오차역전파
계산 그래프
계산 그래프(computational graph)란 계산 과정을 그래프로 나타낸 것입니다. 그래프는 노드(node)와 에지(edge)로 표현됩니다. 에지는 노드 사이의 직선을 나타냅니다.
계산 그래프로 나타내기
계산 그래프는 계산 과정을 노드와 화살표(에지)로 표현합니다. 노드는 원으로 표기하고 원 안에 연산 내용을 적습니다. 계산 결과는 화살표 위에 적어 왼쪽에서 오른쪽으로 전해지게 합니다.

노드에는 연산만을 나타내도록 표현할 수 있습니다.
문제1: 수퍼에서 1개에 100원인 사과를 2개 샀습니다. 이때 지불 금액을 구하세요. 단 소비세가 10% 부과됩니다.
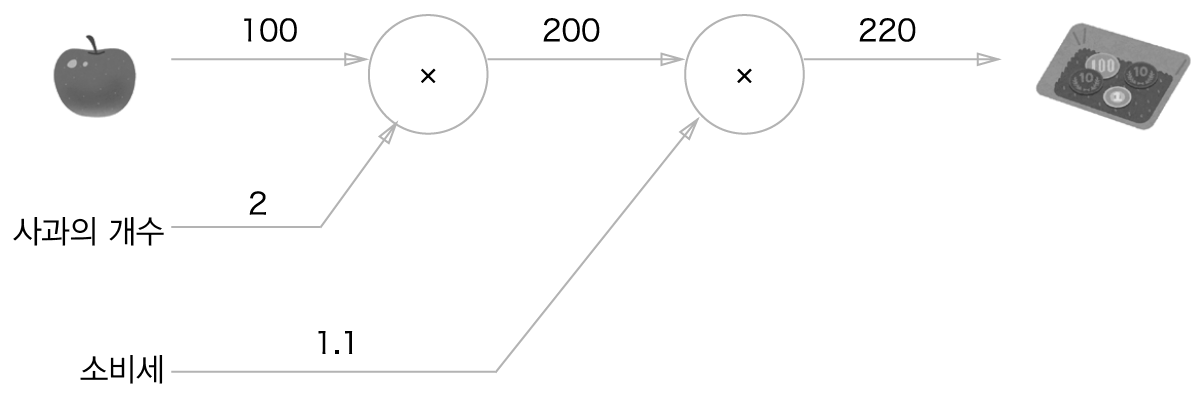
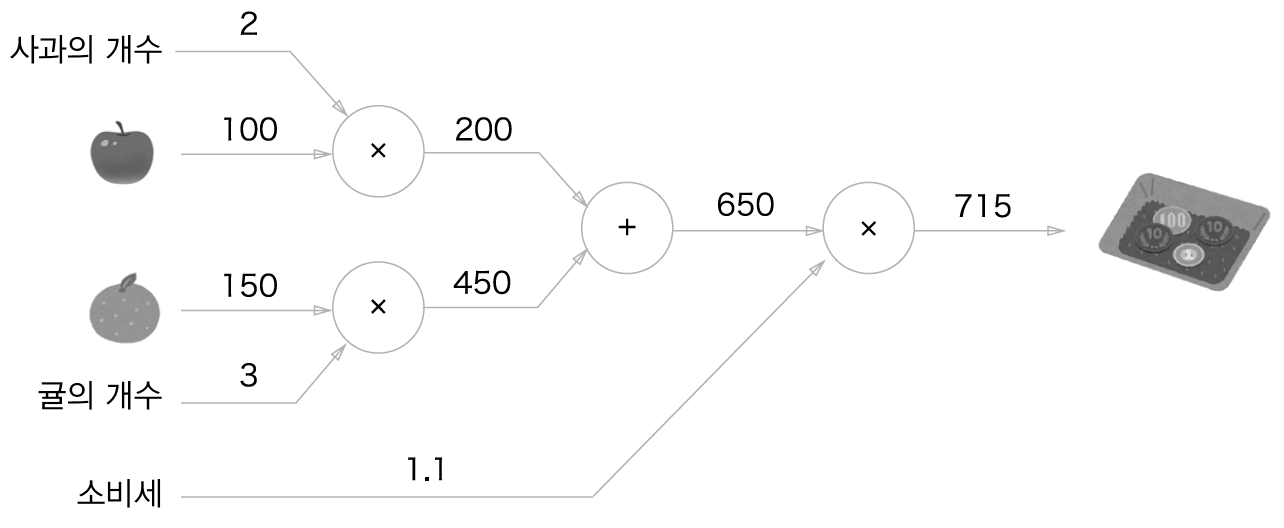
문제2: 수퍼에서 1개에 100원인 사과를 2개, 귤을 3개 샀습니다. 사과는 1개에 100원, 귤은 1개 150원입니다. 소비세가 10%일 때 지불 금액을 구하세요.
국소적 계산
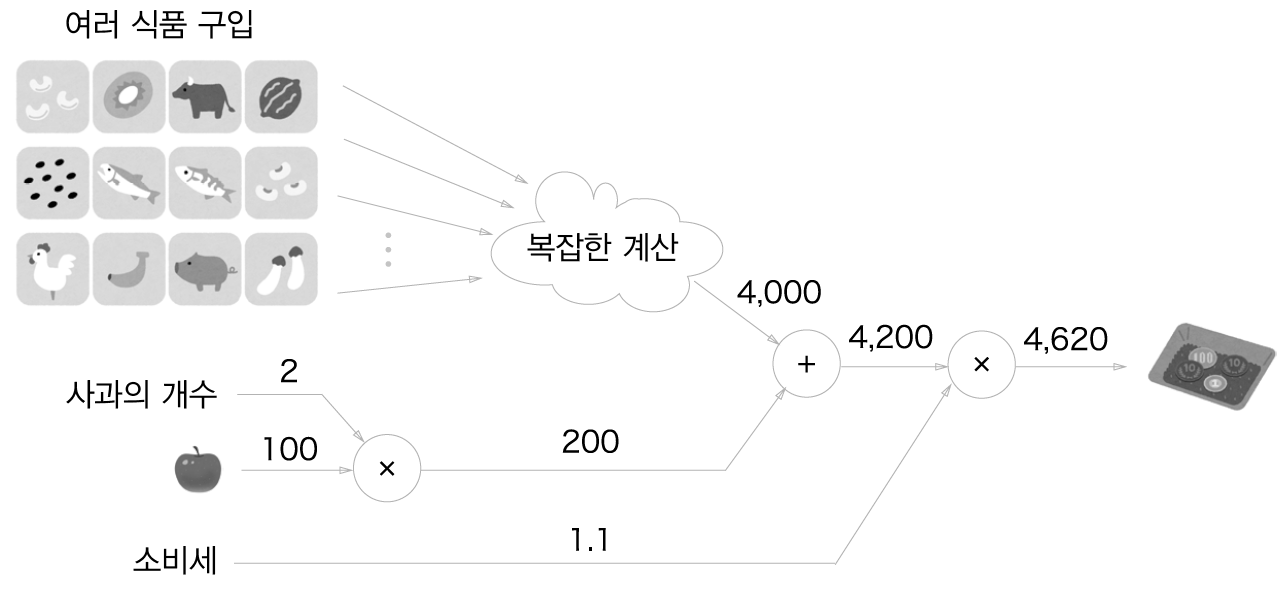
국소적 계산이란 전체에 어떤 일이 벌어지든 상관없이 자신과 관계된 정보만으로 결과를 출력하는 것을 말합니다.
수퍼에서 사과 2개를 포함하여 여러 식품을 구입하는 경우를 생각해봅니다. 여러 식품을 구입하여 총 금액이 4000원이 되었습니다. 사과와 구입한 금액을 더하는 계산은 다른 식품들이 어떻게 계산되었는지 상관하지 않고 사과값과 4000원을 더하면 된다는 것이 국소적 계산입니다.
계산 그래프 장점
계산 그래프의 장점은 앞에서 살펴본 바와 같이 국소적 계산입니다. 아무리 복잡한 계산이더라도 각 노드에서는 단순한 계산에 집중할 수 있다는 것입니다. 또 다른 이점은 중간 계산 결과를 저장할 수 있다는 것입니다. 가장 큰 이유 중 하나는 역전파를 이용해 미분을 효율적으로 계산할 수 있다는 점에 있습니다.
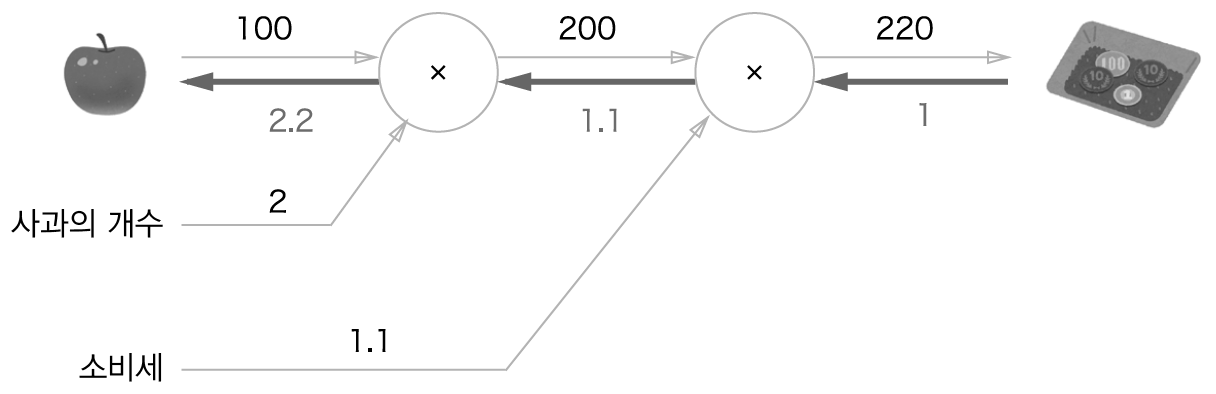
사과 가격에 대한 지불 금액의 미분값은 계산 그래프에서 역전파를 하면 구할 수 있습니다. 역전파는 순전파와 반대 방향의 화살표(굵은 선)로 그립니다. 이 전파는 국소적 미분을 전달하고 그 미분값은 화살표 아래에 적습니다. 이 예에서는 역전파는 오른쪽에서 왼쪽으로 1 -> 1.1 -> 2.2 순으로 전달합니다. 이 결과로 사과 가격에 대한 지불 금액의 미분값은 2.2라 할 수 있습니다. 사과가 h원 오르면 지불 금액은 근사적으로 약 2.2h원 오르게 됩니다.
연쇄법칙
역전파는 국소적인 미분을 순방향과는 반대인 오른쪽에서 왼쪽으로 전달합니다. 국소적인 미분을 전달하는 원리는 연쇄법칙(chain rule)에 의한 것입니다.
계산 그래프의 역전파
\(y=f(x)\) 의 역전파를 그림으로 나타낸 것입니다.
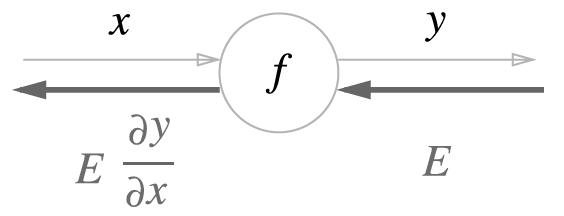
역전파의 계산 절차는 \(E\)에 노드의 국소적 미분(\(\partial y/\partial x\))를 곱한 후 다음 노드로 전달하는 것입니다.
연쇄법칙
함수 \(z = (x+y)^2\) 대해서 예를 들어 봅니다.
연쇄법칙과 계산 그래프
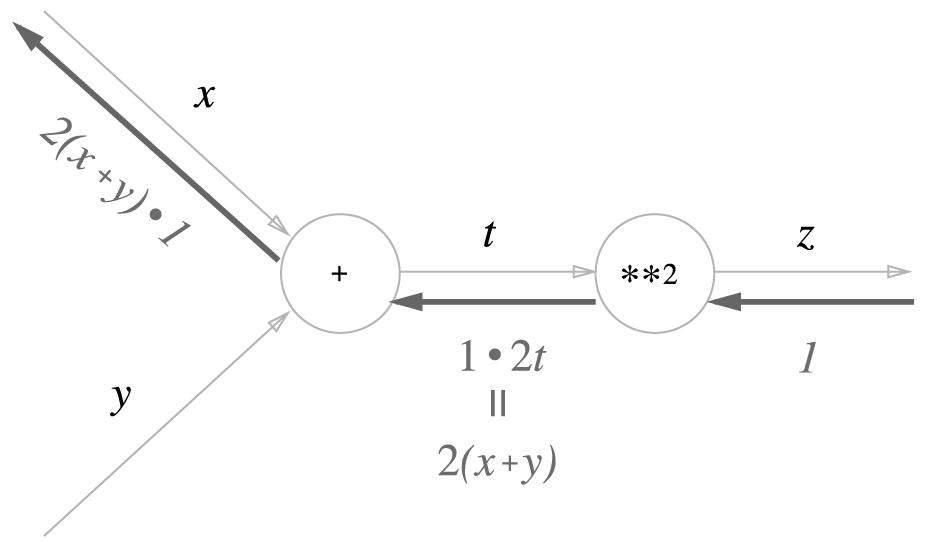
위의 예제를 계산 그래프로 나타내면 다음과 같습니다. 거듭 제곱 계산을 **2 노드로 나타냈습니다.
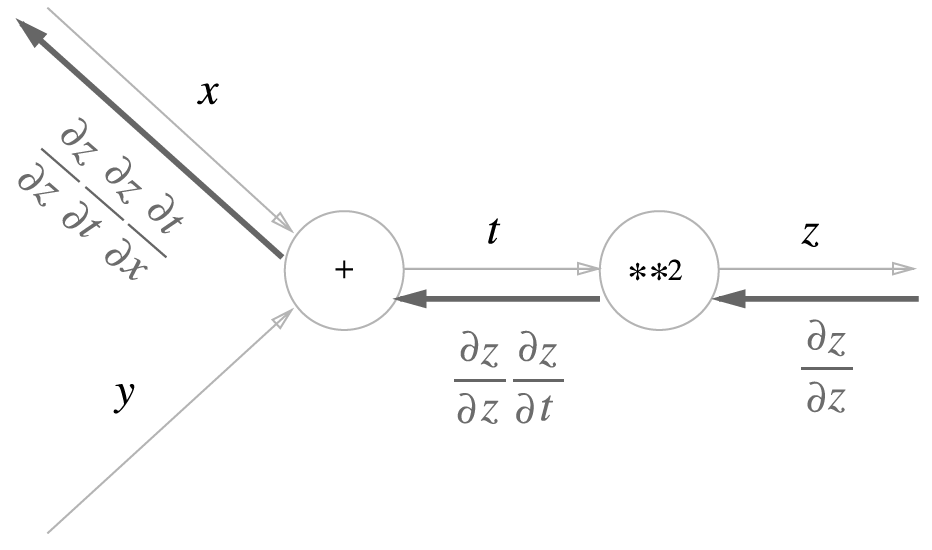
역전파의 맨 왼쪽에 나타나는 값은 \(x\)에 대한 \(z\)의 미분이라는 것을 알 수 있습니다.
역전파
여기서는 +, x 등의 연산을 예로 들어 역전파의 구조를 알아봅니다.
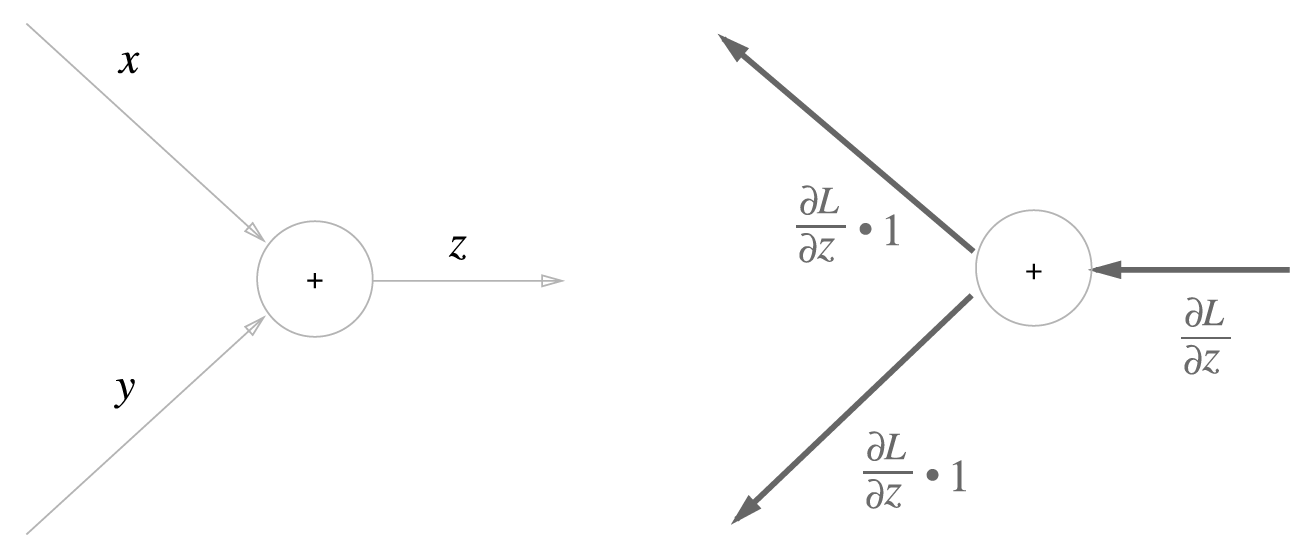
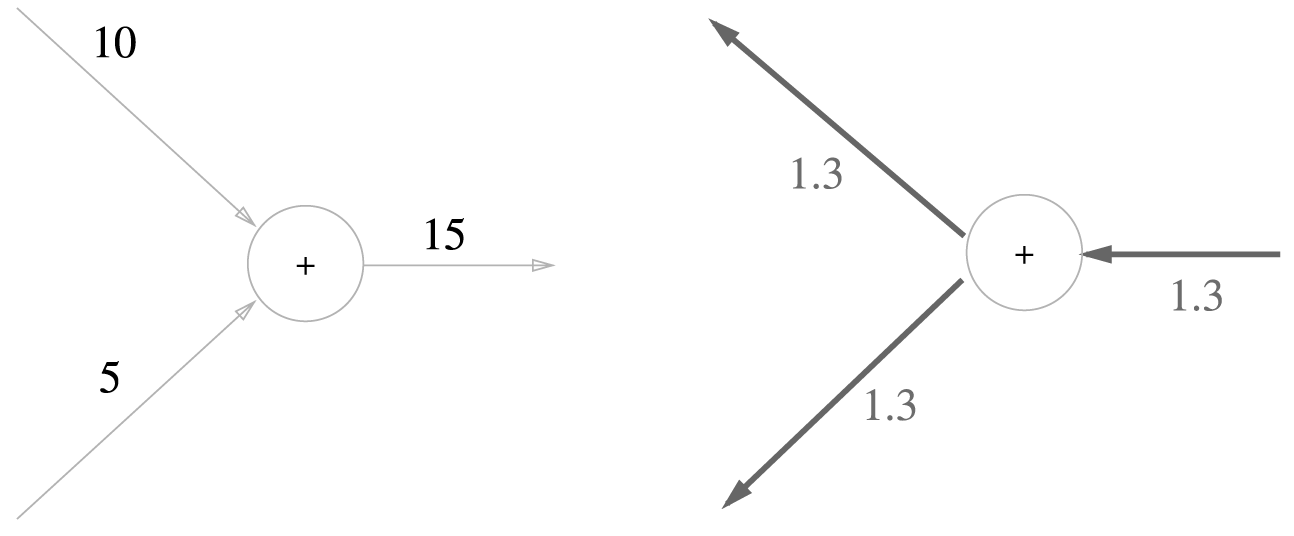
덧셈 노드
\(z=x+y\) 식의 역전파에 대해서 알아봅니다. 각 변수에 대한 편미분은 다음과 같습니다.
계산 그래프로 그리면 다음과 같습니다.
구체적으로 10 + 5 = 15 라는 계산이 있고 상류에서 1.3이라는 값이 넘어올 때 계산그래프를 그리면 다음과 같습니다.
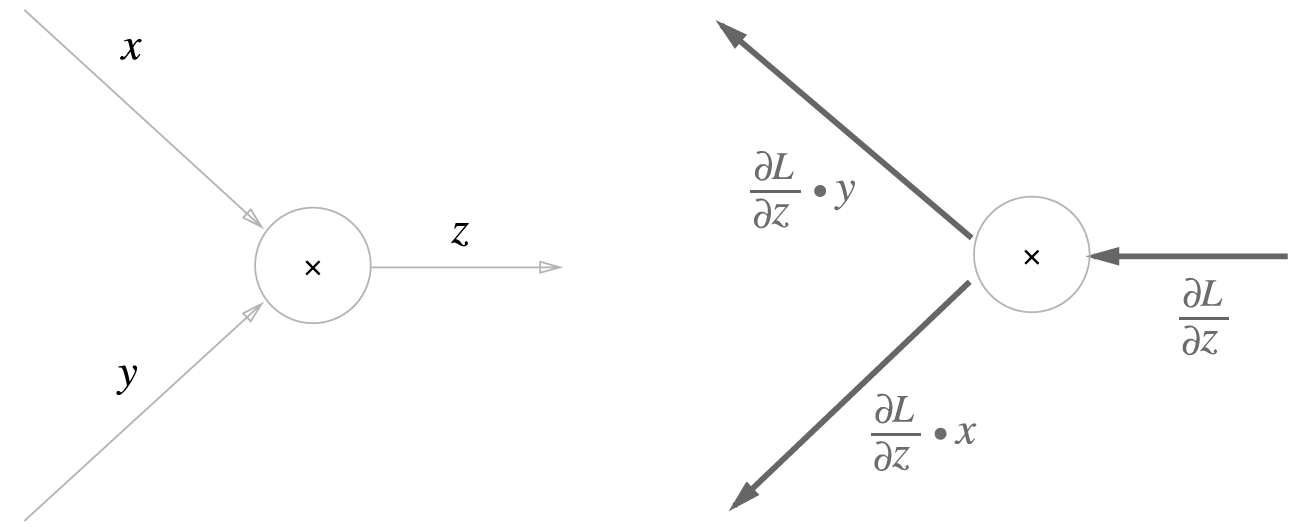
곱셈 노드
\(z = xy\) 라는 식의 역전파를 생각해봅니다. 이 식의 편미분은 다음과 같습니다.
이것의 계산 그래프는 다음과 같습니다.
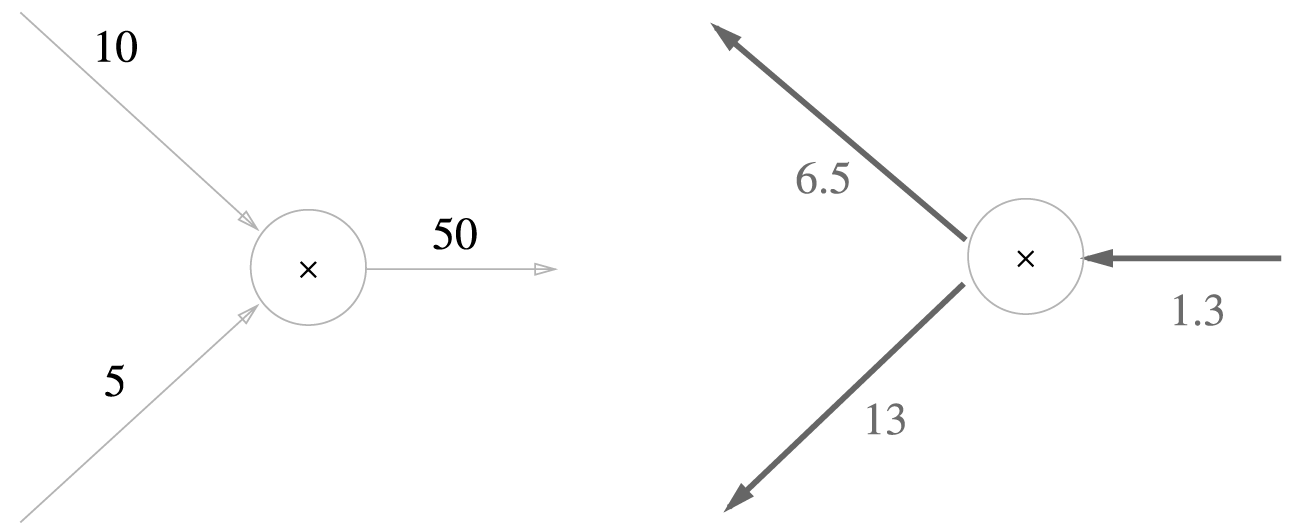
예를 들어서 \(10 \times 5 = 50\) 이라는 계산에 대해서 상류로부터 1.3이 넘어온다고 하면 계산 그래프는 다음과 같습니다.
사과 구매 예제
사과 구매 예제에 대한 역전파를 살펴봅니다.
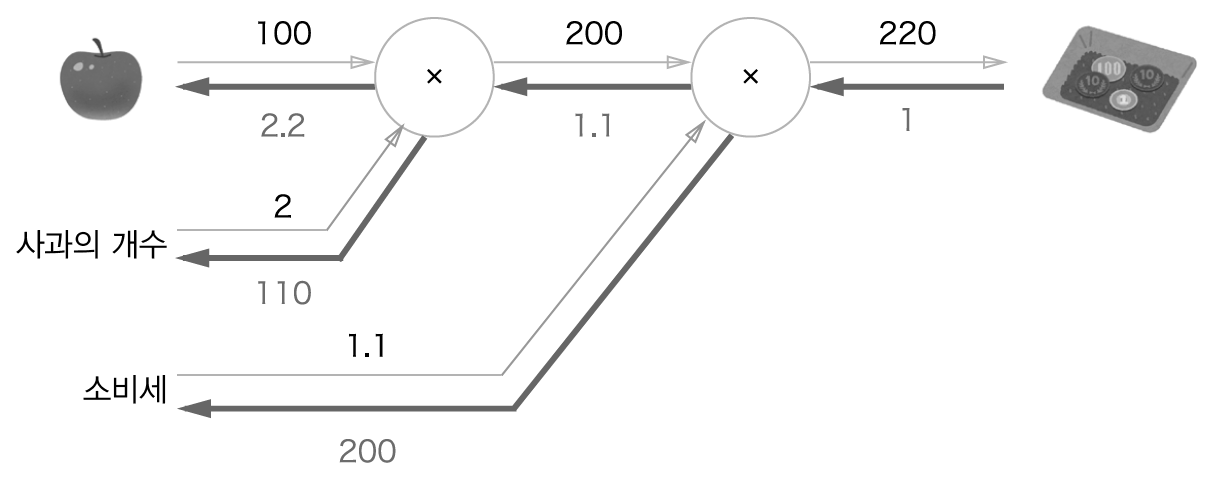
사과와 귤에 대한 역전파입니다. 빈 칸을 채워보세요.
