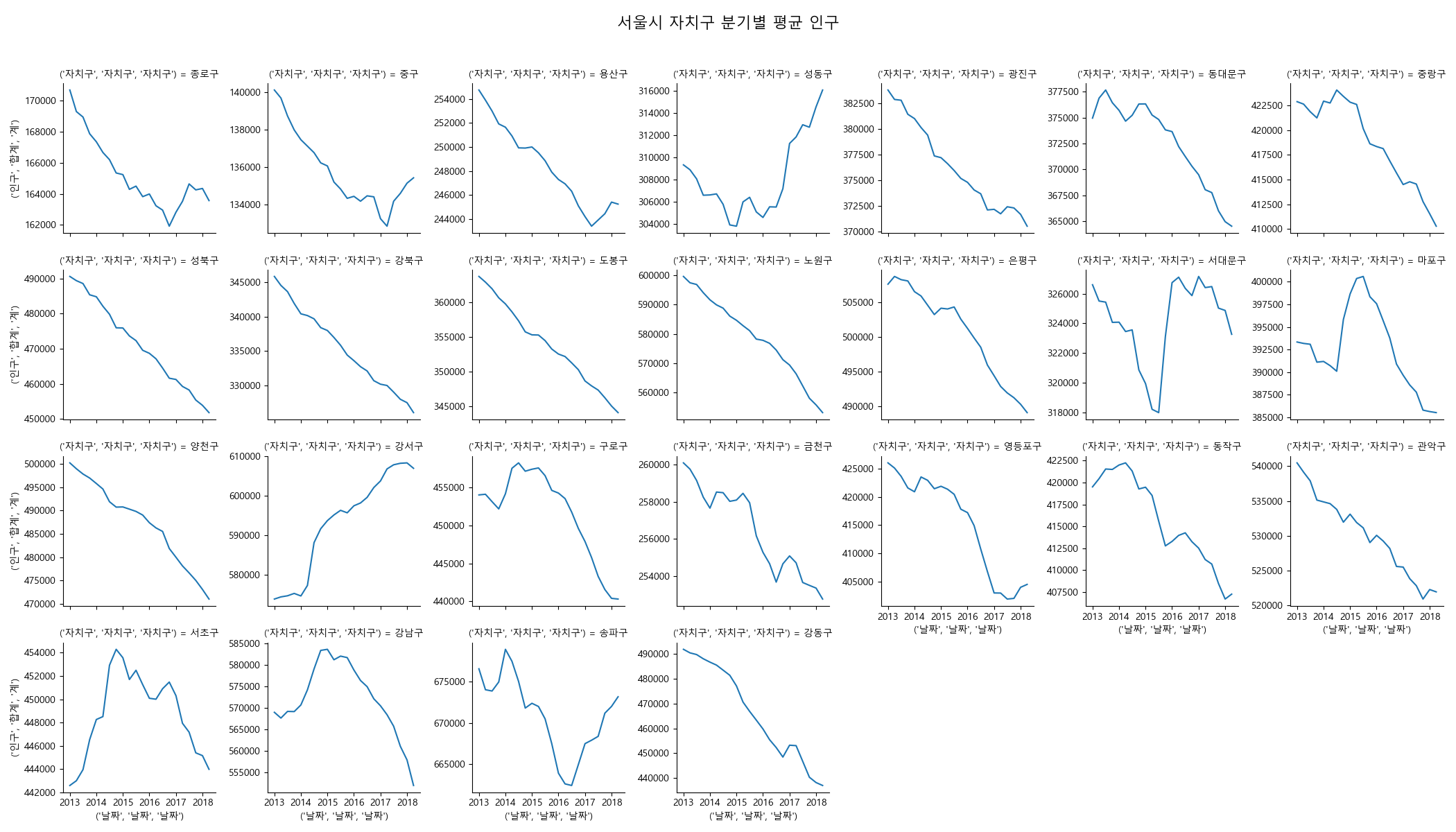
분기별 인구수 변동¶
자치구별 분기에 대한 인구수 변동을 살펴보자.
In [79]: pop1[('날짜', '날짜', '날짜')] = pop1.loc[:, ('기간', '기간', '기간')].apply(lambda x: x.to_timestamp())
....: pop1
....:
Out[80]:
기간 자치구 인구 고령자 연도 날짜
기간 자치구 합계 한국인 외국인 고령자 연도 날짜
기간 자치구 계 남자 여자 계 남자 여자 계 남자 여자 고령자 연도 날짜
1 2013Q1 종로구 170681 84719 85962 162777 81033 81744 7904 3686 4218 23853 2013 2013-01-01
2 2013Q1 중구 140127 70339 69788 132652 66605 66047 7475 3734 3741 19100 2013 2013-01-01
3 2013Q1 용산구 254749 124300 130449 242630 118012 124618 12119 6288 5831 33404 2013 2013-01-01
4 2013Q1 성동구 309312 154328 154984 302038 150875 151163 7274 3453 3821 34721 2013 2013-01-01
5 2013Q1 광진구 383806 188983 194823 371170 183297 187873 12636 5686 6950 36427 2013 2013-01-01
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ...
567 2018Q2 관악구 521960 262235 259725 504048 253600 250448 17912 8635 9277 71317 2018 2018-04-01
568 2018Q2 서초구 443989 212679 231310 439844 210596 229248 4145 2083 2062 54614 2018 2018-04-01
569 2018Q2 강남구 551888 264332 287556 546952 261815 285137 4936 2517 2419 66011 2018 2018-04-01
570 2018Q2 송파구 673161 327051 346110 666439 323741 342698 6722 3310 3412 79093 2018 2018-04-01
571 2018Q2 강동구 437050 216814 220236 432749 214740 218009 4301 2074 2227 57680 2018 2018-04-01
[550 rows x 14 columns]
In [81]: g = sns.FacetGrid(pop1, col=('자치구', '자치구', '자치구'), col_wrap=7, sharey=False)
....: g.map(sns.lineplot, ('날짜', '날짜', '날짜'), ('인구', '합계', '계'))
....: g.fig.suptitle('서울시 자치구 분기별 평균 인구', size=16)
....: g.fig.subplots_adjust(top=.9)
....:
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Out[82]: <seaborn.axisgrid.FacetGrid at 0x156b5d752b0>
Out[83]: Text(0.5,0.98,'서울시 자치구 분기별 평균 인구')
남여 인구¶
연도와 인구만 뽑아낸다.
