수집형¶
리스트(list)¶
리스트는 순서가 매겨진 객체들을 일렬로 나열한 자료형입니다.
리스트 만들기¶
리스트 객체는 대괄호 []를 이용하여 만들 수 있습니다. 대괄호 안에
객체들을 쉼표(,)로 구분해서 나열하여 리스트 객체를 만들 수 있습니다.
쉼표 사이에 입력한 객체들을 리스트의 성분(element) 또는 원소 또는
요소라고 부른다.
다음은 여러 가지 리스트 형을 예로 든 것입니다. 숫자형 성분으로 이루어진 리스트입니다.
리스트1 = [1, 2, 3]
문자열 성분으로 이루어진 리스트입니다.
리스트2 = ['가', '나', '다']
문자열과 숫자형 성분으로 이루어질 수 있습니다.
리스트3 = ['가', 1, '나', 2]
리스트를 성분으로 갖는 리스트를 만들 수 있습니다.
리스트4 = [1, 2, '가나다', ['가', '나', '다']]
리스트를 만드는 다른 방법으로는
list()
메소드를 사용하는 것입니다. 인자로 사용되는 <반복 객체>는 열거형인
리스트, 튜플, range() 같은 객체들이 올 수 있습니다.
인자로 다른 리스트를 사용할 수 있습니다.
list([1, 2, 3])
[1, 2, 3]
list의 인자로 튜플을 사용할 수 있습니다.
list(('가', '나', '다'))
['가', '나', '다']
인자로 반복 가능 객체인 range() 함수를 사용할 수 있습니다.
list(range(5))
[0, 1, 2, 3, 4]
문자열도 반복가능 객체이므로 인자로 사용될 수 있습니다.
list("가나다라마바사")
['가', '나', '다', '라', '마', '바', '사']
빈 리스트를 만들려면 [] 또는 list()를 이용하면 됩니다.
직접하기
“한글은아름다워!”라는 문자들을 성분으로 갖는 리스트를
list()를 이용해서 만드시오.
리스트 성분 접근¶
리스트는 열거형이기때문에 인덱스를 이용해서 원하는 위치의 성분을 접근할 수 있습니다. 인덱스(index)란 객체의 위치를 정수로 표시하는 것을 말합니다. 파이썬 인덱스는 0부터 시작합니다. 즉 첫번째 성분의 인덱스는 0, 두번째 성분은 1, …과 같이 사용합니다.
리스트 = list("가나다라마바사")
리스트
['가', '나', '다', '라', '마', '바', '사']
첫번째 성분에 접근하기 위해서는 인덱스 0을 사용해야 합니다.
리스트[0] # 첫번째 성분
'가'
슬라이싱¶
여러 개의 성분들을 슬라이싱(slicing)을 이용해 접근할 수 있습니다. 슬라이싱이란 콜론을 이용하여 규칙을 만족하는 인덱스들에 대한 성분들을 한꺼번에 선택하는 것을 말합니다. 사용법은 다음과 같다.
[시작:끝:간격]
시작부터 끝 - 1까지 간격 만큼 증가합니다. 주의해야 할 것은
끝 인덱스는 포함되지 않는다는 것입니다. 간격 부분이 없으면 1씩
증가합니다. 간격이 음수가 나오면 시작부터 끝까지 간격
만큼씩 감소합니다.
리스트 = list("가나다라마바사")
리스트
['가', '나', '다', '라', '마', '바', '사']
인덱스 1부터 4까지 성분을 선택하려면 다음과 같이 합니다.
리스트[1:5]
['나', '다', '라', '마']
리스트[0:5:2]
['가', '다', '마']
슬라이싱 인덱스로 음수를 사용할 수 있습니다. -1은 맨 끝 인덱스를
나타내고 -2는 끝에서 두번째 인덱스를 의미합니다.
리스트[-1]
'사'
간격이 음수가 나오고 시작, 끝 인덱스가 비어 있으면 시작은 맨 끝
인덱스를 의미하고 끝은 맨 처음 인덱스를 의미합니다. 따라서 다음과 같이
하면 순서가 뒤집혀서 나오게 됩니다.
리스트[::-1]
['사', '바', '마', '라', '다', '나', '가']
리스트 추가¶
리스트는 가변(mutable)형이기 때문에 성분들의 값들을 변경할 수 있고 삭제,
추가 및 삽입할 수 있습니다. append() 메소드를 이용하여 기존 리스트에
객체를 추가할 수 있습니다.
리스트1 = ['가']
리스트1.append('나')
리스트1
['가', '나']
직접하기
빈 리스트
꽃을 만들고 차례로 “개나리”, “장미”, “매화”, “국화”를 추가하시오.
리스트 합치기¶
덧셈 연산자 +를 이용해서 두 리스트들을 합쳐 새로운 리스트를 만들
수 있습니다.
[1, 2, 3] + ['ㅁ', 'ㅂ', 'ㅅ']
[1, 2, 3, 'ㅁ', 'ㅂ', 'ㅅ']
extend 메소드를 이용해서 기존의 리스트에 다른 리스트 성분들을 합칠
수 있습니다. 새로운 리스트 객체를 만드는 것이 아니라 기존의 리스트에
추가하는 것입니다.
리1 = [1, 2, 3]
리2 = [4, 5, 6]
리1.extend(리2)
리1
[1, 2, 3, 4, 5, 6]
append 메소드와는 약간 다르다. append는 리스트 객체를 통째로
추가하는 것이고 extend는 기존의 리스트에 성분들을 하나씩 추가하는
것입니다.
리1 = [1, 2, 3]
리2 = [4, 5, 6]
리1.append(리2)
리1
[1, 2, 3, [4, 5, 6]]
+을 이용해서 두 리스트를 합치면 반환되는 리스트는 새로운 객체라는
것을 명심하자. 새로운 객체를 만들 때 컴퓨터 자원을 소모하게 되므로
다음과 같은 프로그램은 바람직하지 않다.
리 = [[1, 2], [3, 4], [5, 6]]
합 = []
for 항 in 리:
합 = 합 + 항
print(합)
[1, 2, 3, 4, 5, 6]
위의 것은 다음과 같이 extend 메소드를 사용하는 것이 효율적입니다.
리 = [[1, 2], [3, 4], [5, 6]]
합 = []
for 항 in 리:
합.extend(항)
print(합)
[1, 2, 3, 4, 5, 6]
리스트 삭제¶
del() 내장 함수를 이용하여 원하는 성분 및 객체를 삭제할 수 있습니다.
리스트2 = list("가나다라마바사")
리스트2
['가', '나', '다', '라', '마', '바', '사']
del(리스트2[0])을 이용해서 첫번째 성분을 삭제했다.
del(리스트2[0])
리스트2
['나', '다', '라', '마', '바', '사']
리스트의 pop(인덱스) 메소드를 이용해 인덱스에 대응되는 성분을
삭제할 수 있습니다.pop() 메소드의 반환값으로 삭제되는 객체가 반환됩니다.
리스트 = list("가나다라마바사")
리스트
['가', '나', '다', '라', '마', '바', '사']
다음은 리스트의 첫번째 성분인 가를 제거합니다.
리스트.pop(0)
리스트
['나', '다', '라', '마', '바', '사']
pop 메소드는 인자가 없을 경우 마지막 성분을 제거합니다.
리스트.pop() # 마지막 성분 삭제
리스트
['나', '다', '라', '마', '바']
remove(성분) 메소드를 이용해서도 성분을 삭제할 수 있습니다. pop
메소드는 인덱스를 인자로 취하는 반면, remove 메소드는 성분 객체를
인자로 받는다.
리스트 = list("가나가라마바가")
리스트
['가', '나', '가', '라', '마', '바', '가']
리스트 성분 중 같은 것이 여러개 있으면 첫번째로 나오는 성분을 제거합니다.
리스트.remove("가") # 첫번째 성분 삭제
리스트
['나', '가', '라', '마', '바', '가']
리스트 삽입¶
리스트 insert(인덱스, 객체) 메소드를 이용하여 원하는 인덱스
위치에 객체를 삽입할 수 있습니다.
리스트 = list("가다라")
리스트
['가', '다', '라']
다음은 인덱스 1인 위치에 문자열 객체 "나"를 삽입하고 기존에
있는 성분들을 하나씩 뒤로 이동시킨다.
