자연어 처리¶
KoNLPy¶
KoNLPy는 한국어 처리를 파이썬 패키지입니다. 기존에 개발된 라이브러리들을 파이썬에서 사용할 수 있게 해 놓은 것입니다. Hannanum, Kkma, Komoran, Mecab, Okt 클래스들을 사용할 수 있습니다. 대부분이 자바로 개발되어 있어서 파이썬에서 자바를 사용할 수 있는 모듈 JPype를 설치해야 합니다. Mecab 클래스는 윈도우즈에서는 지원되지 않습니다.
konlpy 설치¶
KoNLPy 홈페이지를 참조하세요.
- JPype 설치
conda install -c conda-forge jpype1
- konlpy 설치
pip install konlpy
사용하기¶
In [1]: from konlpy.tag import Kkma
...: kkma = Kkma()
...:
문장(sentences) 분석을 합니다.
In [3]: kkma.sentences("한국어 분석을 시작합니다 재미있어요~~~")
Out[3]: ['한국어 분석을 시작합니다', '재미있어요~~~']
명사(noun) 분석을 합니다.
In [4]: kkma.nouns("한국어 분석을 시작합니다 재미있어요~~~")
Out[4]: ['한국어', '분석']
형태소(pos) 분석을 합니다.
In [5]: kkma.pos("한국어 분석을 시작합니다 재미있어요~~~")
Out[5]:
[('한국어', 'NNG'),
('분석', 'NNG'),
('을', 'JKO'),
('시작하', 'VV'),
('ㅂ니다', 'EFN'),
('재미있', 'VA'),
('어요', 'EFN'),
('~~~', 'SW')]
한나눔(Hannanum) 클래스를 사용해 봅니다.
In [6]: from konlpy.tag import Hannanum
...: hannanum = Hannanum()
...:
명사 분석시를 사용해보면 꼬꼬마 분석기와 약간 다르게 시작이라는 명사를 찾는 것을 알 수 있습니다.
In [8]: hannanum.nouns("한국어 분석을 시작합니다 재미있어요~~~")
Out[8]: ['한국어', '분석', '시작']
한나눔 행태소 분석을 해봅니다.
In [9]: hannanum.pos("한국어 분석을 시작합니다 재미있어요~~~")
Out[9]:
[('한국어', 'N'),
('분석', 'N'),
('을', 'J'),
('시작', 'N'),
('하', 'X'),
('ㅂ니다', 'E'),
('재미있', 'P'),
('어요', 'E'),
('~~~', 'S')]
Okt 분석기를 사용해봅니다. 이것은 이전에 트위터(Twitter) 분석기로 불리었던 것입니다.
In [10]: from konlpy.tag import Okt
....: okt = Okt()
....:
In [12]: okt.nouns("한국어 분석을 시작합니다 재미있어요~~~")
Out[12]: ['한국어', '분석', '시작']
In [13]: okt.pos("한국어 분석을 시작합니다 재미있어요~~~")
Out[13]:
[('한국어', 'Noun'),
('분석', 'Noun'),
('을', 'Josa'),
('시작', 'Noun'),
('합니다', 'Verb'),
('재미있어요', 'Adjective'),
('~~~', 'Punctuation')]
법안 분석¶
육아 휴직 법안을 읽어들입니다.
In [14]: from konlpy.corpus import kobill
....: doc = kobill.open("1809890.txt").read()
....:
Okt 분석기로 명사 분석을 합니다.
In [16]: from konlpy.tag import Okt
....: okt = Okt()
....: tokens = okt.nouns(doc)
....: tokens[:10]
....:
Out[19]: ['지방공무원법', '일부', '개정', '법률', '안', '정의화', '의원', '대표', '발의', '의']
단어의 횟수를 확인해봅니다.