In [85]: df = pyear.loc[:, idx[:, ['연도', '합계'], :]]
....: df
....:
Out[86]:
연도 인구
연도 합계
연도 계 남자 여자
0 2013 416616.23 205667.22 210949.01
1 2014 415250.77 204711.15 210539.62
2 2015 413475.44 203471.00 210004.44
3 2016 409842.58 201274.23 208568.35
4 2017 406589.89 199215.66 207374.23
5 2018 404031.74 197688.50 206343.24
필요없는 레벨을 제거한다.
In [87]: df.columns = df.columns.droplevel([0,1])
그래프를 그리기위해 자료 변형한다.
In [88]: dfm = df.melt(id_vars='연도', value_vars=['남자', '여자'], value_name='인구', var_name='성별')
In [89]: sns.relplot(data=dfm, x='연도', y='인구', hue='성별', markers=True, style='성별')
Out[89]: <seaborn.axisgrid.FacetGrid at 0x156b3363128>
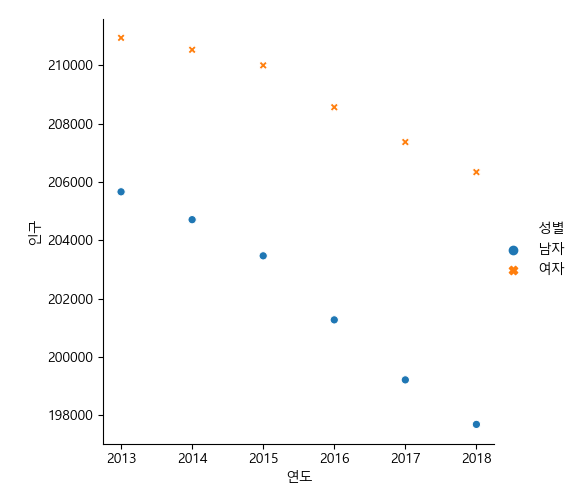
남여 비율¶
연도에 따른 남여 인구 비율을 계산해본다.
In [90]: df = pyear.loc[:, idx[:, '합계', ['남자', '여자']]].div(pyear.loc[:, idx['인구', '합계', '계']], axis=0)
....: df
....:
Out[91]:
인구
합계
남자 여자
0 0.493661 0.506339
1 0.492982 0.507018
2 0.492099 0.507901
3 0.491101 0.508899
4 0.489967 0.510033
5 0.489290 0.510710
연도 열을 추가하자.
In [92]: df = pd.concat([df, pyear.loc[:, ('연도','연도','연도')]], axis=1)
....: df
....:
Out[93]:
인구 연도
합계 연도
남자 여자 연도
0 0.493661 0.506339 2013
1 0.492982 0.507018 2014
2 0.492099 0.507901 2015
3 0.491101 0.508899 2016
4 0.489967 0.510033 2017
5 0.489290 0.510710 2018
0, 1레벨을 제거하자.
In [94]: df.columns = df.columns.droplevel([0, 1])
그래프를 위해서 자료를 변형하자.
In [95]: dfm = df.melt(id_vars='연도', value_name='비율', var_name='성별')
....: dfm
....:
Out[96]:
연도 성별 비율
0 2013 남자 0.493661
1 2014 남자 0.492982
2 2015 남자 0.492099
3 2016 남자 0.491101
4 2017 남자 0.489967
.. ... .. ...
7 2014 여자 0.507018
8 2015 여자 0.507901
9 2016 여자 0.508899
10 2017 여자 0.510033
11 2018 여자 0.510710
[12 rows x 3 columns]
그래프를 그리자
In [97]: g = sns.relplot(data=dfm, x='연도', y='비율', hue='성별')
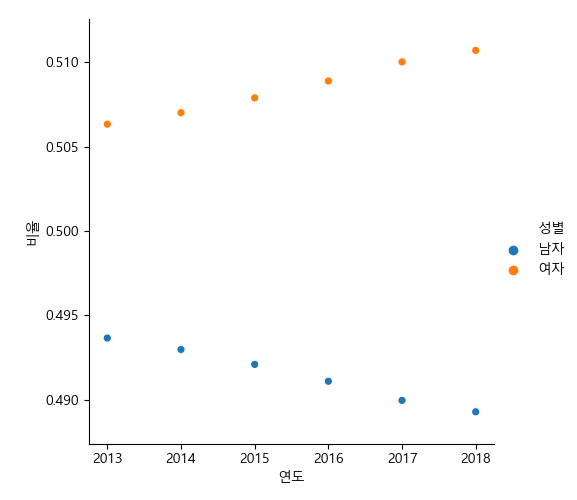
그림에서 보는 바와 같이 남여 전체 인구는 둘 다 감소하고 있지만 여자가 남자보다 약간씩 비율이 커지는 것을 알 수 있다.
Exercise
- 연도에 따른 자치구별 남여 인구비율을 계산하고 그래프를 그리시오.
국내/외국인¶
연도에 따른 서울시 평균 인구 국내/외국인 비율을 계산해보자.
pd.melt를 이용하여 자료를 긴 형식으로 변경하자. 다음은 연도, 국내외, 성별, 인구 열 형식으로 변경한 것이다.
In [98]: df = pyear.copy()
....: df.columns = df.columns.droplevel(0)
....: df = df.loc[:, idx[['연도','한국인', '외국인']]]
....: df.drop('계', level=1, axis=1, inplace=True)
....: dfm = df.melt(id_vars=[('연도', '연도')], var_name=['국내외', '성별'], value_name='인구')
....: dfm.rename(columns=lambda x: re.sub(r'연도.*', r'연도', ''.join(x)), inplace=True)
....: dfm
....:
Out[104]:
연도 국내외 성별 인구
0 2013 한국인 남자 200934.14
1 2014 한국인 남자 199724.41
2 2015 한국인 남자 198189.44
3 2016 한국인 남자 196046.02
4 2017 한국인 남자 194135.34
.. ... ... .. ...