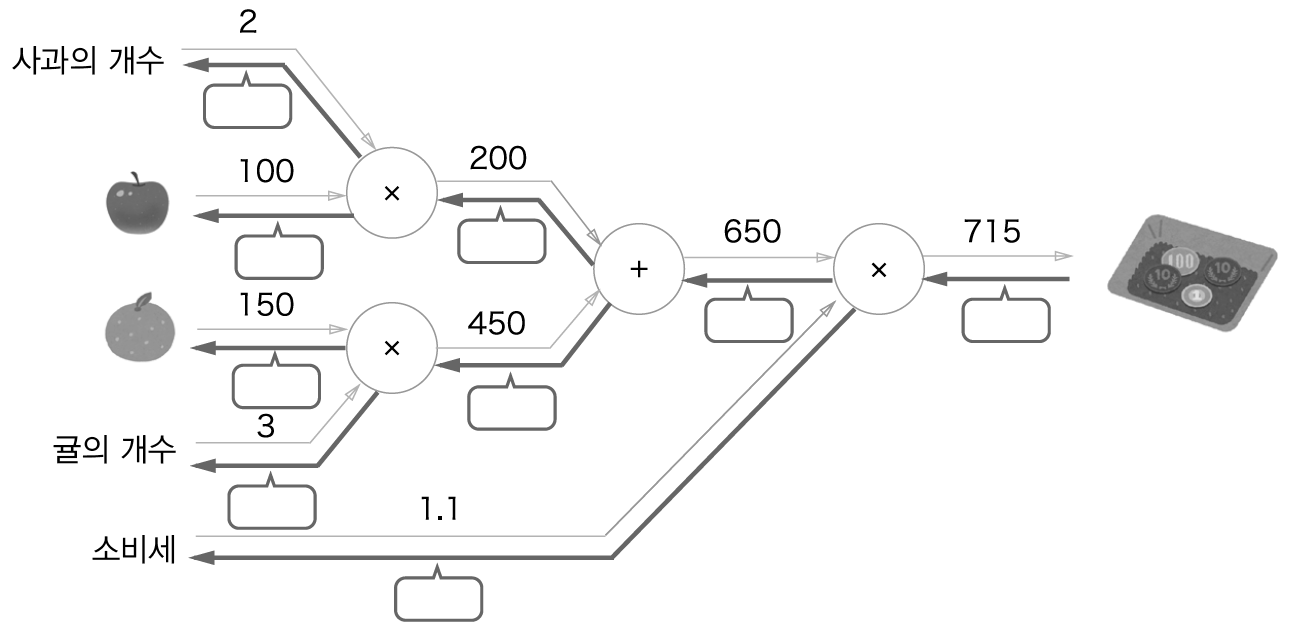
정답
단순 계층 구현
여기서는 계산 그래프 곱셈 노드를 MulLayer, 덧셈노드를 AddLayer 라는 이름의 클래스로 구현합니다. 모든 계층은 순전파 forward(), 역전파 backward()라는 공통 메소드를 갖도록 합니다. 순전파는 연산 결과를 반환하고 역전파 메소드는 앞에서 계산된 미분을 이용해서 연산된 값들을 반환합니다.
곱셈 계층
In [1]: class MulLayer:
...: def __init__(self):
...: self.x = None
...: self.y = None
...:
...: def forward(self, x, y):
...: self.x = x
...: self.y = y
...: out = x * y
...: return out
...:
...: def backward(self, dout):
...: dx = dout * self.y
...: dy = dout * self.x
...: return dx, dy
...:
forward() 는 x, y 를 인수로 받아 곱한 값을 반환하고, backward() 는 앞에서 넘어온 미분(dout)에 순전파 때의 값을 서로 바꿔 곱한 후 반환합니다.
MulLayer를 이용해서 사과 2개를 구매하는 상황을 구현합니다.
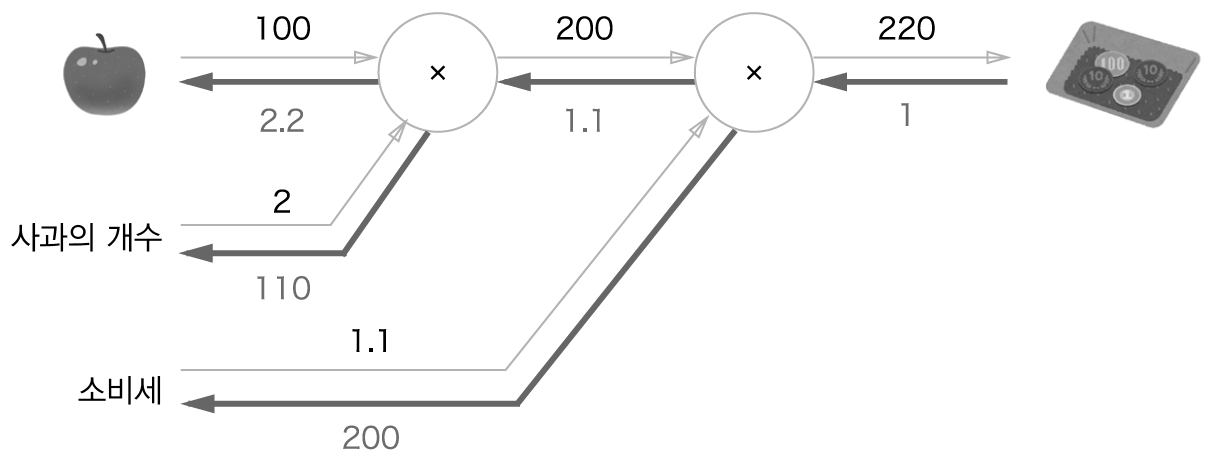
다음은 순전파 계산 결과입니다.
In [2]: apple = 100
...: apple_num = 2
...: tax = 1.1
...:
...: mul_apple_layer = MulLayer()
...: mul_tax_layer = MulLayer()
...:
...: apple_price = mul_apple_layer.forward(apple, apple_num)
...: price = mul_tax_layer.forward(apple_price, tax)
...:
...: print(price)
...:
220.00000000000003
다음은 역전파(backward) 계산 결과 입니다.
In [3]: dprice = 1
...: dapple_price, dtax = mul_tax_layer.backward(dprice)
...: dapple, dapple_num = mul_apple_layer.backward(dapple_price)
...:
...: print(dapple, dapple_num, dtax)
...:
2.2 110.00000000000001 200
backward() 호출 순서는 forward() 와 반대입니다. backward() 가 받는 인수는 순전파 출력에 대한 미분입니다.
덧셈 계층
덧셈 노드에 대한 구현입니다.
In [4]: class AddLayer:
...: def __init__(self):
...: pass
...:
...: def forward(self, x, y):
...: out = x + y
...: return out
...:
...: def backward(self, dout):
...: dx = dout * 1
...: dy = dout * 1
...: return dx, dy
...:
__init__ 메소드에서는 x, y를 사용하지 않기 때문에 초기화할 필요가 없습니다. backward() 메소드는 앞에서 계산된 미분(dout)을 그대로 반환합니다.
덧셈과 곱셈 계층을 이용하여 사과 2개와 귤 3개를 구매하는 상황을 구현합니다.
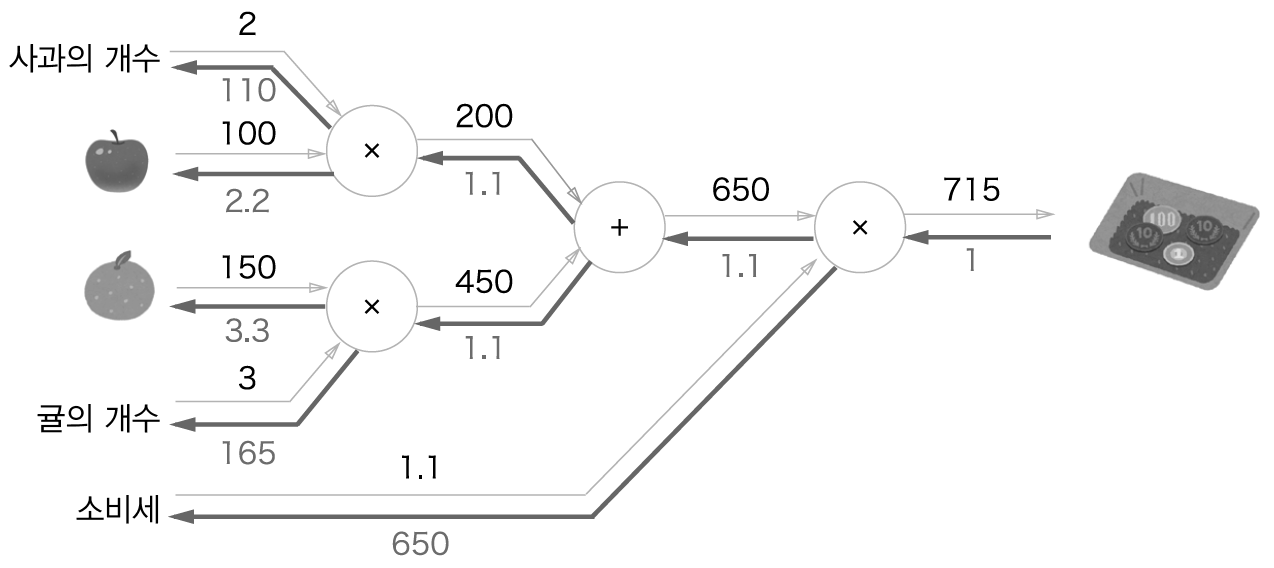
In [5]: apple = 100
...: apple_num = 2
...: orange = 150
...: orange_num = 3
...: tax = 1.1
...:
...: mul_apple_layer = MulLayer()
...: mul_orange_layer = MulLayer()
...: add_apple_orange_layer = AddLayer()
...: mul_tax_layer = MulLayer()
...:
...: apple_price = mul_apple_layer.forward(apple, apple_num)
...: orange_price = mul_orange_layer.forward(orange, orange_num)
...: all_price = add_apple_orange_layer.forward(apple_price, orange_price)
...: price = mul_tax_layer.forward(all_price, tax)
...:
...: dprice = 1
...: dall_price, dtax = mul_tax_layer.backward(dprice)
...: dapple_price, dorange_price = add_apple_orange_layer.backward(dall_price)
...: dorange, dorange_num = mul_orange_layer.backward(dorange_price)
...: dapple, dapple_num = mul_apple_layer.backward(dapple_price)
...:
...: print(price)
...: print(dapple_num, dapple, dorange, dorange_num, dtax)
...:
715.0000000000001
110.00000000000001 2.2 3.3000000000000003 165.0 650
활성화함수 계층 구현
활성화함수 ReLU와 Sigmoid 계층을 구현해봅니다.
ReLU 계층
ReLU 식은 다음과 같습니다.
편미분은 다음과 같습니다.
계산그래프는 다음과 같습니다.
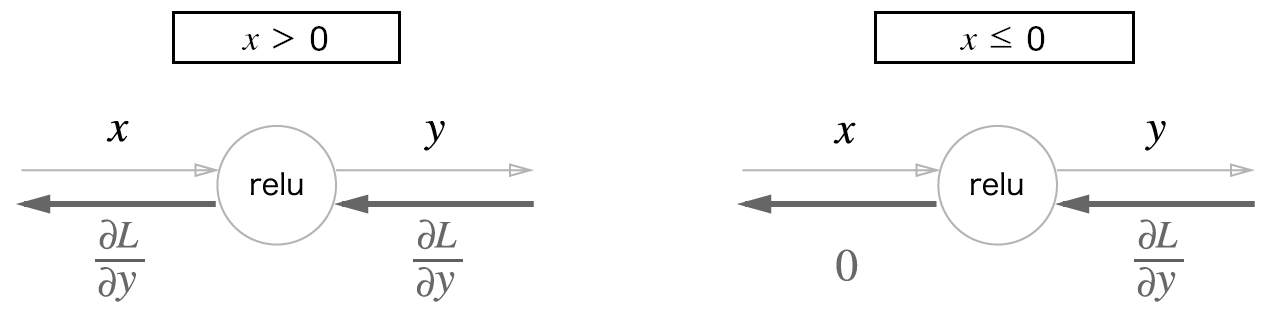
파이썬으로 구현해봅니다.
In [6]: class Relu:
...: def __init__(self):
...: self.mask = None
...:
...: def forward(self, x):
...: self.mask = (x <= 0)
...: out = x.copy()
...: out[self.mask] = 0
...: return out
...:
...: def backward(self, dout):
...: dout[self.mask] = 0
...: dx = dout
...: return dx
...:
self.mask는 논리형 배열입니다.