In [20]: import nltk
....: words = nltk.Text(tokens, name="육아휴직 법안")
....:
In [22]: from matplotlib import font_manager, rc
....: import matplotlib as mlp
....: font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
....: rc('font', family=font_name)
....: mlp.rcParams['axes.unicode_minus'] = False # 축에 음수 표시
....:
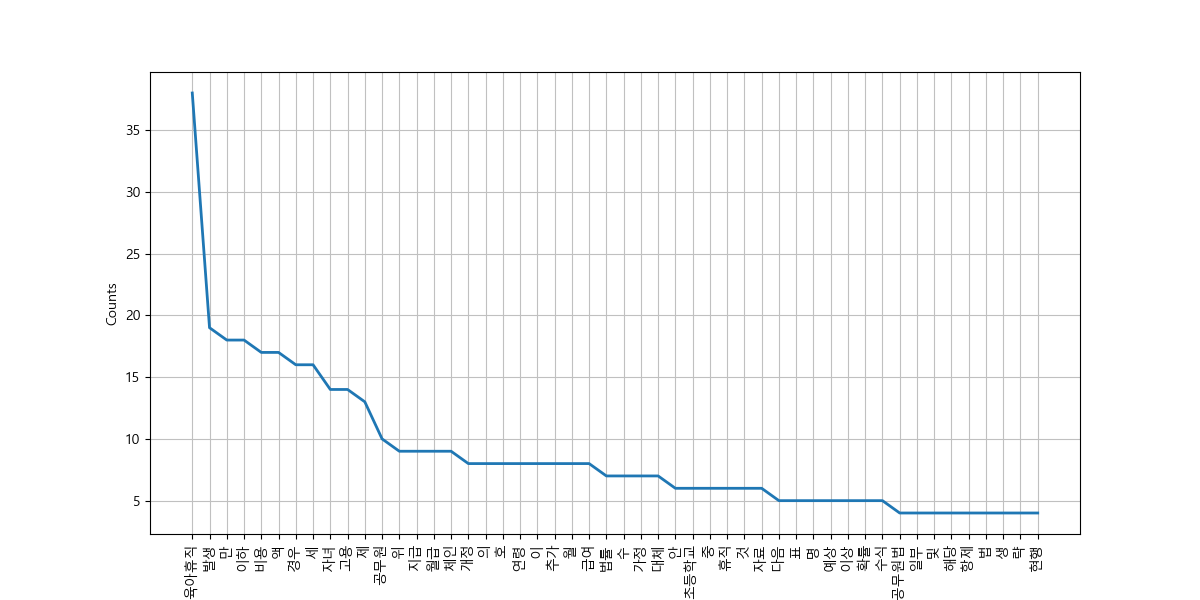
그래프로 표시합니다.
In [27]: import matplotlib.pyplot as plt
....: fig, ax = plt.subplots(figsize=(12, 6))
....: words.plot(50)
....:
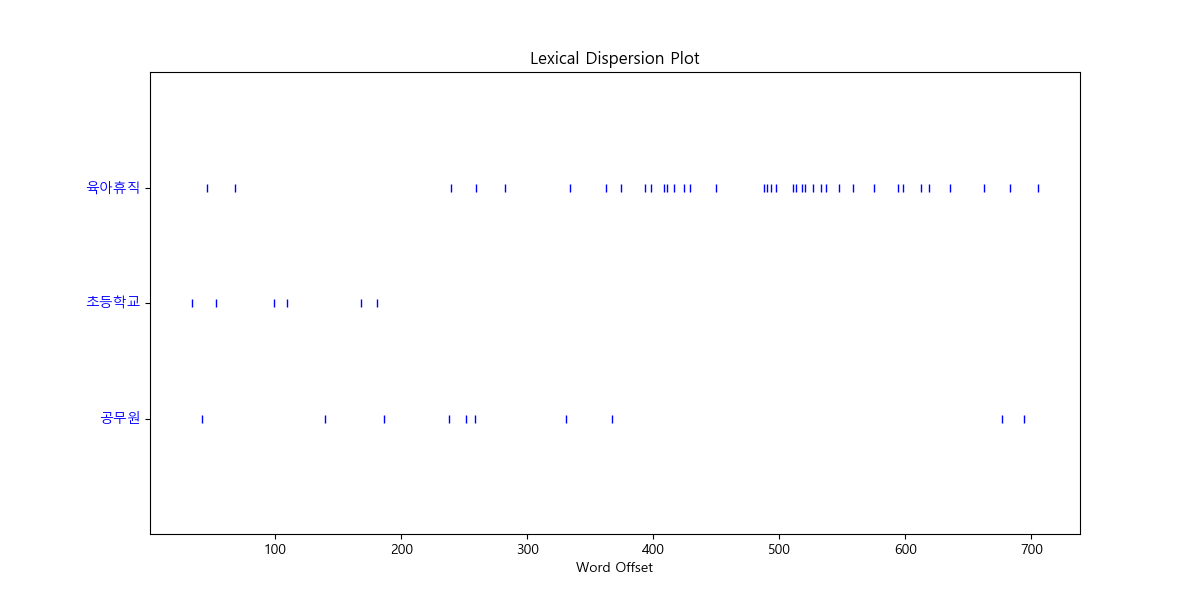
단어가 문서내에서 몇 번 나타나는지를 확인해봅니다.
In [30]: ax.cla()
....: words.dispersion_plot(['육아휴직', '초등학교', '공무원'])
....: