딥러닝
더 깊은 신경망
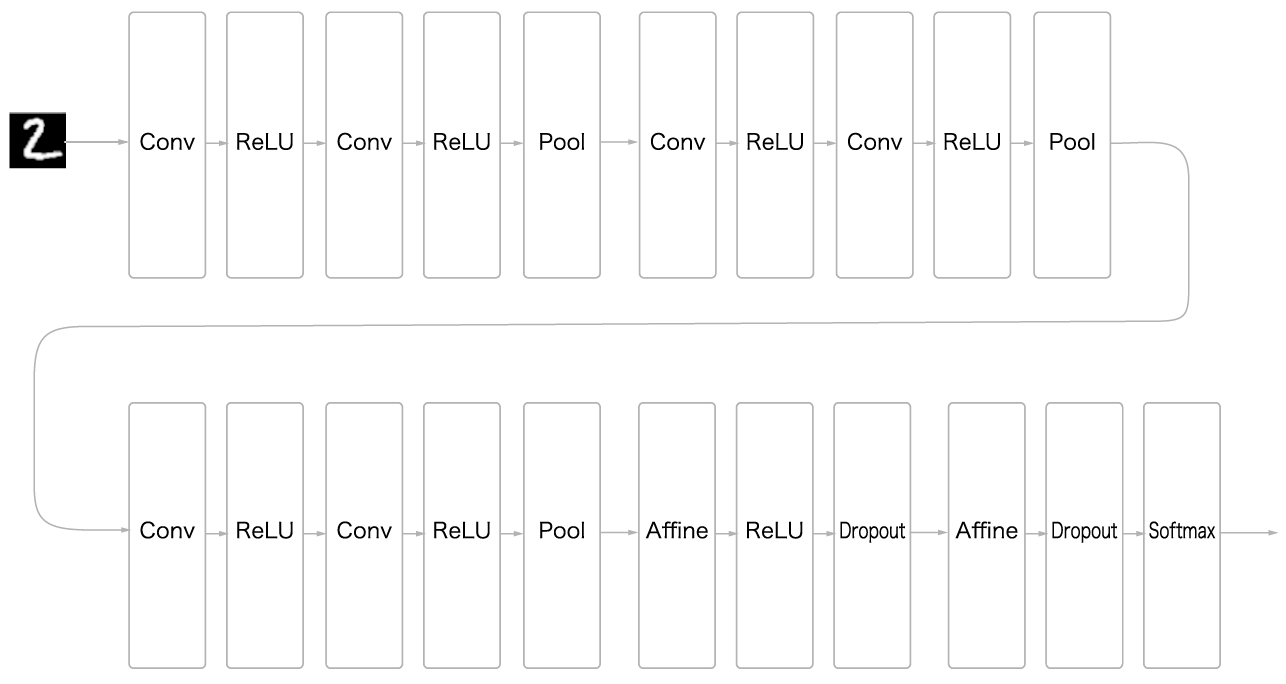
손글자 숫자 인식 심층 CNN
6개의 합성곱 계층으로 구성되어 있고 필터 크기는 모두
3x3입니다.합성곱 계층의 채널 수는 순서대로
16, 16, 32, 32, 64, 64입니다.활성화 함수는
Relu를 사용합니다.2개의 완전연결 계층 뒤에는 각각 드롭아웃 drop out 계층을 사용합니다.
가중치 매개변수 갱신에는
Adam방법을 이용합니다.가중치 초기값은 He 초깃값을 이용합니다.
__init__() 1class DeepConvNet:
2 """정확도 99% 이상의 고정밀 합성곱 신경망
3
4 네트워크 구성은 아래와 같음
5 conv - relu - conv- relu - pool -
6 conv - relu - conv- relu - pool -
7 conv - relu - conv- relu - pool -
8 affine - relu - dropout - affine - dropout - softmax
9 """
10 def __init__(self, input_dim=(1, 28, 28),
11 conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
12 conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
13 conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},
14 conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},
15 conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
16 conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
17 hidden_size=50, output_size=10):
18 # 가중치 초기화===========
19 # 각 층의 뉴런 하나당 앞 층의 몇 개 뉴런과 연결되는가(TODO: 자동 계산되게 바꿀 것)
20 pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size])
21 wight_init_scales = np.sqrt(2.0 / pre_node_nums) # ReLU를 사용할 때의 권장 초깃값
22
23 self.params = {}
24 pre_channel_num = input_dim[0]
25 for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):
26 self.params['W' + str(idx+1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'], pre_channel_num, conv_param['filter_size'], conv_param['filter_size'])
27 self.params['b' + str(idx+1)] = np.zeros(conv_param['filter_num'])
28 pre_channel_num = conv_param['filter_num']
29 self.params['W7'] = wight_init_scales[6] * np.random.randn(64*4*4, hidden_size)
30 self.params['b7'] = np.zeros(hidden_size)
31 self.params['W8'] = wight_init_scales[7] * np.random.randn(hidden_size, output_size)
32 self.params['b8'] = np.zeros(output_size)
33
34 # 계층 생성===========
35 self.layers = []
36 self.layers.append(Convolution(self.params['W1'], self.params['b1'],
37 conv_param_1['stride'], conv_param_1['pad']))
38 self.layers.append(Relu())
39 self.layers.append(Convolution(self.params['W2'], self.params['b2'],
40 conv_param_2['stride'], conv_param_2['pad']))
41 self.layers.append(Relu())
42 self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
43 self.layers.append(Convolution(self.params['W3'], self.params['b3'],
44 conv_param_3['stride'], conv_param_3['pad']))
45 self.layers.append(Relu())
46 self.layers.append(Convolution(self.params['W4'], self.params['b4'],
47 conv_param_4['stride'], conv_param_4['pad']))
48 self.layers.append(Relu())
49 self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
50 self.layers.append(Convolution(self.params['W5'], self.params['b5'],
51 conv_param_5['stride'], conv_param_5['pad']))
52 self.layers.append(Relu())
53 self.layers.append(Convolution(self.params['W6'], self.params['b6'],
54 conv_param_6['stride'], conv_param_6['pad']))
55 self.layers.append(Relu())
56 self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
57 self.layers.append(Affine(self.params['W7'], self.params['b7']))
58 self.layers.append(Relu())
59 self.layers.append(Dropout(0.5))
60 self.layers.append(Affine(self.params['W8'], self.params['b8']))
61 self.layers.append(Dropout(0.5))
62
63 self.last_layer = SoftmaxWithLoss()
20줄: He 초깃값을 사용하기 위해서는 각 계층의 뉴런 하나당 연결되는 앞 층의 뉴런의 개수가 필요합니다. 6개의 합성곱 계층과 2개의 완전연결 계층에 대한 앞 층의 뉴런의 개수 배열입니다.
21줄: He 초깃값을 사용합니다.
24-28줄: 합성곱 계층에 대한 매개변수를 초기화합니다.
24, 26, 28줄: 합성곱 계층의 입력데이터 채널 수는 앞 층의 출력 데이터의 채널 수(필터의 개수)
pre_channel_num가 됩니다.29-32줄: 완전연결 계층에 대한 매개변수를 초기화합니다.
35-63줄: 모든 계층을 만듭니다. 풀링 계층의 높이, 너비와 스트라이드의 크기는 모두
2입니다.
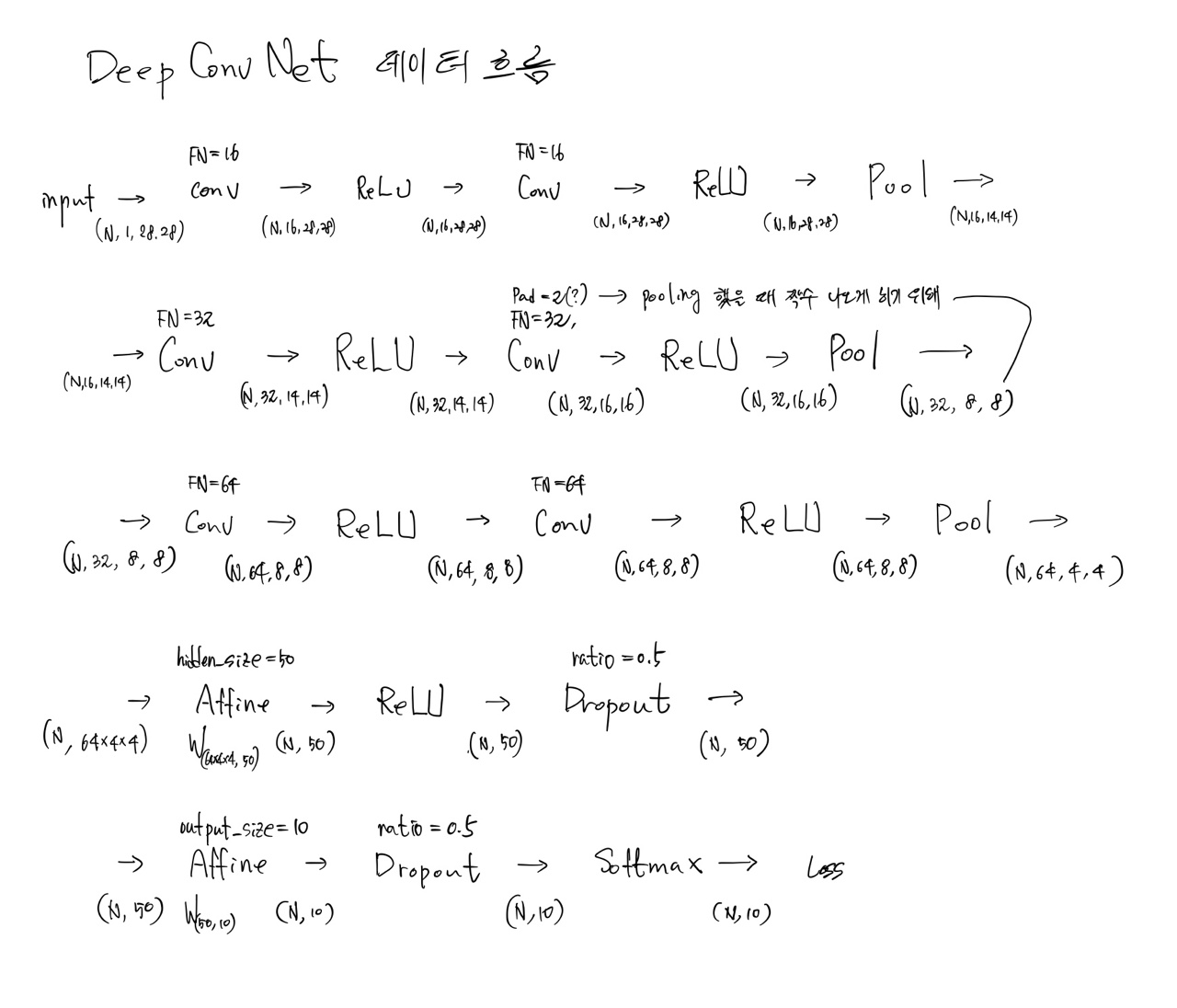
DeepConvNet 데이터 흐름
심층망 학습
1(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
2
3network = DeepConvNet()
4trainer = Trainer(network, x_train, t_train, x_test, t_test,
5 epochs=20, mini_batch_size=100,
6 optimizer='Adam', optimizer_param={'lr': 0.001},
7 evaluate_sample_num_per_epoch=1000)
8trainer.train()
9
10# 매개변수 보관
11network.save_params("deep_convnet_params_dk.pkl")
12print("Saved Network Parameters!")
3줄: 위에서 설명한
DeepConvNet클래스의 인스턴스를 만듭니다.5줄: 에폭 수는 20, 미니배치 크기는 100을 사용합니다.
6줄:
Adam최적화 방법을 사용하며 학습율은0.001을 사용합니다.11줄: 학습을 마친 매개변수를 저장합니다.
Note
DeepConvNet을 학습하는데 3 ~ 4 시간 이상이 걸릴 수도 있습니다. 미리 학습된 매개변수가 ch08/deep_convnet_params.pkl 파일로 있습니다. 필요하면 활용하시기 바랍니다.
딥러닝의 초기 역사
이미지넷
AlexNet 2
2012년에 발표된 AlexNet은 딥러닝 열풍을 일으키는데 큰 역할을 했으며, 합성곱 계층과 풀링 계층을 거듭하며 마지막으로 완전연결 계층을 거쳐 결과를 출력하는 네트워크입니다.
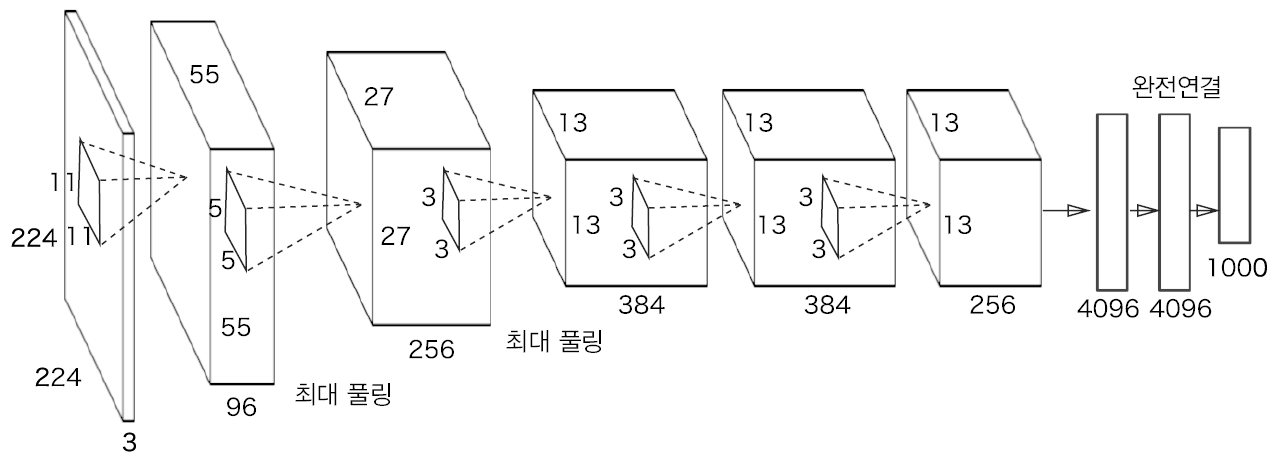
AlexNet 구성
활성화 함수로 ReLU를 사용합니다.
LRN Local Response Normalization이라는 국소적 정규화 계층을 이용합니다.
드롭아웃을 이용합니다.
VGG 1
VGGNet에서 주목할 점은 3 x 3 필터로 세 차례 컨볼루션 하는 것은 7 x 7 필터로 한 번 컨볼루션 하는 것과 대응된다는 것입니다.
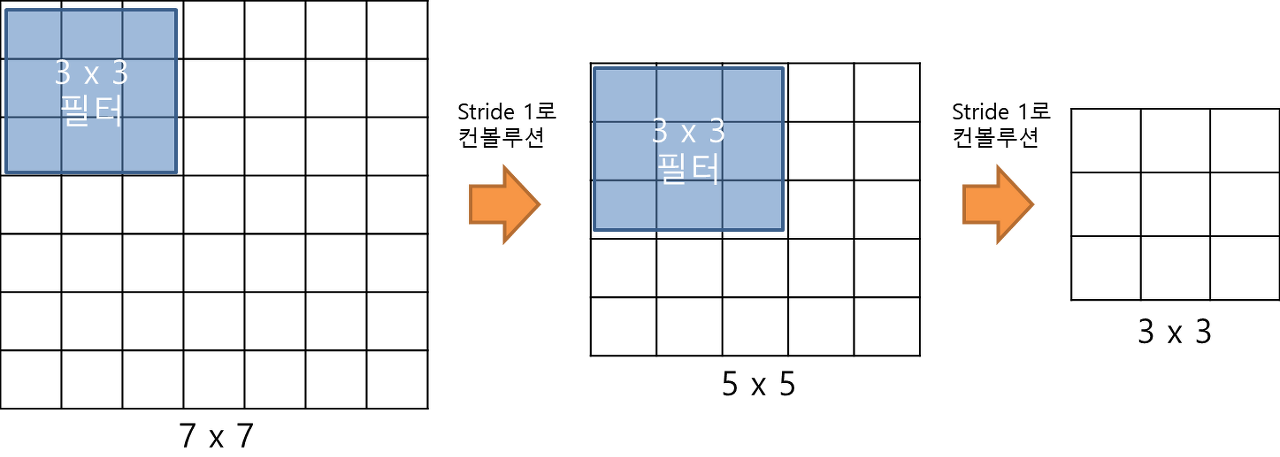
VGG 특성(출처: bskyvision)
3 x 3 필터로 세 차례 컨볼루션을 하는 것이 7 x 7 필터로 한 번 컨볼루션하는 것보다 나은 점은 가중치 또는 파라미터의 갯수가 더 적다는 데 있습니다. 3 x 3 필터가 3개면 총 27개의 가중치를 갖는 반면 7 x 7 필터는 49개의 가중치를 갖습니다. 가중치가 적다는 것은 그만큼 훈련시켜야할 것의 갯수가 적어지는 것이므로 학습의 속도가 빨라지게 됩니다. 뿐만아니라 층의 갯수가 늘어나면서 특성에 비선형성을 더 증가시키기 때문에 특성이 점점 더 유용해집니다.
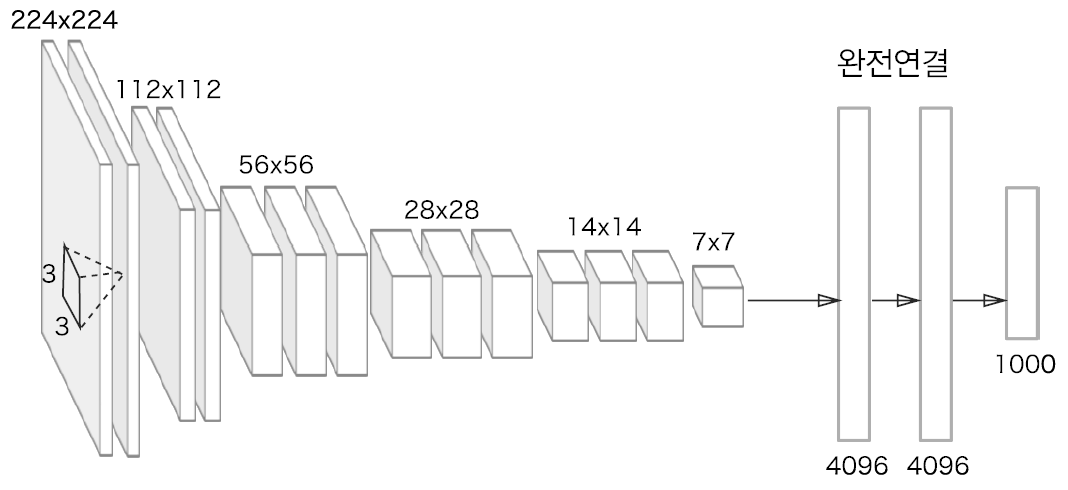
VGG
전처리: 모든 픽셀에서 학습에 사용된 데이터들의 평균값을 뺍니다. 1
13개의 합성곱 계층으로 이루어지고, 합성곱 계층의 패딩은 모두 1 픽셀, 스트라이드도 모두 1 픽셀 입니다.
3개의 완전연결 계층으로 이루어집니다.