19 2014 외국인 여자 5295.59
20 2015 외국인 여자 5623.43
21 2016 외국인 여자 5671.47
22 2017 외국인 여자 5607.34
23 2018 외국인 여자 5689.94
[24 rows x 4 columns]
긴 형식 중에서 연도, 국내외 별로 그룹을 더한 것을 각 연도의 인구수의 총합으로 나눠서 연도별 내/외국인 인구 비율을 계산한 것이다.
In [105]: foreign_rate = (
.....: dfm.groupby(['연도', '국내외'])
.....: .sum()
.....: .unstack()
.....: .div(dfm.groupby('연도').sum(), axis=1, level=0)
.....: .reset_index(col_fill='연도')
.....: .melt(id_vars='연도', value_name='비율', col_level=1)
.....: .sort_values('연도')
.....: )
.....: foreign_rate
.....:
Out[105]:
연도 국내외 비율
0 2013 외국인 0.023587
6 2013 한국인 0.976413
1 2014 외국인 0.024762
7 2014 한국인 0.975238
2 2015 외국인 0.026374
.. ... ... ...
9 2016 한국인 0.973405
4 2017 외국인 0.026286
10 2017 한국인 0.973714
5 2018 외국인 0.027159
11 2018 한국인 0.972841
[12 rows x 3 columns]
그래프로 그려보자. g.fig.clear() 함수는 위에서 그린 그림에 겹쳐 그리지 않도록 피겨를 말끔히 지우는 명령어이다.
In [106]: g.fig.clear()
.....: g = sns.pointplot(data=foreign_rate, x='연도', y='비율', hue='국내외'
.....: )
.....:
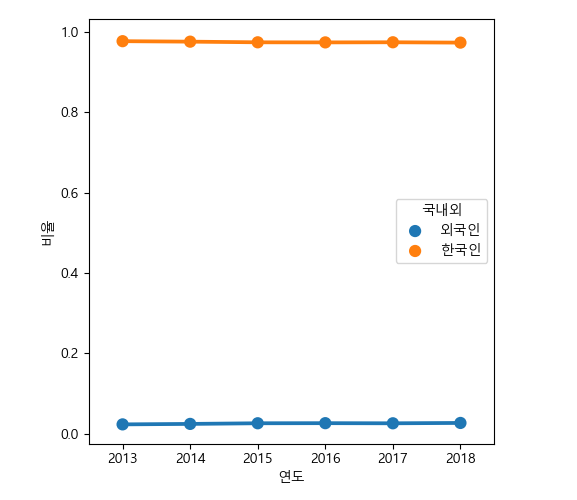
자치구별 고령자 비율¶
연도와 자치구에 대한 평균 인구수를 계산한다.
In [108]: pgu = pop1.groupby([('연도', '연도', '연도'), ('자치구', '자치구', '자치구')]).agg('mean')
합계, 계 열을 제거하자.
In [109]: pgu = pgu.drop('합계', axis=1, level=1).drop('계', axis=1, level=2)
행 레벨의 이름을 변경하자.
In [110]: pgu.rename_axis(['연도', '자치구'], inplace=True)
자치구만 뽑자.
In [111]: df = pgu.xs(['고령자','고령자'], axis=1, level=[1,2])
자치구별 고령자 비율을 계산하자.
In [112]: df = df.div(pgu.인구.sum(axis=1), axis=0) * 100
.....: df
.....:
Out[113]:
고령자
연도 자치구
2013 강남구 9.206835
강동구 9.564065
강북구 13.865747
강서구 10.144671
관악구 10.906631
... ...
2018 용산구 15.197817
은평구 15.483744
종로구 16.144634
중구 16.060037
중랑구 14.675463
[150 rows x 1 columns]
인덱스를 열로 보내자.
In [114]: df.reset_index(inplace=True)
그래프를 그려보자
In [115]: g.figure.clear()
.....: g = sns.pointplot(x='자치구', y='고령자', hue='연도', data=df)
.....: g.set_xticklabels(g.get_xticklabels(), rotation=70);
.....: g.figure.tight_layout()
.....:
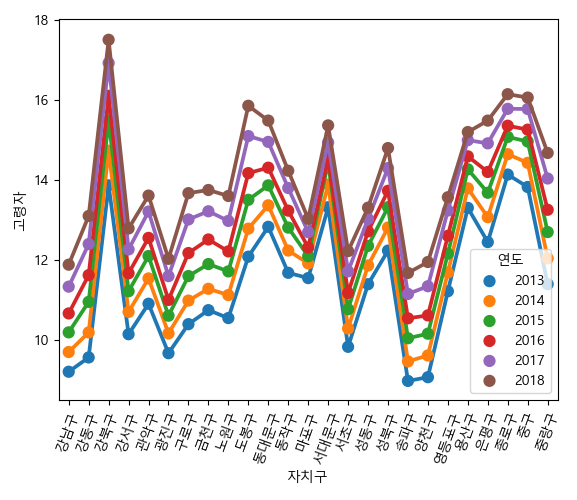
다음은 고령자 비율을 연도에 따라 본 것이다.
In [119]: g.figure.clear()
.....: sns.pointplot(data=df, x='연도', y='고령자', hue='자치구')
.....:
Out[120]: <matplotlib.axes._subplots.AxesSubplot at 0x156b7298da0>
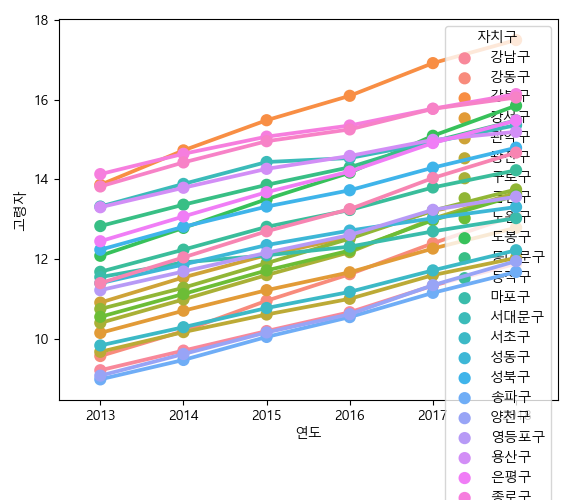
sqlite3로 저장¶
sqlite3 디비 형식으로 저장하자.
열 레벨 이름 변경¶
인구밀도와 면적 뒤에 붙은 단위 제거한다.
In [121]: psql = pop.copy()
.....: psql.rename(columns=lambda x: re.sub(r'\(.*', r'', x), inplace=True)
.....:
65세이상고령자를 고령자로 변경한다.
In [123]: psql.rename(columns=lambda x: re.sub(r'65세이상고령자', r'고령자', x), inplace=True)
등록외국인을 외국인으로 변경한다.
In [124]: psql.rename(columns=lambda x: re.sub(r'등록', r'', x), inplace=True)
열 삭제¶
합계, 세대당인구, 인구밀도, 계 열을 삭제한다.
In [125]: psql.drop(columns=['합계', '세대당인구'], level=1, inplace=True)
.....: psql.drop(columns='인구밀도', level=2, inplace=True)
.....: psql.drop(columns='계', level=2, inplace=True)
.....: psql
.....:
Out[128]:
기간 자치구 세대 인구 인구밀도 고령자
기간 자치구 세대 한국인 외국인 인구밀도 고령자
기간 자치구 세대 남자 여자 남자 여자 면적 고령자
1 2013Q1 종로구 74581 81033 81744 3686 4218 23.91 23853
2 2013Q1 중구 61217 66605 66047 3734 3741 9.96 19100
3 2013Q1 용산구 110479 118012 124618 6288 5831 21.87 33404
4 2013Q1 성동구 127035 150875 151163 3453 3821 16.85 34721
5 2013Q1 광진구 158987 183297 187873 5686 6950 17.06 36427
.. ... ... ... ... ... ... ... ... ...
567 2018Q2 관악구 259681 253600 250448 8635 9277 - 71317
568 2018Q2 서초구 174268 210596 229248 2083 2062 - 54614
569 2018Q2 강남구 229160 261815 285137 2517 2419 - 66011
570 2018Q2 송파구 268325 323741 342698 3310 3412 - 79093
571 2018Q2 강동구 177605 214740 218009 2074 2227 - 57680
[550 rows x 9 columns]
melt¶
In [130]: psqlm = psql.melt(id_vars=[('기간','기간'), ('자치구', '자치구'), ('세대', '세대'), ('인구밀도','면적'), ('고령자', '고령자')],
.....: var_name=['내외국인', '성별'], value_name='인구')
.....: psqlm.head()
.....:
Out[130]:
(기간, 기간) (자치구, 자치구) (세대, 세대) (인구밀도, 면적) (고령자, 고령자) 내외국인 성별 인구
0 2013Q1 종로구 74581 23.91 23853 한국인 남자 81033
1 2013Q1 중구 61217 9.96 19100 한국인 남자 66605
2 2013Q1 용산구 110479 21.87 33404 한국인 남자 118012
3 2013Q1 성동구 127035 16.85 34721 한국인 남자 150875
4 2013Q1 광진구 158987 17.06 36427 한국인 남자 183297
열 레벨의 이름을 변경하자. 열 레벨의 이름이 튜플일 경우는 첫번째 성분을 선택하고 그렇지 않은 경우는 그대로 선택한다.
In [131]: psqlm.rename(columns=lambda x: x[1] if isinstance(x, tuple) else x, inplace=True)
.....: psqlm.head()
.....:
Out[132]:
기간 자치구 세대 면적 고령자 내외국인 성별 인구
0 2013Q1 종로구 74581 23.91 23853 한국인 남자 81033
1 2013Q1 중구 61217 9.96 19100 한국인 남자 66605
2 2013Q1 용산구 110479 21.87 33404 한국인 남자 118012
3 2013Q1 성동구 127035 16.85 34721 한국인 남자 150875
4 2013Q1 광진구 158987 17.06 36427 한국인 남자 183297
sqlite3 db는 판다스 Period 객체를 인식할 수 없어서 저장이 되질 않는다. 기간 열을 datetime 객체로 변경하자.
In [133]: psqlm['기간'] = psqlm.기간.apply(lambda x: x.to_timestamp())
면적이 문자열과 실수형이 섞였기 때문에 강제로 실수형으로 변환해서 저장하자.
In [134]: psqlm.면적 = psqlm.면적.apply(pd.to_numeric, errors='coerce')
디비 저장¶
sqlite3 모듈을 불러와서 ./data/pop.sqlite3 파일로 디비 파일을 연다.
In [135]: import sqlite3
.....: conn = sqlite3.connect('./data/pop.sqlite3')
.....:
테이블 이름을 pop으로 저장한다. 데이터프레임의 to_sql 메소드를 이용해서 데이터프레임을 테이블로 저장할 수 있다. 테이블이 이미 존재하면 기본값으로는 쓰기 실패 에러를 발생한다. 만일 덮어쓰고 싶거나 기존의 테이블에 덧붙이기 위해서는 if_exists= 옵션에 replace 또는 append를 지정하면 된다.
In [137]: psqlm.to_sql('pop', conn)
디비에 있는 테이블은 pd.read_sql 함수를 이용해서 불러올 수 있다.
In [138]: dfp = pd.read_sql("SELECT * FROM pop;", conn)
.....: dfp.head()
.....:
Out[139]:
ridx 기간 자치구 세대 면적 고령자 내외국인 성별 인구
0 0 2013-01-01 00:00:00 종로구 74581 23.91 23853 한국인 남자 81033
1 1 2013-01-01 00:00:00 중구 61217 9.96 19100 한국인 남자 66605
2 2 2013-01-01 00:00:00 용산구 110479 21.87 33404 한국인 남자 118012
3 3 2013-01-01 00:00:00 성동구 127035 16.85 34721 한국인 남자 150875
4 4 2013-01-01 00:00:00 광진구 158987 17.06 36427 한국인 남자 183297
결과를 보면 index 열이 생긴 것을 볼 수 있다. 이것은 데이터프레임 행 인덱스가 자동으로 index 열로 저장된 것이다. 그런데 sqlite3에서는 index는 특별한 의미를 가져서 index 열을 가져올 수 없게 된다. 따라서 데이터프레임을 디비로 저장할 때 index=False를 사용하던지 또는 index_label=을 직접 지정하면 된다.
디비에 있는 테이블을 삭제하는 방법은 sqlite3 명령어를 사용해서 삭제할 수 있다.
In [140]: conn.execute("DROP TABLE pop;")
다음과 같이 index_label을 ridx로 설정한다.