In [7]: import numpy as np
...:
...: x = np.array([[1.0, -0.5], [-2.0, 3.0]])
...: print(x)
...: mask = (x <= 0)
...: print(mask)
...:
[[ 1. -0.5]
[-2. 3. ]]
[[False True]
[ True False]]
시그모이드 계층
시그모이드 함수는 다음과 같습니다.
계산그래프는 다음과 같습니다.
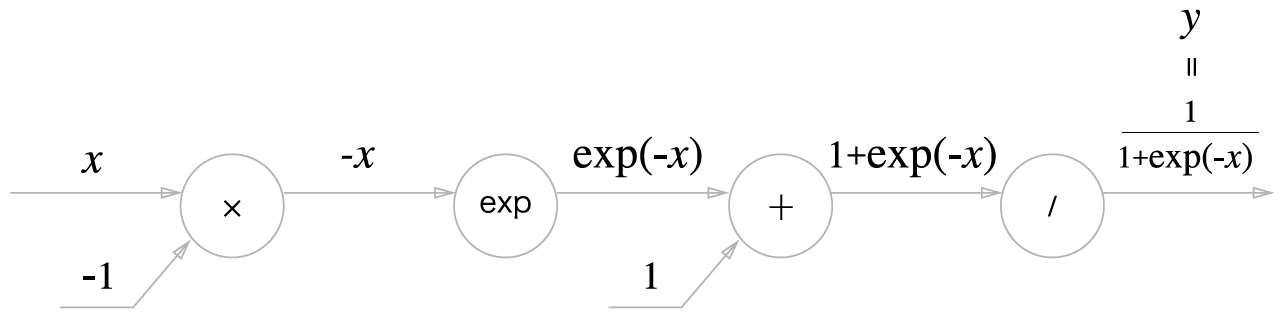
역전파의 흐름을 오른쪽부터 단계별로 살펴봅니다.
- 1 단계
/노드
\(y = 1/x\) 를 미분하면 다음과 같습니다.
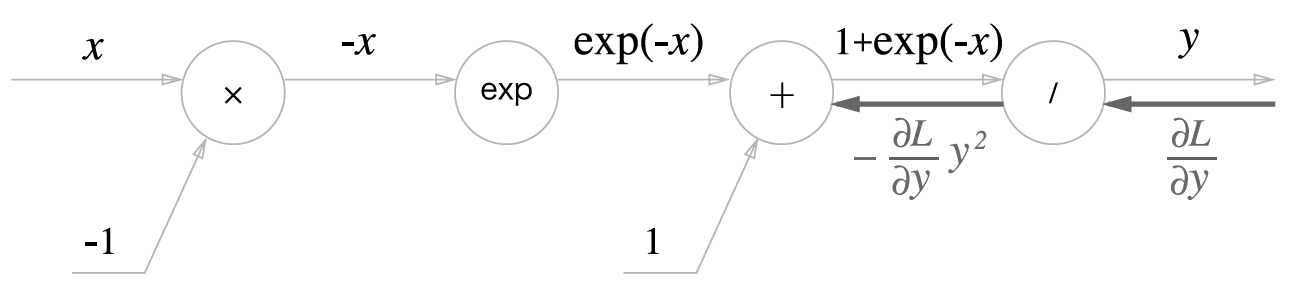
- 2 단계
+노드
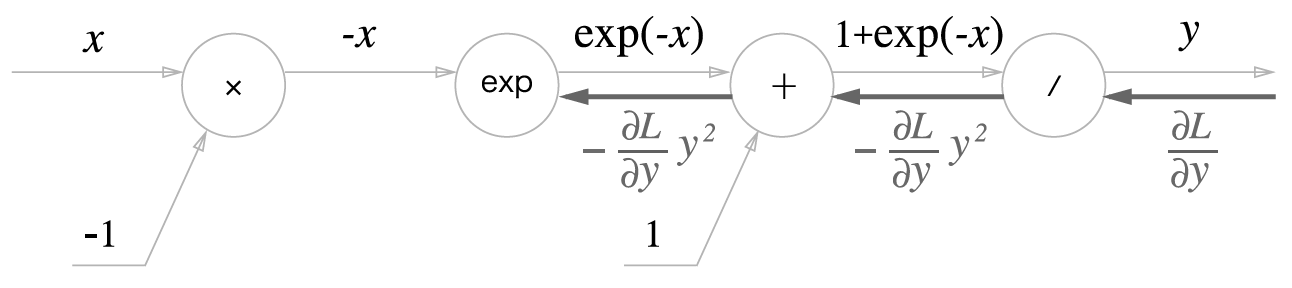
- 3 단계
exp노드
\(y = \exp(x)\) 를 미분하면 다음과 같습니다.
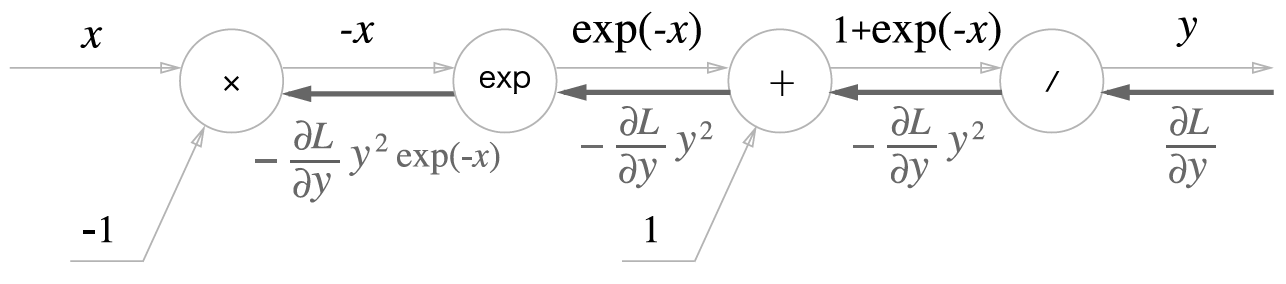
- 4 단계
x노드
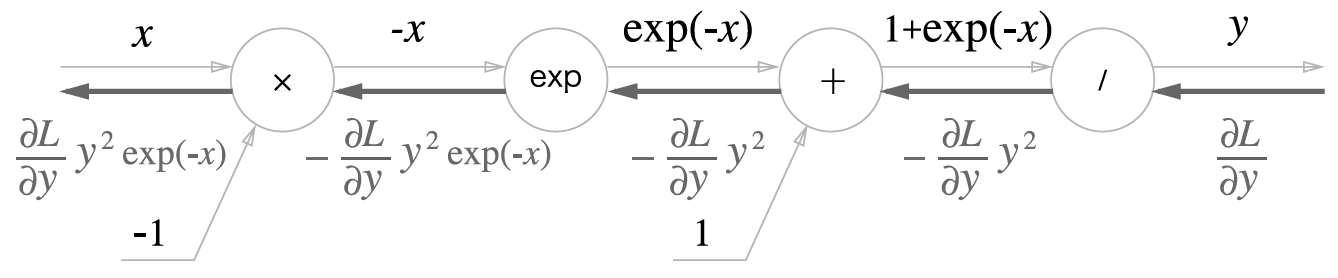
역전파의 최종 출력은 \(\frac{\partial L}{\partial y} y^2 \exp(-x)\) 입니다.
다음은 중간 단계를 생략한 간단한 버전입니다.
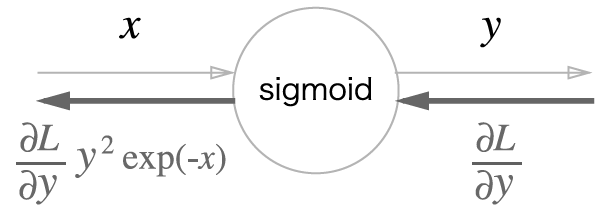
\(\frac{\partial L}{\partial y} y^2 \exp(-x)\)을 정리하면 다음과 같습니다.
즉 다음과 같이 표현됩니다.
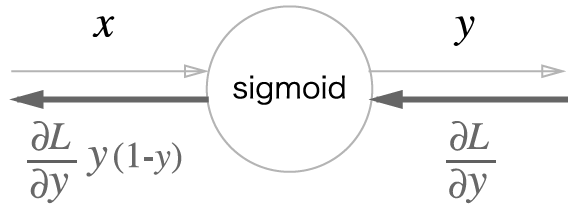
시그모이드 구현입니다.
In [8]: class Sigmoid:
...: def __init__(self):
...: self.out = None
...:
...: def forward(self, x):
...: out = sigmoid(x)
...: self.out = out
...: return out
...:
...: def backward(self, dout):
...: dx = dout * (1.0 - self.out) * self.out
...:
...: return dx
...:
Affine/Softmax 계층 구현
Affine 계층
\(AX + B\) 를 어파인 변환 affine transformation이라고 합니다. 이러한 변환을 처리하는 계층을 어파인 계층이라고 부릅니다.
다음 변환에 대해서 살펴봅니다.
일차원 벡터 \(X\)
먼저 \(X\)가 일차원 벡터, 즉 배치가 아닌 경우를 살펴봅니다.
예를 들어 \(X, W, B\) 의 크기가 각각 (2,), (2, 3), (3,)인 배열에 대해서 살펴봅니다.
In [9]: X = np.random.rand(2)
...: W = np.random.rand(2, 3)
...: B = np.random.rand(3)
...:
...: Y = np.dot(X, W) + B
...:
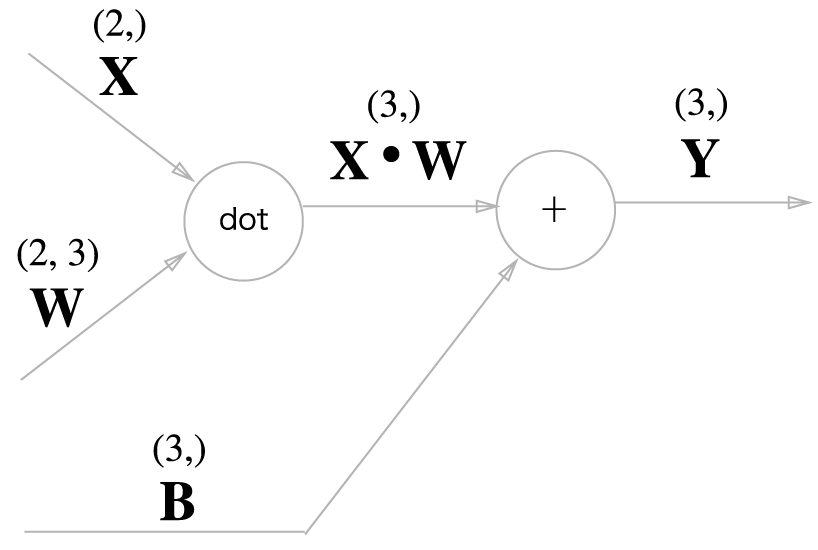
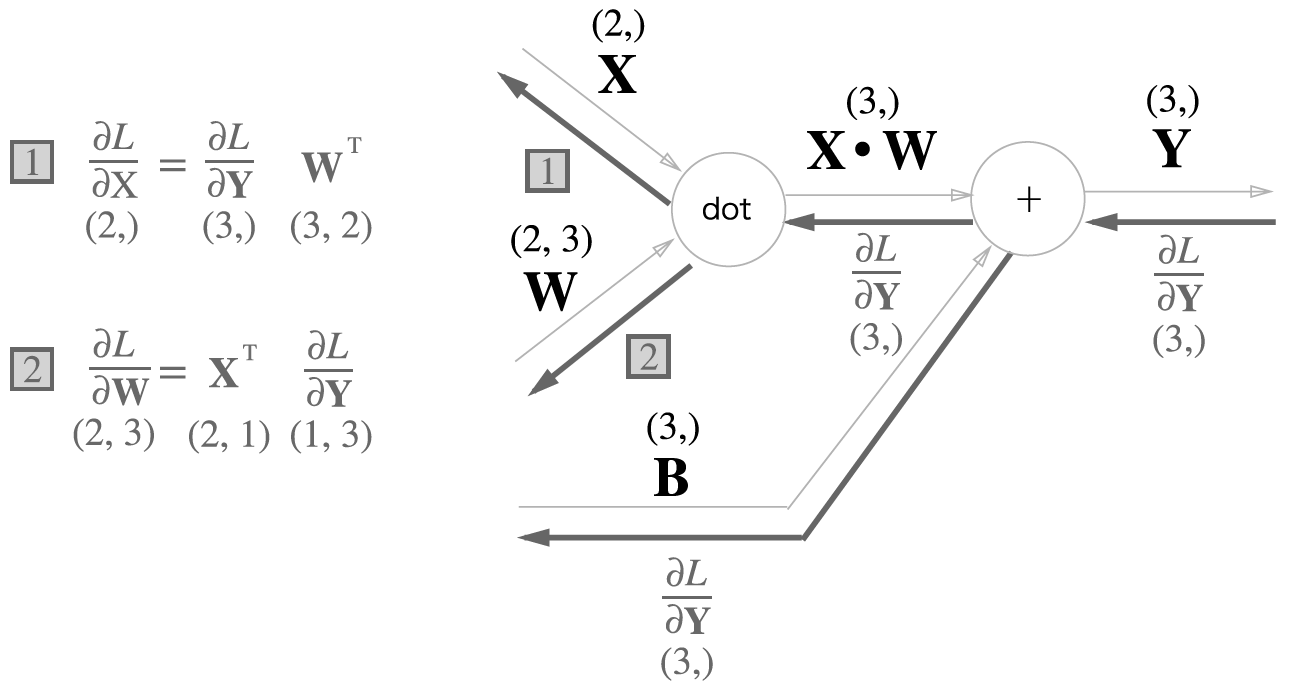
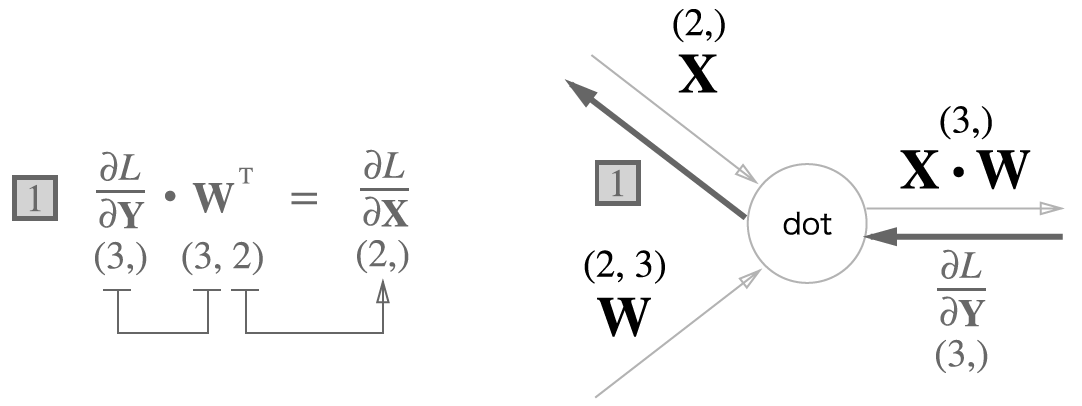