5개의 최대 풀링은 모두 2x2 필터와 스트라이드는 모두 2 픽셀을 사용합니다.
모든 은닉층 다음에는 ReLU 계층이 존재합니다. 즉, 13개 합성곱 + ReLU, 2개 완전연결 계층(4096) + ReLU로 구성됩니다.
마지막 완전연결 계층(1000) + 소프트맥스 활성화함수가 연결됩니다.
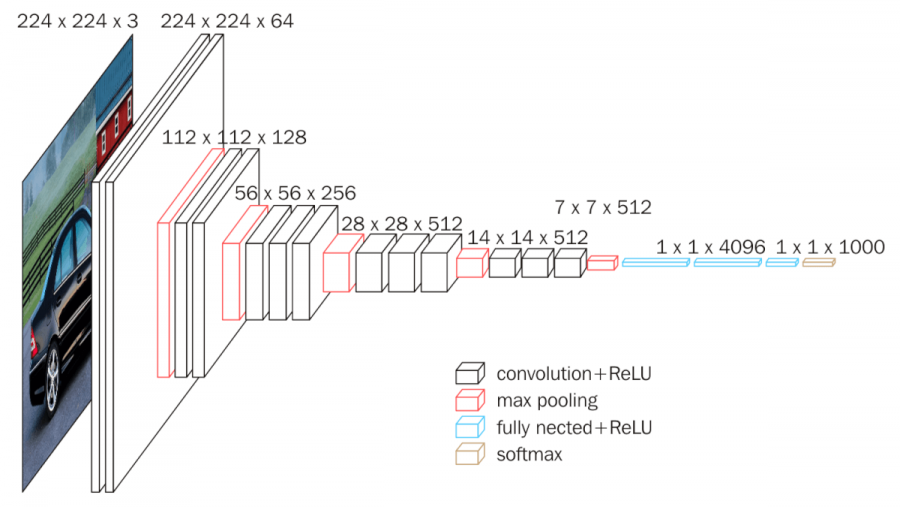
VGG16 구조(출처: bskyvision)
입력: 224x224x3, 합성곱 계층의 패딩은 모두 1
1층: 64개의 3x3x3 필터 합성곱 stride=1, 출력은 224x224x64
2층: 64개의 3x3x3 필터 합성곱 stride=1, 출력은 224x224x64
풀링층: 2x2 필터 stride=2, 출력은 112x112x64
3층: 128개의 3x3x64 필터 합성곱, 출력은 112x112x128
4층: 128개의 3x3x128 필터 합성곱, 출력은 112x112x128
풀링층: 2x2 필터 stride=2, 출력은 56x56x128
5층: 256개의 3x3x128 필터 합성곱, 출력은 56x56x256
6층: 256개의 3x3x256 필터 합성곱, 출력은 56x56x256
7층: 256개의 3x3x256 필터 합성곱, 출력은 56x56x256
풀링층: 2x2 필터 stride=2, 출력은 28x28x256
8층: 512개의 3x3x256 필터 합성곱, 출력은 28x28x512
9층: 512개의 3x3x512 필터 합성곱, 출력은 28x28x512
10층: 512개의 3x3x512 필터 합성곱, 출력은 28x28x512
풀링층: 2x2 필터 stride=2, 출력은 14x14x512
11층: 512개의 3x3x512 필터 합성곱, 출력은 14x14x512
12층: 512개의 3x3x512 필터 합성곱, 출력은 14x14x512
13층: 512개의 3x3x512 필터 합성곱, 출력은 14x14x512
풀링층: 2x2 필터 stride=2, 출력은 7x7x512
14층: 7x7x512 입력, 4096 뉴런과 완전연결, 출력은 4096
드롭아웃=0.5
15층: 4096개 입력, 4096 뉴런과 완전연결, 출력은 4096
드롭아웃=0.5
16층: 4096개 입력, 1000 뉴런과 완전연결, 출력은 1000
소프트맥스 활성화
GoogLeNet
ResNet
스킵 연결 skip connection