In [141]: psqlm.to_sql('pop', conn, index_label='ridx')
디비를 모두 사용했으면 반드시 닫아준다. 일단 닫으면 다시 열기전까지는 디비에 접속할 수 없다.
In [142]: conn.close()
연습문제
- CCTV 자료를 디비로 저장해보자. 테이블 이름은 cctv로 하고 열은 다음과 같이 나오게 한다.
자치구 연도 cctv
강남구 2013 1292
강동구 2013 379
강북구 2013 369
강서구 2013 388
관악구 2013 846
- 연도별로 cctv 수량으로 정렬해보자.
년도별 자치구별 외국인수¶
외국인만 뽑아 내자.
In [145]: conn = sqlite3.connect('./data/pop.sqlite3')
.....: df = pd.read_sql('select 기간, 자치구, 성별, 인구 from pop where 내외국인="외국인"', conn)
.....: conn.close()
.....: df.head()
.....:
Out[148]:
기간 자치구 성별 인구
0 2013-01-01 00:00:00 종로구 남자 3686
1 2013-01-01 00:00:00 중구 남자 3734
2 2013-01-01 00:00:00 용산구 남자 6288
3 2013-01-01 00:00:00 성동구 남자 3453
4 2013-01-01 00:00:00 광진구 남자 5686
기간이 문자열이라서 시간객체로 바꾼다.
In [149]: df.기간 = pd.to_datetime(df.기간)
연도, 분기 열을 만들자.
In [150]: df['연도'] = df.기간.apply(lambda x: x.year)
.....: df['분기'] = df.기간.apply(lambda x: x.quarter)
.....:
년도, 자치구별 평균 인구수를 계산하자.
In [152]: dfm = df.groupby(['연도', '자치구'])['인구'].mean().reset_index()
.....: dfm
.....:
Out[153]:
연도 자치구 인구
0 2013 강남구 2878.000
1 2013 강동구 2364.500
2 2013 강북구 1620.000
3 2013 강서구 3102.500
4 2013 관악구 8641.875
.. ... ... ...
145 2018 용산구 7767.500
146 2018 은평구 2188.500
147 2018 종로구 4897.000
148 2018 중구 4613.000
149 2018 중랑구 2357.250
[150 rows x 3 columns]
그래프로 그리자.
In [154]: g = sns.FacetGrid(dfm, col="연도", col_wrap=3)
.....: g.map(sns.barplot, '자치구', '인구')
.....:
Out[155]: <seaborn.axisgrid.FacetGrid at 0x156b768c898>
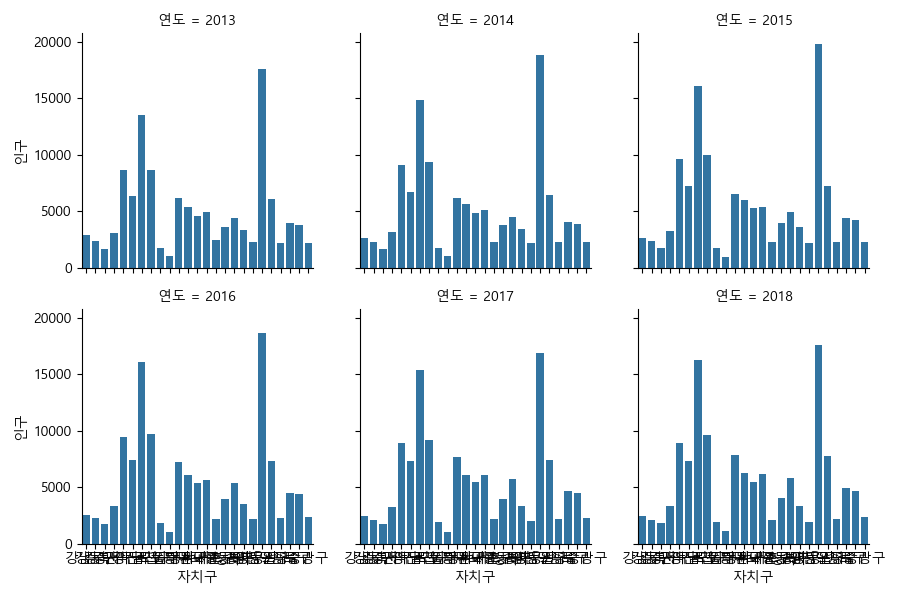
pivot 메소드를 이용하면 표로 변경할 수 있다. 다음은 연도를 행으로 자치구를 열로 갖고 각 셀은 대응되는 인구로 채우는 표이다.
In [156]: dfm.pivot(index='연도', columns='자치구', values='인구')
Out[156]:
자치구 강남구 강동구 강북구 강서구 관악구 광진구 구로구 금천구 ... 송파구 양천구 영등포구 용산구 은평구 종로구 중구 중랑구
연도 ...
2013 2878.000 2364.500 1620.00 3102.500 8641.875 6315.625 13518.125 8644.375 ... 3369.375 2243.375 17608.000 6057.500 2212.375 3931.125 3788.750 2185.875
2014 2679.500 2302.875 1654.25 3165.625 9060.250 6746.500 14868.250 9334.875 ... 3449.875 2230.750 18848.250 6407.500 2283.625 4015.875 3902.875 2275.500
2015 2662.500 2351.750 1739.00 3287.625 9601.375 7260.000 16131.250 9988.375 ... 3587.500 2232.625 19778.250 7211.250 2317.500 4377.250 4221.250 2323.000
2016 2542.375 2225.000 1756.25 3303.750 9473.500 7410.375 16050.000 9677.875 ... 3536.625 2151.375 18679.375 7357.750 2257.250 4508.750 4422.125 2350.750
2017 2464.875 2070.375 1745.00 3259.250 8891.500 7336.875 15402.375 9181.125 ... 3359.000 1965.750 16908.750 7442.125 2211.250 4670.250 4440.250 2267.125
2018 2456.250 2124.750 1831.75 3347.250 8939.750 7323.250 16274.250 9648.750 ... 3358.500 1935.250 17589.500 7767.500 2188.500 4897.000 4613.000 2357.250
[6 rows x 25 columns]
연습문제
- 연도별로 외국인들의 수가 적은 것부터 많은 수로 자치구를 나열하여 그래프로 그려보자. 즉, 서브플롯이 연도별로 각각 나오도록 그린다.