행렬곱 노드
배치용 Affine 계층
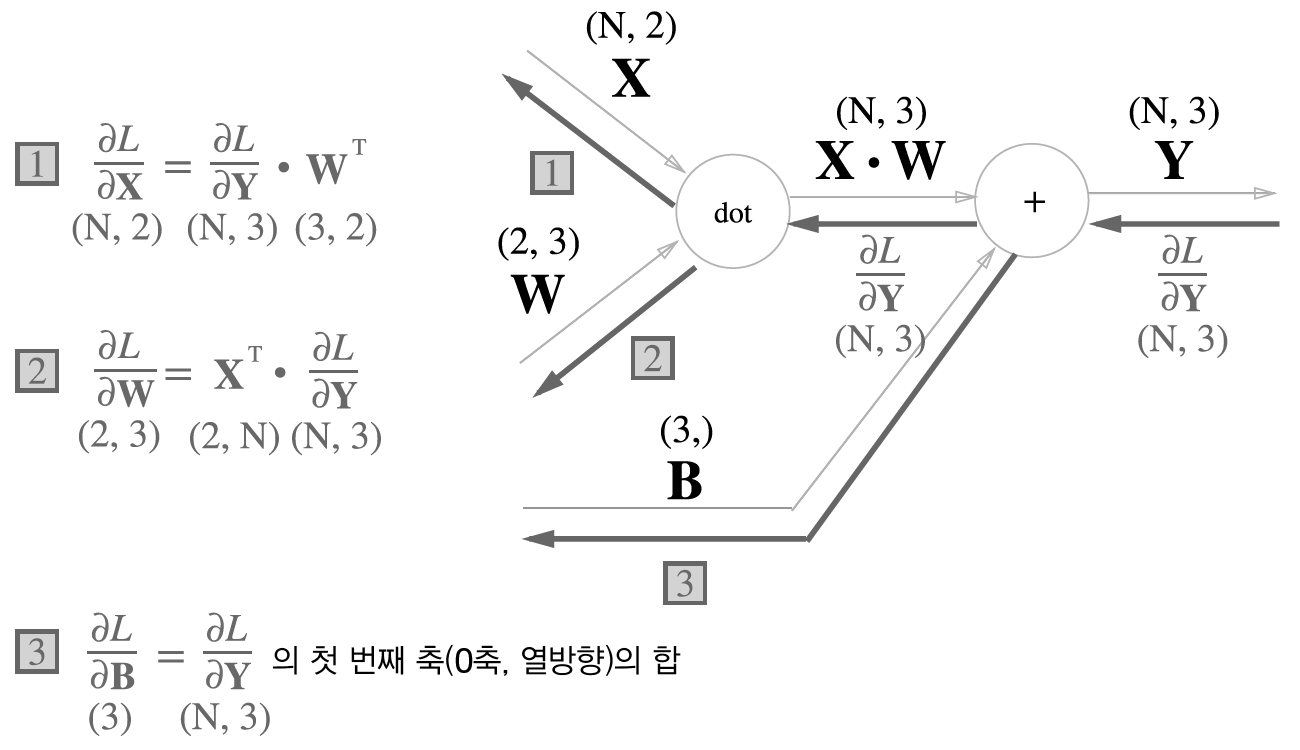
여기서 \(Y\) 는 (N, 3), \(X\) 는 (N, 2), \(W\) 는 (2, 3)입니다. \(L\)은 스칼라 함수입니다.
여기서 \(\dfrac{\partial y_{i2}}{\partial w_{11}} = \dfrac{\partial y_{i3}}{\partial w_{11}} = 0\) 입니다. \(i=1, 2, \ldots, N\) 입니다.
마찬가지로 \(\dfrac{\partial y_{i2}}{\partial w_{21}} = \dfrac{\partial y_{i3}}{\partial w_{21}} = 0\) 입니다. \(i=1, 2, \ldots, N\) 입니다.
입니다. 따라서
그러므로
다음은 \(\partial L / \partial B\)를 계산해 봅니다.
라고 하면
따라서
In [10]: class Affine:
....: def __init__(self, W, b):
....: self.W =W
....: self.b = b
....:
....: self.x = None
....: self.original_x_shape = None
....: # 가중치 매개변수 미분
....: self.dW = None
....: self.db = None
....:
....: def forward(self, x):
....: # 텐서 입력시
....: self.original_x_shape = x.shape
....: x = x.reshape(x.shape[0], -1)
....: self.x = x
....:
....: out = np.dot(self.x, self.W) + self.b
....:
....: return out
....:
....: def backward(self, dout):
....: dx = np.dot(dout, self.W.T)
....: self.dW = np.dot(self.x.T, dout)
....: self.db = np.sum(dout, axis=0)
....:
....: dx = dx.reshape(*self.original_x_shape) # 입력데이터의 형상으로 복구(텐서 표현)
....: return dx
....:
*self.original_x_shape는 튜플을 각각의 인수의 갯수로 풀어 헤쳐서 건네주는 겁니다.
Softmax-with-Loss 계층
소프트맥스 함수는 다음과 같습니다.
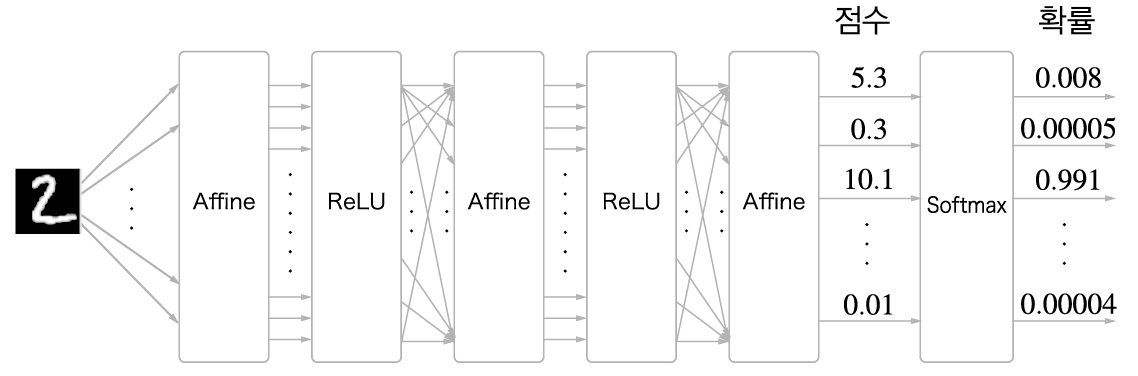
다음은 손글씨 숫자 인식 소프트맥스 계층 출력 그림입니다. 입력이미지가 어파인 계층과 렐루(ReLU) 계층을 통과하여 변환되고 마지막 소프트맥스 계층에 의해서 10개 입력이 정규화되어 출력됩니다.
소프트맥스 계층과 교차 엔트로피 오차도 포함하여 한꺼번에 구현합니다. 이 그림에서는 출력이 3개라고 가정했습니다.
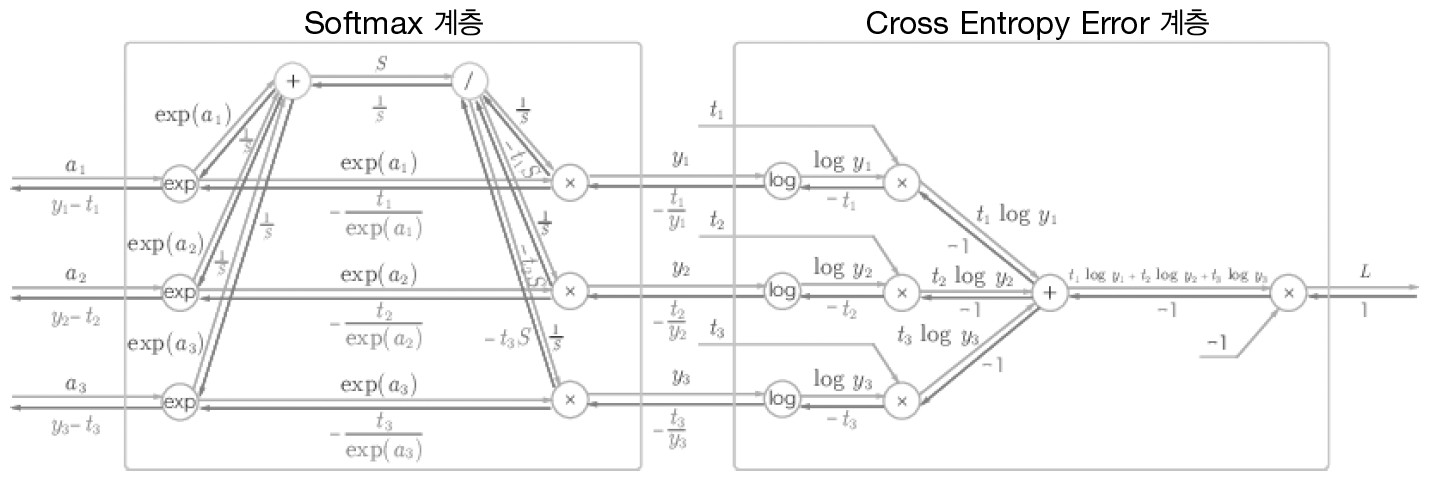
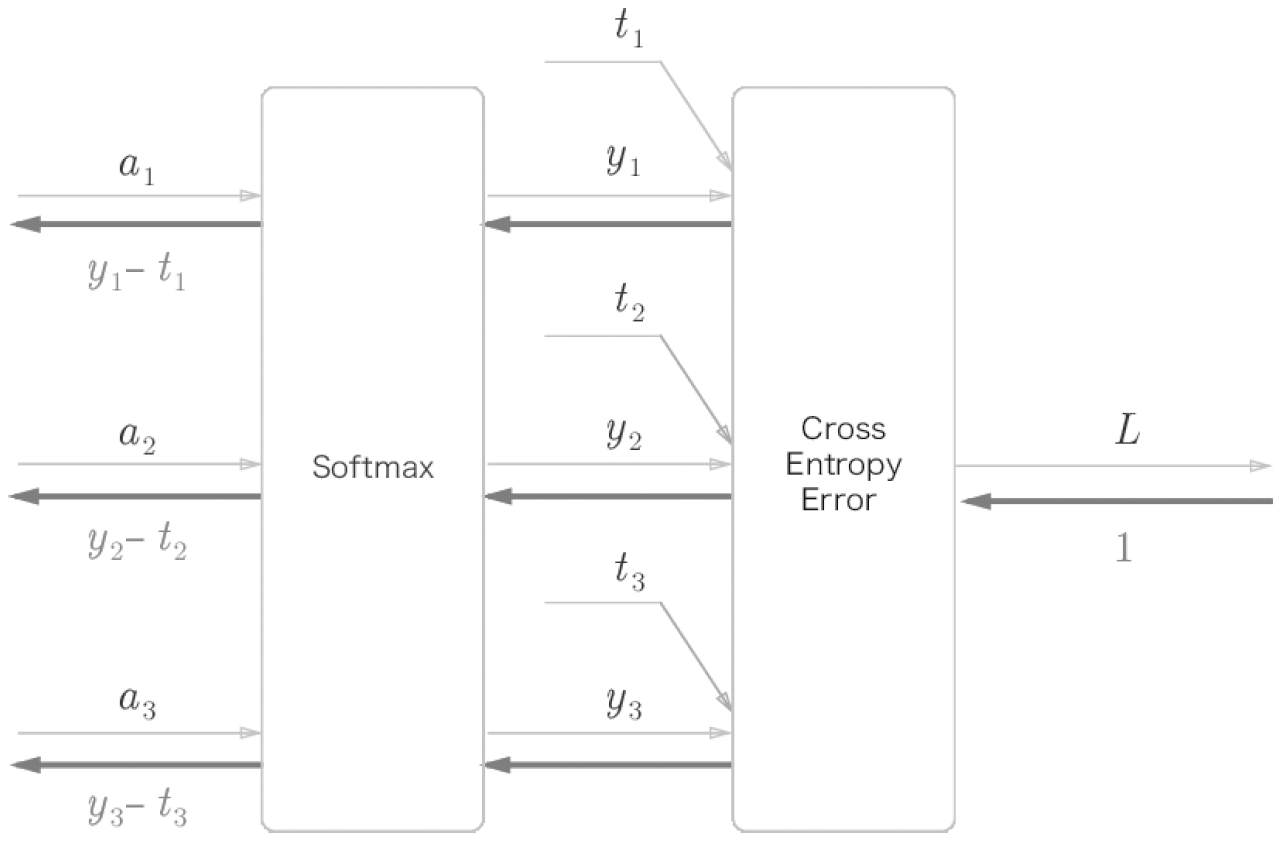
다음은 중간 과정을 생략하여 입력과 출력만 간단히 나타낸 그림입니다.