CCTV와 인구 자료 합치기¶
CCTV 자료와 인구 자료를 디비로부터 불러온다.
In [157]: conn = sqlite3.connect('./data/pop.sqlite3')
.....: cctv = pd.read_sql('SELECT * FROM cctv;', conn)
.....: pop = pd.read_sql('SELECT * FROM pop;', conn)
.....: conn.close()
.....:
기간을 시간객체로 바꾼다.
In [161]: pop.기간 = pd.to_datetime(pop.기간)
인구 자료 중에서 인구, 세대, 고령자 열 정보를 각 분기별, 자치구별로 뽑아내자.
In [162]: popq = pop.pivot_table(index=['기간', '자치구'], values=['고령자', '세대', '인구'], aggfunc={'고령자': np.mean, '세대': np.mean, '인구': np.sum})
.....: popq.head()
.....:
Out[163]:
고령자 세대 인구
기간 자치구
2013-01-01 강남구 51389 230346 568982
강동구 45935 187116 491770
강북구 46923 142061 345850
강서구 56904 224346 573808
관악구 57670 248691 540467
인덱스를 열로 변경하자.
In [164]: popq.reset_index(inplace=True)
연도 열을 만들자.
In [165]: popq['연도'] = popq.기간.map(lambda x: x.year)
.....: popq.head()
.....:
Out[166]:
기간 자치구 고령자 세대 인구 연도
0 2013-01-01 강남구 51389 230346 568982 2013
1 2013-01-01 강동구 45935 187116 491770 2013
2 2013-01-01 강북구 46923 142061 345850 2013
3 2013-01-01 강서구 56904 224346 573808 2013
4 2013-01-01 관악구 57670 248691 540467 2013
연도별 자치구별 평균을 구하자.
In [167]: popy = popq.pivot_table(index=['연도', '자치구'])
인덱스를 열로 변경하자.
In [168]: popy.reset_index(inplace=True)
cctv를 합치기 전에 cctv 열 중 연도가 문자열로 되어 있어 정수로 바꾼다.
In [169]: cctv.연도 = cctv.연도.astype('int')
pd.merge를 이용해서 인구와 CCTV를 합친다.
In [170]: poptv = pd.merge(cctv, popy, on=['연도', '자치구'])
.....: poptv
.....:
Out[171]:
자치구 연도 cctv 고령자 세대 인구
0 강남구 2013 1292 52363.00 230275.00 568740.50
1 강동구 2013 379 46857.75 186878.75 489935.50
2 강북구 2013 369 47696.75 141661.25 343989.75
3 강서구 2013 388 58282.00 225517.25 574508.50
4 관악구 2013 846 58694.50 248456.50 538154.25
.. ... ... ... ... ... ...
95 용산구 2016 2096 35953.75 107063.00 246412.50
96 은평구 2016 2108 70843.50 202541.50 498885.75
97 종로구 2016 1619 25034.75 72666.50 163026.75
98 중구 2016 1023 20502.25 59474.00 134370.75
99 중랑구 2016 916 55307.00 177114.50 417259.75
[100 rows x 6 columns]
상관계수 계산¶
고령자, 세대, 인구, cctv간의 상관계수를 계산하자.
In [172]: poptv.iloc[:, 2:].corr()
Out[172]:
cctv 고령자 세대 인구
cctv 1.000000 0.209339 0.178368 0.172966
고령자 0.209339 1.000000 0.913084 0.900412
세대 0.178368 0.913084 1.000000 0.979437
인구 0.172966 0.900412 0.979437 1.000000
cctv와 다른 것과 그렇게 큰 상관관계는 찾아볼 수 없다. 하지만 분석을 위해서 인구와 cctv와의 관계에 중점을 둔다.
2016년 인구와 CCTV 비교¶
2016년 인구와 CCTV와 자치구만 추려낸다.
In [173]: pt = poptv.query('연도 == 2016').filter(regex='cctv|자치|인구')
.....: pt
.....:
Out[174]:
자치구 cctv 인구
75 강남구 3238 575597.25
76 강동구 1010 453991.00
77 강북구 831 332293.00
78 강서구 911 599344.50
79 관악구 2109 528280.00
.. ... ... ...
95 용산구 2096 246412.50
96 은평구 2108 498885.75
97 종로구 1619 163026.75
98 중구 1023 134370.75
99 중랑구 916 417259.75
[25 rows x 3 columns]
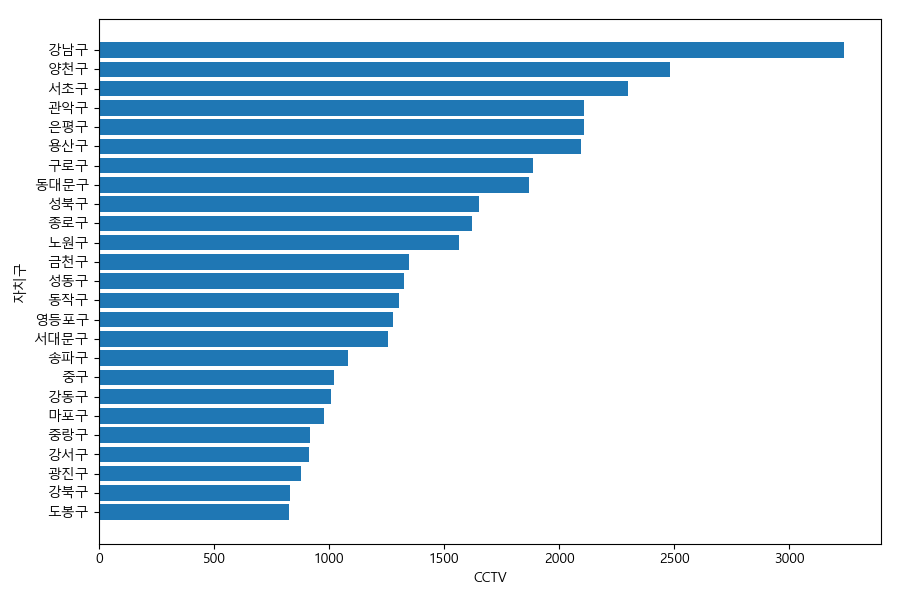
cctv 설치수에 따른 정렬을 그래프로 그려보자.
In [175]: import matplotlib.pyplot as plt
.....: ax = plt.subplot()
.....: ax.barh(data=pt.sort_values('cctv'), y='자치구', width='cctv')
.....: ax.set_xlabel('CCTV')
.....: ax.set_ylabel('자치구')
.....: ax.figure.tight_layout()
.....:
Out[177]: <BarContainer object of 25 artists>
Out[178]: Text(0.5,0,'CCTV')
Out[179]: Text(0,0.5,'자치구')
100명당 CCTV 설치 비율을 계산해서 그래프로 그리자.
In [181]: pt['CCTV비율'] = pt.cctv/pt.인구*100
.....: ax.cla()
.....: ax.grid()
.....: ax.barh(data=pt.sort_values('CCTV비율'), y='자치구', width='CCTV비율')
.....:
Out[184]: <BarContainer object of 25 artists>
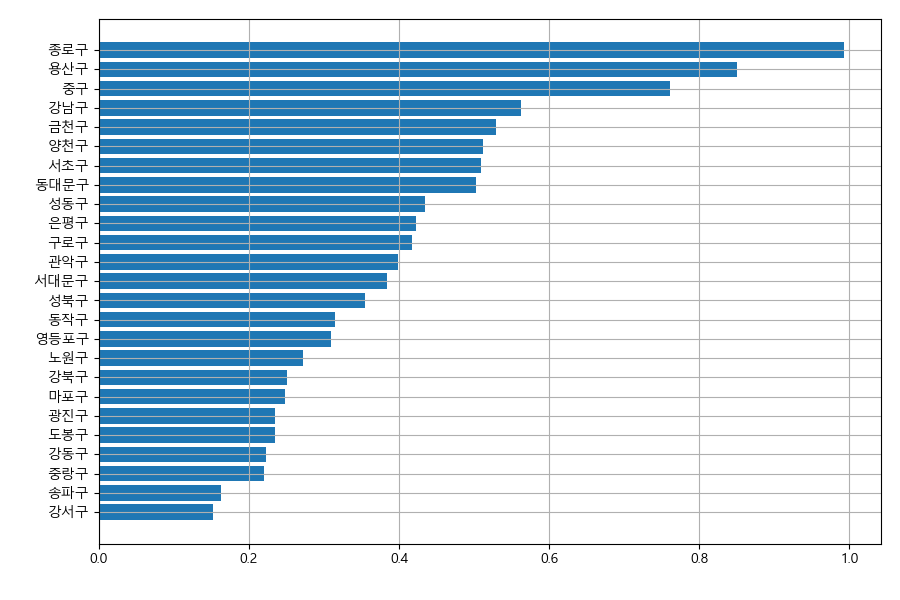
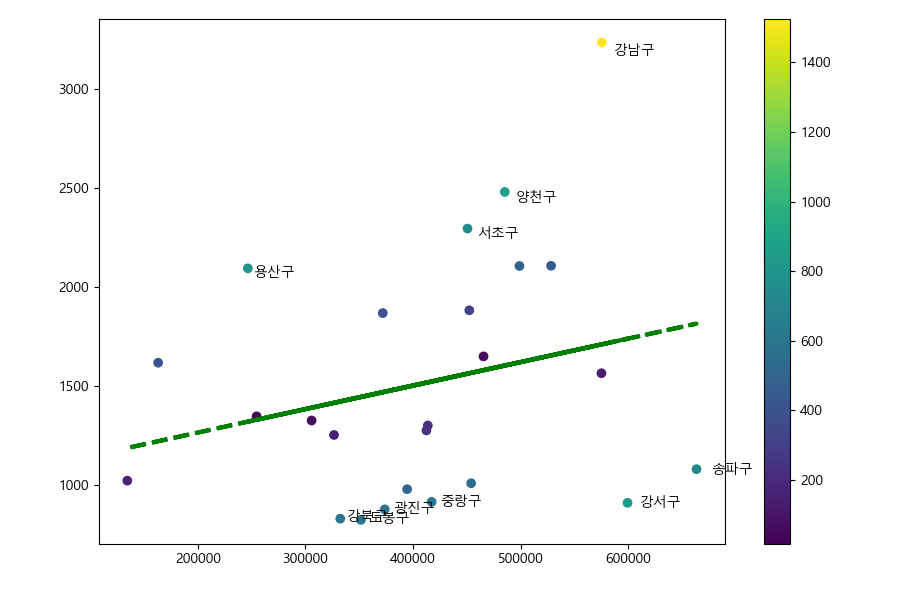
종로구, 용산구와 중구가 상대적으로 많은 것을 알 수 있다.
연습문제
- 2016년 각 자치구별 면적에 대한 CCTV 비율을 계산하고 그래프로 나타내시오. 면적은 2013년도 것을 사용하시오.
인구와 CCTV 축으로 하는 scatter 그래프¶
인구와 CCTV를 축으로하는 산점도 그래프를 그려보자.