다음은 Softmax-With-Loss 계층을 구현한 코드입니다.
In [11]: class SoftmaxWithLoss:
....: def __init__(self):
....: self.loss = None
....: self.y = None # 소프트맥스 출력
....: self.t = None # 타깃 레이블
....:
....: def forward(self, x, t):
....: self.t = t
....: self.y = softmax(x)
....: self.loss = cross_entropy_error(self.y, self.t)
....: return self.loss
....:
....: def backward(self, dout=1):
....: batch_size = self.t.shape[0]
....: if self.t.size == self.y.size: # 원-핫-인코딩
....: dx = (self.y - self.t) / batch_size
....: else:
....: dx = self.y.copy()
....: dx[np.arange(batch_size), self.t] -= 1
....: dx = dx / batch_size
....:
....: return dx
....:
역전파(backward) 때 전파하는 값을 배치수(batch_size)로 나눠서 1개당 오차를 앞 계층으로 전파하는 것에 주목하세요.
Softmax-With-Loss 역전파 상세
순전파
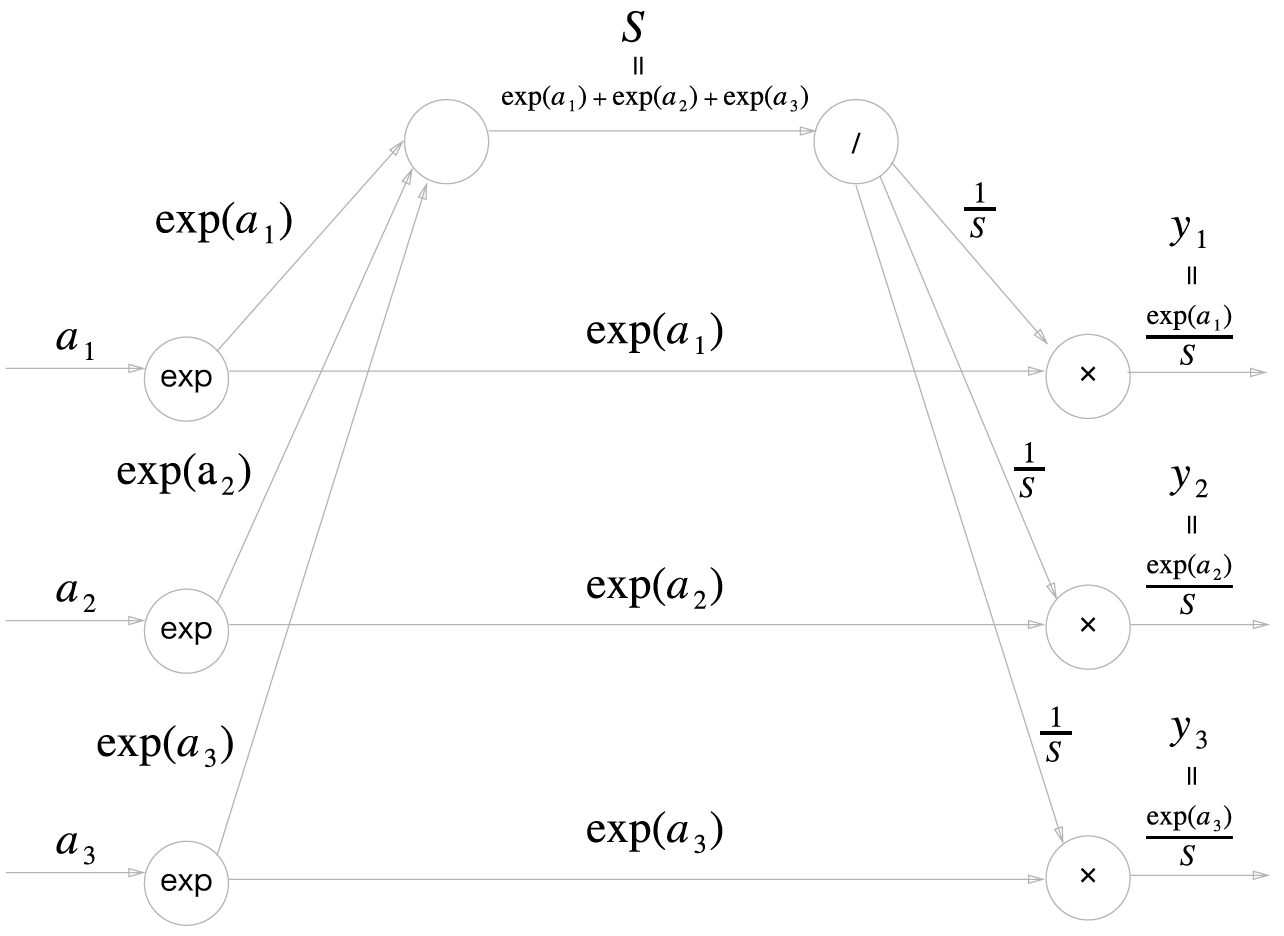
소프트맥스 함수는 다음과 같습니다.
다음은 소프트맥스 계층의 순전파 계산 그래프입니다. 출력값(\(y_1, y_2, y_3\))은 3개로 가정했습니다.
Cross Entropy Error 계층을 살펴봅니다. 교차 엔트로피 오차 수식은 다음과 같습니다.
Cross Entropy Error 계층의 계산 그래프는 다음과 같습니다.
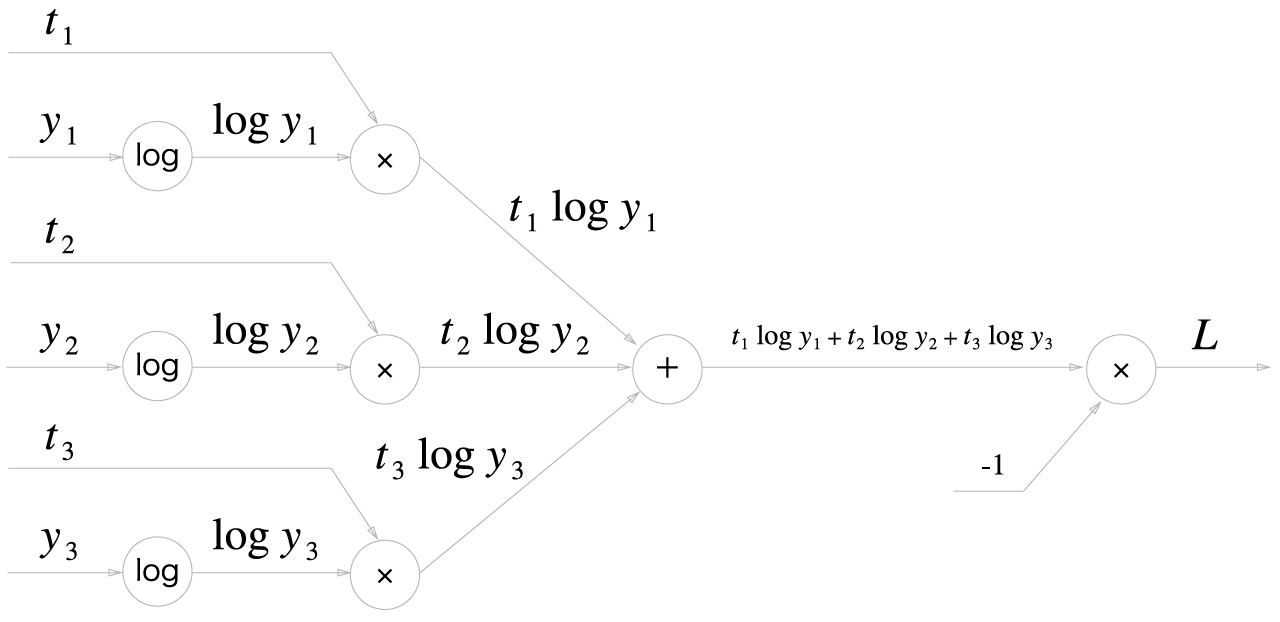
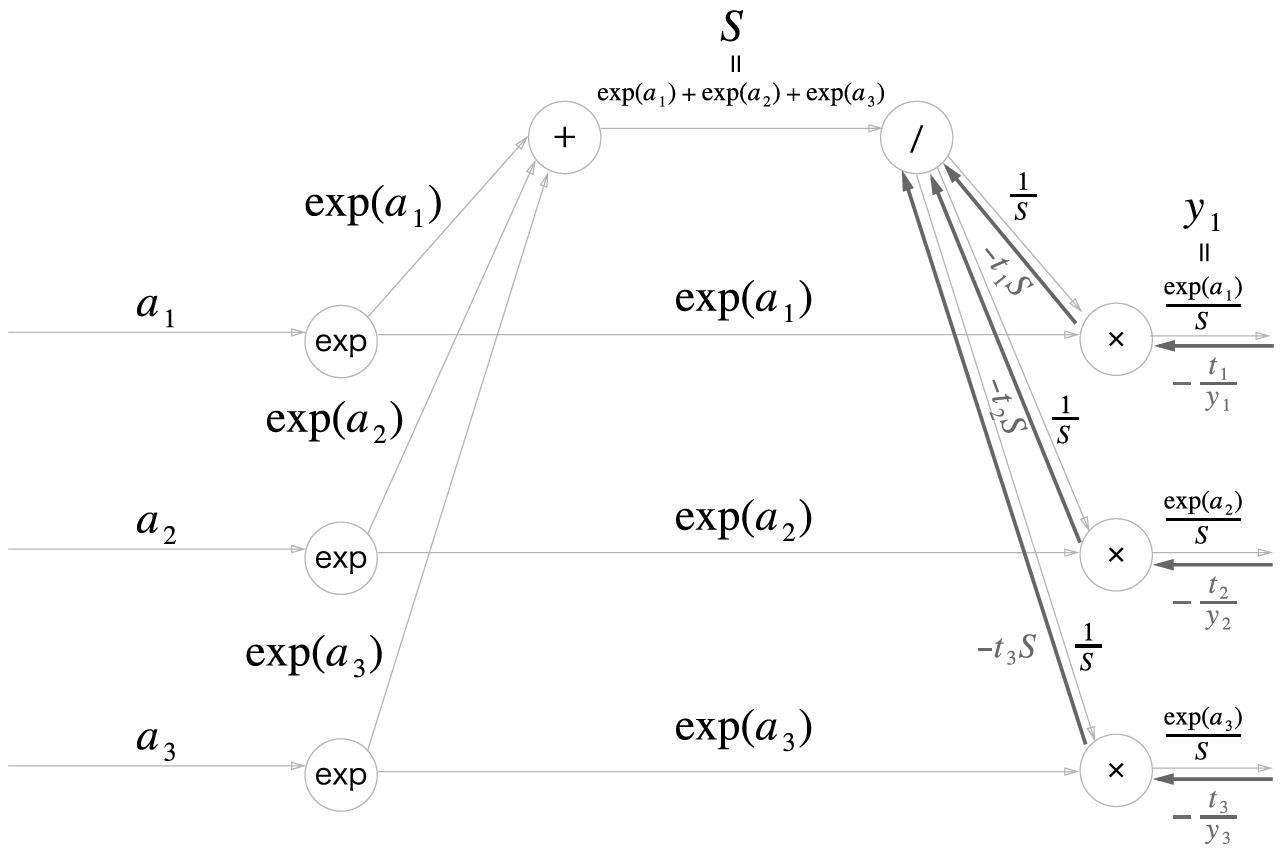
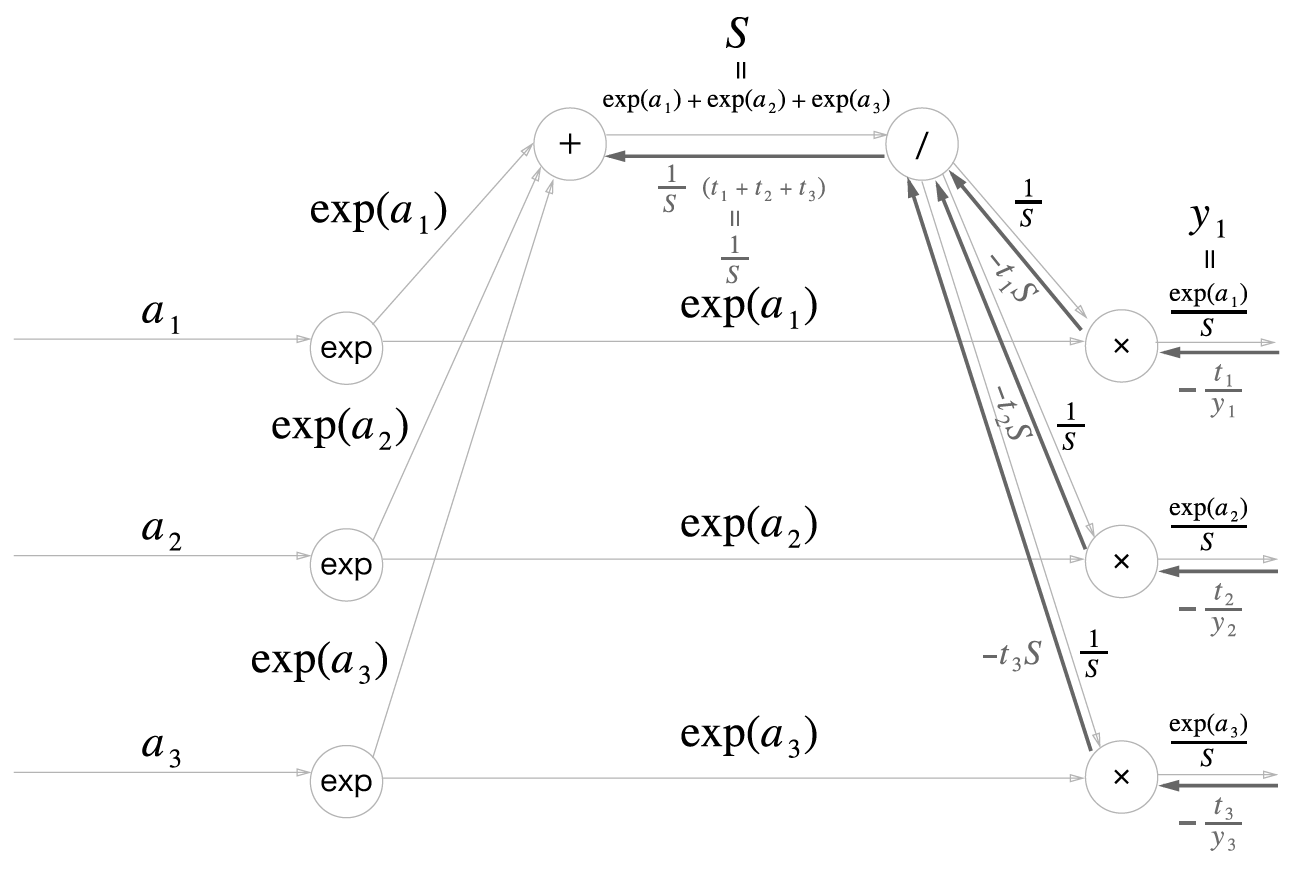
역전파
Cross Entropy Error 역전파
Cross Entropy Error 계층의 역전파입니다.
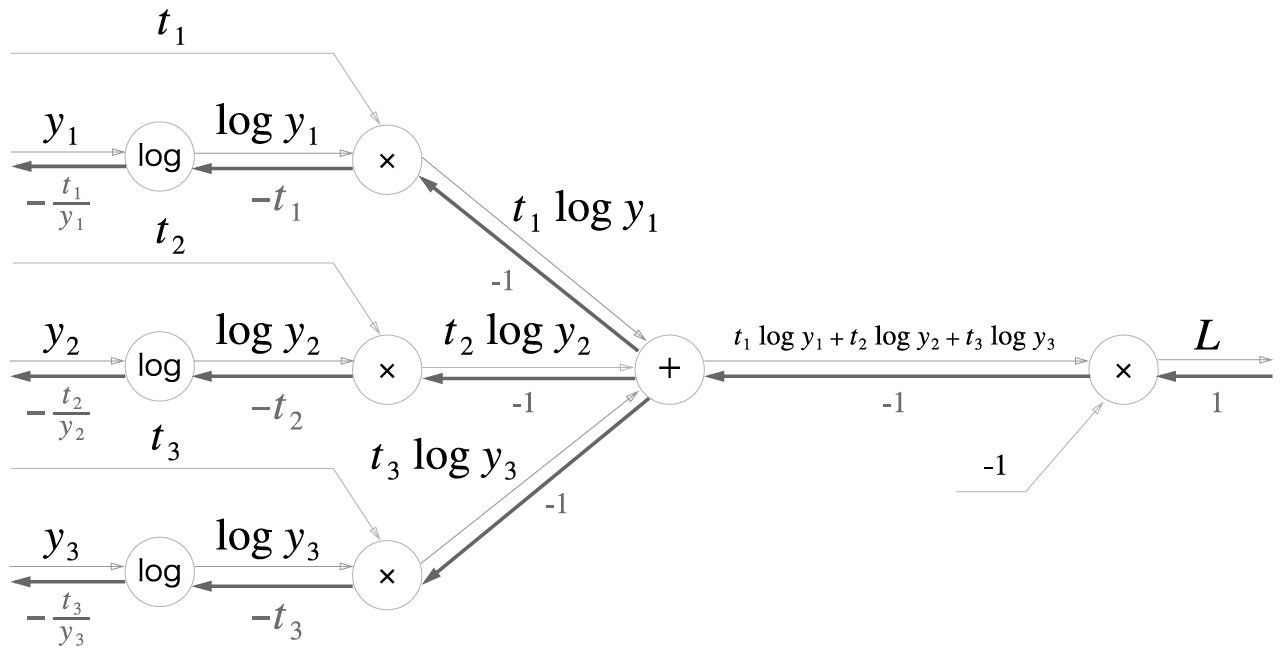
소프트맥스 역전파
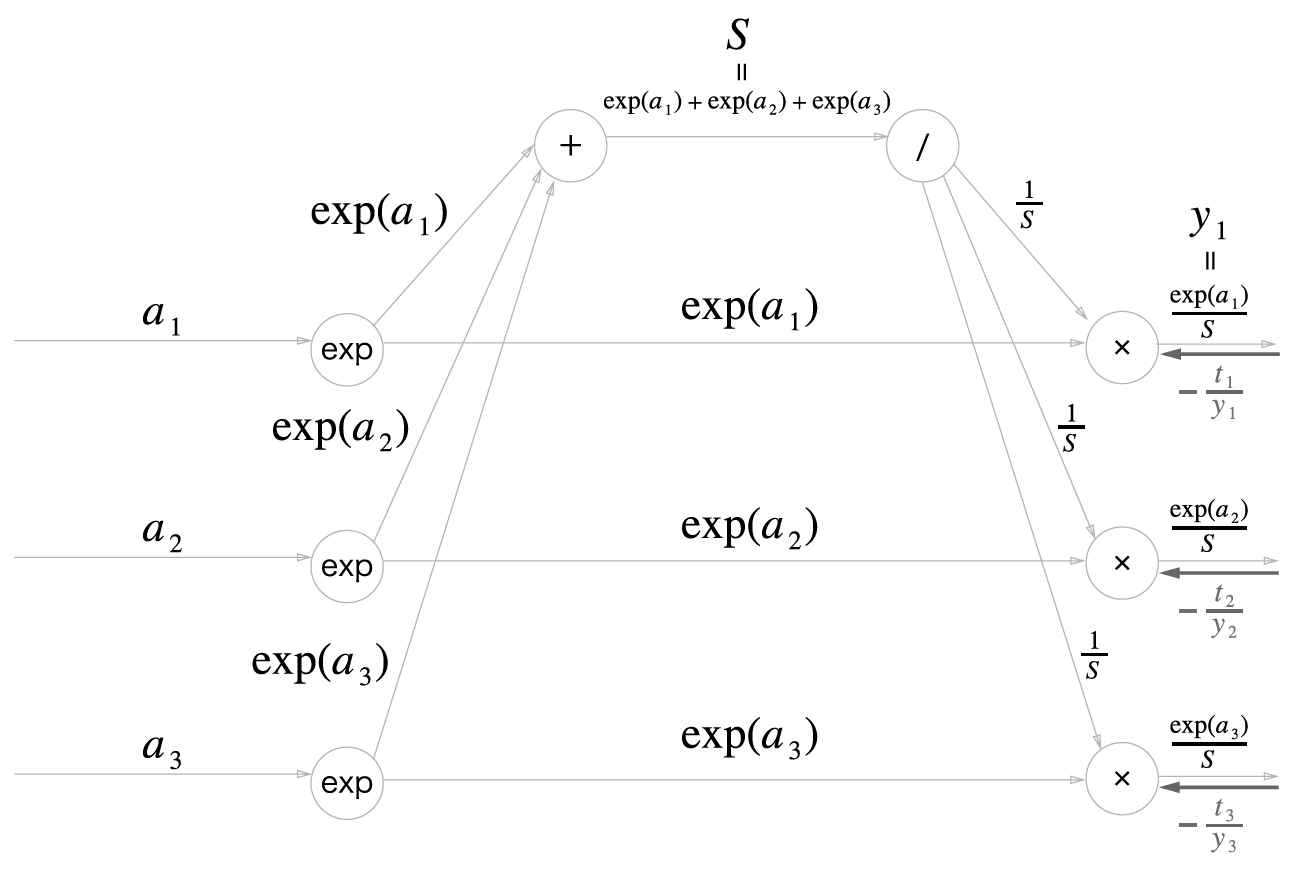
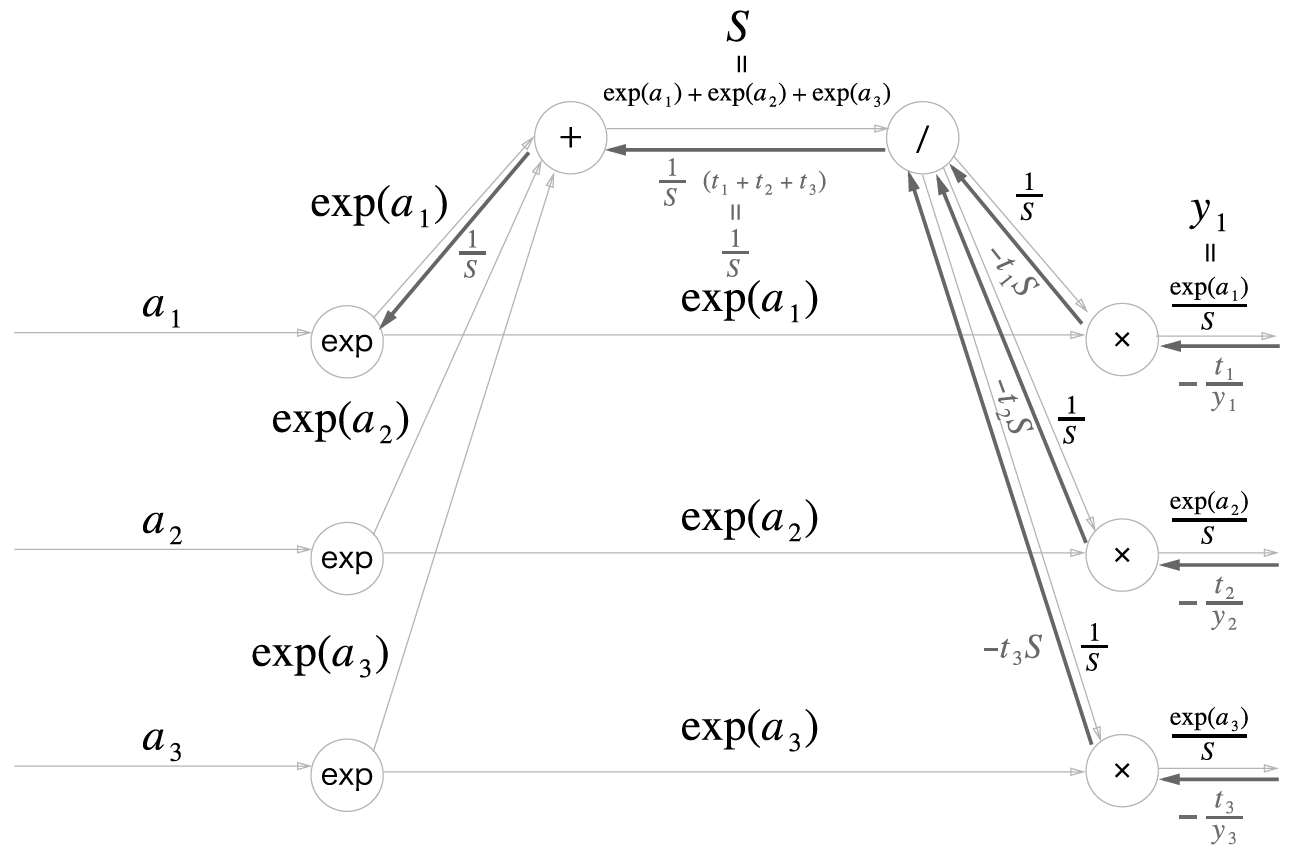
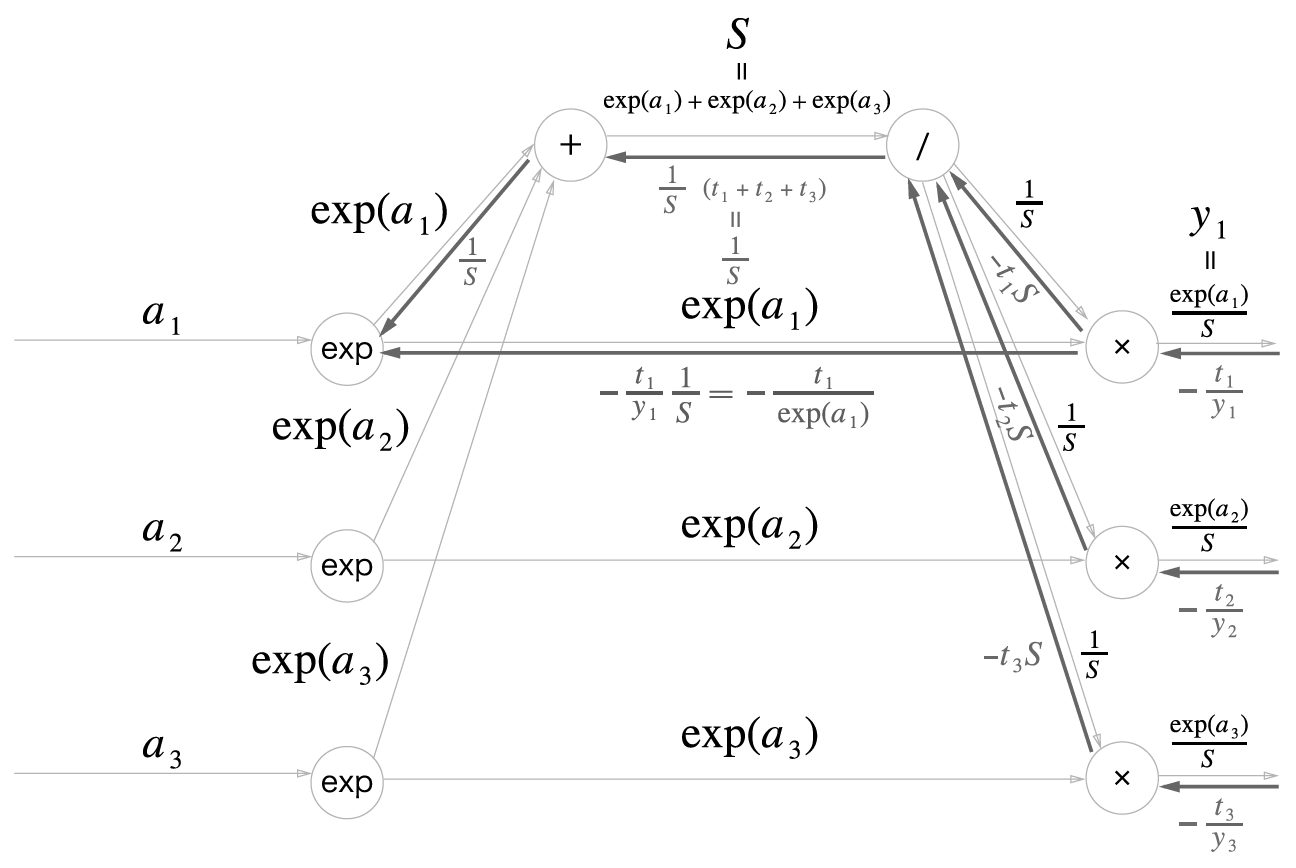
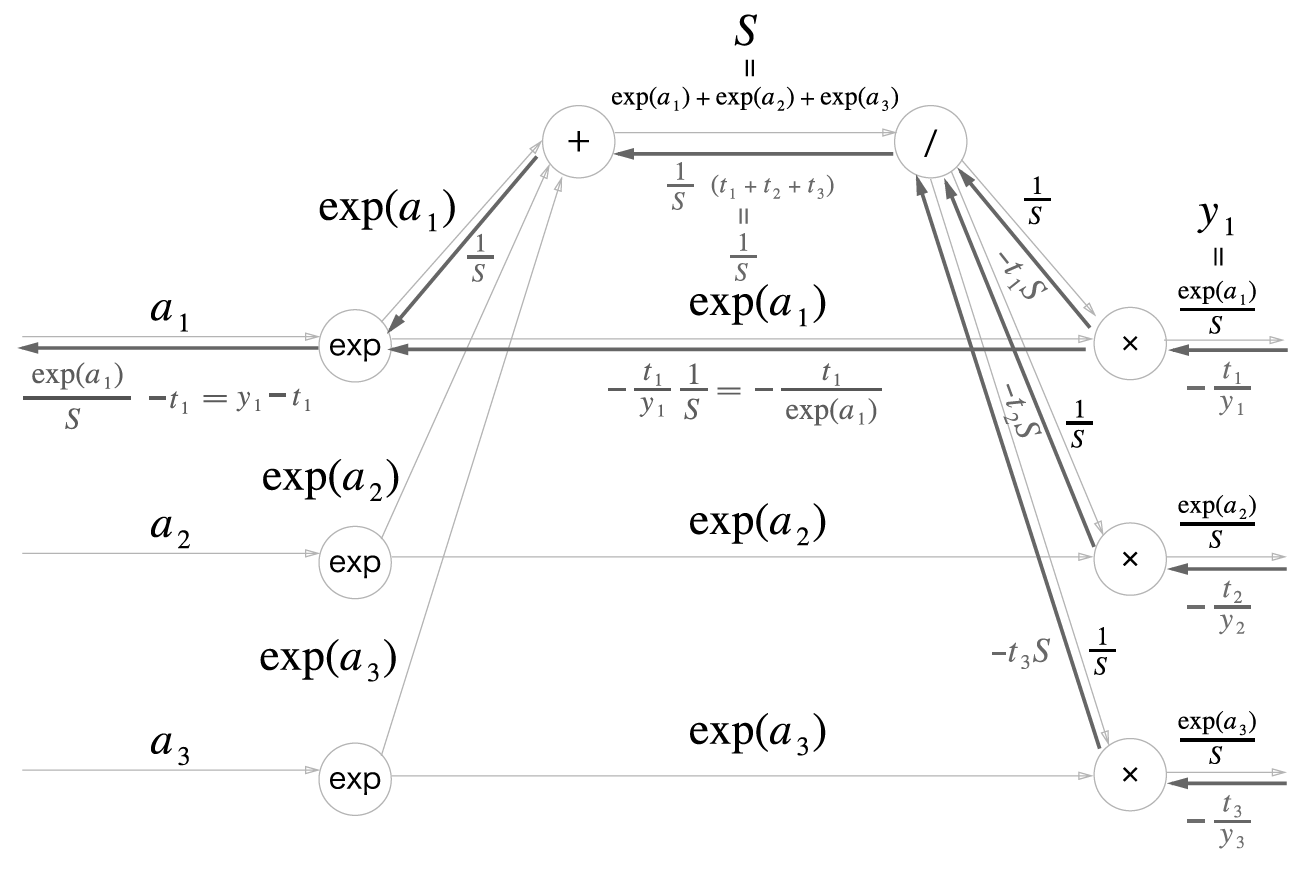
일 때,
이고
입니다.
여기서 \(t_1 + t_2 + \cdots + t_n = 1\) 입니다. 왜냐면 원핫인코딩이기때문에 하나만 제외하고는 모두 0이기 때문입니다.
오차역전파 구현
개요
- 1 단계 - 미니배치
훈련데이터 무작위 추출
- 2 단계 - 그래디언트
그래디언트 계산
- 3 단계 - 매개변수 갱신
가중치 매개변수 갱신
- 4 단계 - 반복
1 - 3 단계 반복
구현
ch05 디렉토리 two_layer_net.py 파일입니다.
1# coding: utf-8
2import sys, os
3sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
4import numpy as np
5from common.layers import *
6from common.gradient import numerical_gradient
7from collections import OrderedDict
8
9
10class TwoLayerNet:
11
12 def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
13 # 가중치 초기화
14 self.params = {}
15 self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
16 self.params['b1'] = np.zeros(hidden_size)
17 self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
18 self.params['b2'] = np.zeros(output_size)
19
20 # 계층 생성
21 self.layers = OrderedDict()
22 self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
23 self.layers['Relu1'] = Relu()
24 self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
25
26 self.lastLayer = SoftmaxWithLoss()
27
28 def predict(self, x):
29 for layer in self.layers.values():
30 x = layer.forward(x)
31
32 return x
33
34 # x : 입력 데이터, t : 정답 레이블
35 def loss(self, x, t):
36 y = self.predict(x)
37 return self.lastLayer.forward(y, t)
38
39 def accuracy(self, x, t):
40 y = self.predict(x)
41 y = np.argmax(y, axis=1)
42 if t.ndim != 1 : t = np.argmax(t, axis=1)
43
44 accuracy = np.sum(y == t) / float(x.shape[0])
45 return accuracy
46
47 # x : 입력 데이터, t : 정답 레이블
48 def numerical_gradient(self, x, t):
49 loss_W = lambda W: self.loss(x, t)
50
51 grads = {}
52 grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
53 grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
54 grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
55 grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
56
57 return grads
58
59 def gradient(self, x, t):
60 # forward
61 self.loss(x, t)
62
63 # backward
64 dout = 1
65 dout = self.lastLayer.backward(dout)
66
67 layers = list(self.layers.values())
68 layers.reverse()
69 for layer in layers:
70 dout = layer.backward(dout)
71
72 # 결과 저장
73 grads = {}
74 grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
75 grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
76
77 return grads
21-24줄:
Affine - Relu - Affine인스턴스 초기화 하여self.layersdict에 추가하고 있습니다.26줄: 소프트맥스와 로스는
lastLayer라는 인스턴스 변수에 따로 초기화하여 저장하는 것을 알 수 있습니다.28-32줄: 순전파하는 메소드로서
SoftmaxWithLoss계층은 실행되지 않는 것을 알 수 있습니다.35-37줄: 손실값을 계산할 때 순전파를 실행한 후 마지막 계층인