In [186]: ax.cla()
.....: ax.scatter(pt.인구, pt.cctv)
.....: for i, txt in enumerate(pt.자치구):
.....: ax.text(pt.인구.iloc[i], pt.cctv.iloc[i], txt)
.....: ax.set_xlabel('인구')
.....: ax.set_ylabel('CCTV')
.....:
Out[187]: <matplotlib.collections.PathCollection at 0x156b80b5780>
Out[188]: Text(28.0781,0.5,'CCTV')
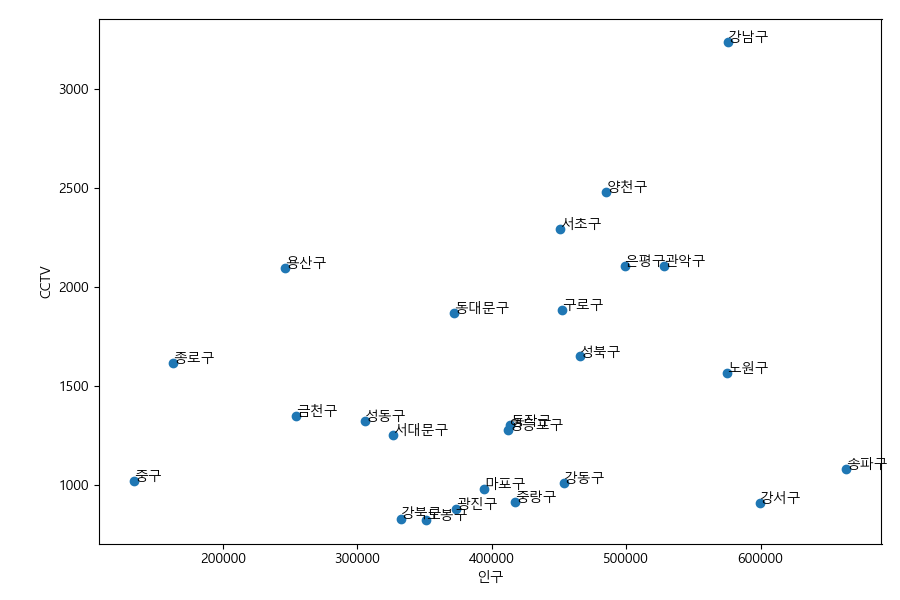
인구와 CCTV에 대한 선형회귀 직선 그래프¶
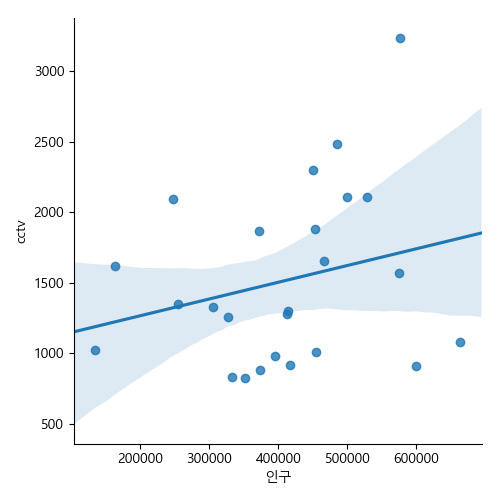
최소 제곱법(least squares method)을 이용해서 인구와 CCTV 자료의 선형회귀 직선을 구해보자. np.polyfit(x, y, deg) 메소드를 이용해서 deg 차수의 다항식의 계수를 구할 수 있다. 반환된 값에서 앞에 나오는 것이 높은 차수의 계수이다. 다음은 인구가 x, cctv 값이 y값으로 하는 1차 다항식의 계수를 구한 것이다.
In [189]: pt_poly = np.polyfit(pt.인구, pt.cctv, 1)
.....: pt_poly
.....:
Out[190]: array([1.18742938e-03, 1.02866088e+03])
np.poly1d(coef) 메소드를 이용해서 다항식 계수 배열 coef를 넘겨 다항함수를 만들 수 있다. 다음은 np.polyfit을 이용하여 인구와 CCTV에 대한 일차방정식의 계수를 이용하여 구한 일차함수 f1이다.
In [191]: f1 = np.poly1d(pt_poly)
이것을 이용해서 그래프에 직선을 함께 표시하자.
In [192]: ax.cla()
.....: ax.scatter(pt.인구, pt.cctv)
.....: ax.plot(pt.인구, f1(pt.인구))
.....:
Out[193]: <matplotlib.collections.PathCollection at 0x156b73f49e8>
Out[194]: [<matplotlib.lines.Line2D at 0x156b73f4240>]
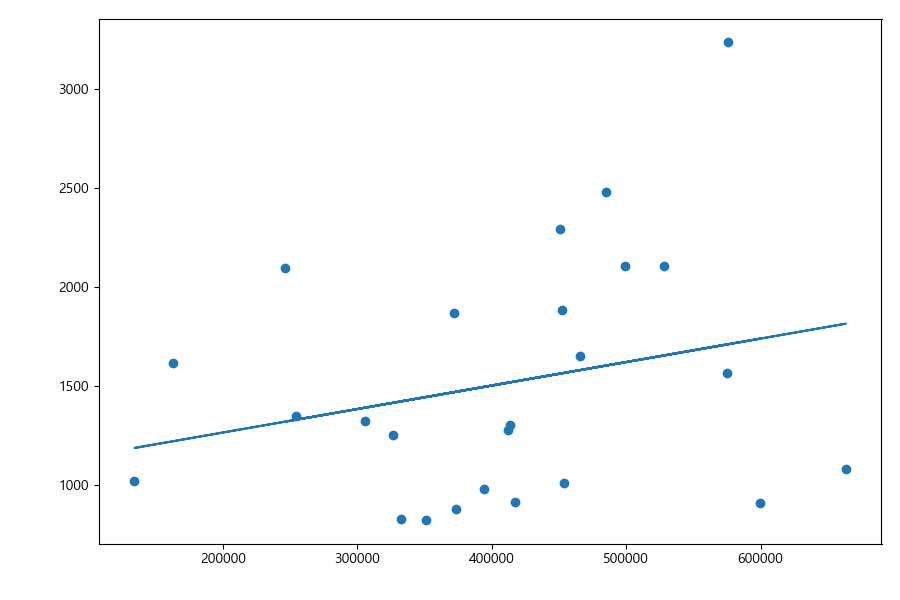
회귀직선과 각 자치구의 CCTV와의 오차를 구해보자.
In [195]: pt['오차'] = np.abs(pt.cctv - f1(pt.인구))
오차가 큰 순서대로 상위 10개의 구를 그래프에 표시하자.
In [196]: ax.cla()
.....: s = ax.scatter(pt.인구, pt.cctv, c=pt.오차)
.....: ax.plot(pt.인구, f1(pt.인구), linewidth=3, linestyle='dashed', color='g')
.....: ax.figure.colorbar(s)
.....: for i in pt.sort_values('오차', ascending=False).iloc[:10].index:
.....: ax.text(pt.인구[i] * 1.02, pt.cctv[i] * 0.98, pt.자치구[i])
.....:
Out[198]: [<matplotlib.lines.Line2D at 0x156b80eea90>]
Out[199]: <matplotlib.colorbar.Colorbar at 0x156b724f6a0>
seaborn을 이용해서 그릴 수도 있다.
In [201]: ax.cla()
.....: sns.lmplot(data=pt, x='인구', y='cctv')
.....:
Out[202]: <seaborn.axisgrid.FacetGrid at 0x156b7248f60>