SoftmaxWithLoss를 실행하는 것을 알 수 있습니다.59-77줄: 역전파를 계산하는 부분으로 마지막 부분에 각 계층의 그래디언트 계산값을 dict형으로 반환하는 것을 알 수 있습니다.
64-70줄: 역전파는 마지막 계층
SoftmaxWithLoss부터 시작하여 거꾸로 계산하는 것을 알 수 있습니다.
그래디언트 검증
해석적으로 계산한 것과 역전파를 이용해서 계산한 그래디언트가 같다는 것을 검증합니다.
1# coding: utf-8
2import sys, os
3sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
4import numpy as np
5from dataset.mnist import load_mnist
6from two_layer_net import TwoLayerNet
7
8# 데이터 읽기
9(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
10
11network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
12
13x_batch = x_train[:3]
14t_batch = t_train[:3]
15
16grad_numerical = network.numerical_gradient(x_batch, t_batch)
17grad_backprop = network.gradient(x_batch, t_batch)
18
19# 각 가중치의 절대 오차의 평균을 구한다.
20for key in grad_numerical.keys():
21 diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) )
22 print(key + ":" + str(diff))
실행을 해보면 다음과 같이 두 값의 차가 0에 가까운 것을 알 수 있습니다.
W1:5.273619946964029e-10
b1:3.06042875476871e-09
W2:6.0484312693280634e-09
b2:1.3981116059186282e-07
오차역전파 사용
1# coding: utf-8
2import sys, os
3sys.path.append(os.pardir)
4
5import numpy as np
6from dataset.mnist import load_mnist
7from two_layer_net import TwoLayerNet
8
9# 데이터 읽기
10(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
11
12network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
13
14iters_num = 10000
15train_size = x_train.shape[0]
16batch_size = 100
17learning_rate = 0.1
18
19train_loss_list = []
20train_acc_list = []
21test_acc_list = []
22
23iter_per_epoch = max(train_size / batch_size, 1)
24
25for i in range(iters_num):
26 batch_mask = np.random.choice(train_size, batch_size)
27 x_batch = x_train[batch_mask]
28 t_batch = t_train[batch_mask]
29
30 # 기울기 계산
31 #grad = network.numerical_gradient(x_batch, t_batch) # 수치 미분 방식
32 grad = network.gradient(x_batch, t_batch) # 오차역전파법 방식(훨씬 빠르다)
33
34 # 갱신
35 for key in ('W1', 'b1', 'W2', 'b2'):
36 network.params[key] -= learning_rate * grad[key]
37
38 loss = network.loss(x_batch, t_batch)
39 train_loss_list.append(loss)
40
41 if i % iter_per_epoch == 0:
42 train_acc = network.accuracy(x_train, t_train)
43 test_acc = network.accuracy(x_test, t_test)
44 train_acc_list.append(train_acc)
45 test_acc_list.append(test_acc)
46 print(train_acc, test_acc)
위 코드를 실행하면 다음과 같이 각각의 에폭에서 훈련데이터와 시험데이터의 정확도를 출력하는 것을 볼 수 있습니다.
0.08231666666666666 0.0827
0.9046333333333333 0.9066
0.9221166666666667 0.9242
0.93535 0.9343
0.94295 0.9403
0.9507833333333333 0.947
0.95605 0.9532
0.9595333333333333 0.9557
0.9609333333333333 0.9579
0.9657666666666667 0.9603
0.9670166666666666 0.9615
0.9693166666666667 0.9624
0.9713 0.9647
0.9727666666666667 0.9651
0.9738 0.9665
0.9750666666666666 0.9678
0.9769666666666666 0.9677