리스트.insert(1, "나")
리스트
['가', '나', '다', '라']
직접하기
(1, "하나"),(3, "셋"),(4, "넷")을 성분으로 하는 리스트숫자를 만들고 2번째 성분에(2, "둘")을 삽입하시오.
정렬(sort)¶
리스트 sort(key=함수) 메소드를 이용하여 리스트 성분들을 정렬할 수
있습니다. 핵심어 인자 key에는 부등호 <를 이용해서 비교가능한
객체를 반환하는 함수를 지정합니다. 이 함수의 인자는 리스트의 성분을
받는다. 인자가 없을 때(key=None)는 비교 연산자 <를 이용해서
리스트의 성분들을 비교하여 정렬합니다.
리스트 = [3, 2, 4, 1, 5]
리스트
[3, 2, 4, 1, 5]
성분들이 정수형이기 때문에 부등호 <를 이용해서 비교가능하다.
리스트.sort()
리스트
[1, 2, 3, 4, 5]
하지만 다음과 같이 숫자형과 문자열을 섞어 놓으면 비교 연산자 <를
사용해서 비교가 불가능하기 때문에 오류가 발생합니다.
리스트 = ['a', 1, 2, 3, 'b']
리스트.sort()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-45-0ec5d1559878> in <module>()
1 리스트 = ['a', 1, 2, 3, 'b']
----> 2 리스트.sort()
TypeError: '<' not supported between instances of 'int' and 'str'
사용자 정의 함수를 사용해서 정렬을 할 수 있습니다. 다음은 str 함수를
이용해서 객체의 문자열을 반환하는 함수입니다.
def 순서함수(항목):
return str(항목)
리스트 = ['a', 1, 2, 3, 'b']
리스트.sort(key=순서함수)
print(리스트)
[1, 2, 3, 'a', 'b']
순서함수의 인자로 리스트의 각 성분들이 건네 주면 반환값으로 그 성분의 문자열 형으로 반환을 합니다.sort()함수는 이 반환된 문자열을 비교 연산자<를 이용해서 비교를 해서 정렬을 합니다. 여기서는 반환값이 문자열이기 때문에 사전식으로 정렬을 하게 됩니다.
리스트 축약(list comprehension)¶
리스트 축약은 이미 존재하는 열거형(리스트, 튜플 등)을 기반으로 새로운 리스트를 생성하는 간단한 방법을 제공합니다. 기존의 열거형의 성분들에 원하는 연산을 해서 새로운 성분을 만들 때 사용할 수 있습니다. 또한 조건에 맞는 성분들에 대해서만 결과를 만들어 낼 수도 있습니다.
예를 들어 숫자로 이루어진 리스트가 하나 있을 때 이 리스트의 모든 항목에 대해 제곱해준 리스트를 생성하고 싶다고 하자.
리스트 = [1, 2, 3, 4]
[항목 ** 2 for 항목 in 리스트]
[1, 4, 9, 16]
리스트 축약 사용법은 대괄호 안에 수식, for절이 오고 다음으로
0개 이상의 for 또는 if 절이 나올 수 있습니다.
[수식 for절 (for 또는 if절)]
for절이 수행될 때마다 수식이 평가되어 새로운 리스트의 성분에
추가됩니다. 위의 제곱의 예를 일반적인 for문으로 변경하면 다음과
같다.
리스트 = [1, 2, 3, 4]
새리스트 = []
for 항목 in 리스트:
새리스트.append(항목 ** 2)
print(새리스트)
[1, 4, 9, 16]
이 밖에도 열거형 공통으로 할 수 있는 +, *, 슬라이싱 연산들을 할
수 있습니다. 열거형을 참조하자.
연습문제 1¶
리스트 = ['ㄱ', 'ㄴ', 'ㄱ', 'ㄷ', 'ㄱ', 'ㄹ']가 주어질 때리스트성분'ㄱ'을 뒤쪽에서부터 차례로 제거하는 프로그램을 작성하시오. 즉,리스트 = ['ㄱ', 'ㄴ', 'ㄱ', 'ㄷ', 'ㄹ'],리스트 = ['ㄱ', 'ㄴ', 'ㄷ', 'ㄹ'],리스트 = ['ㄴ', 'ㄷ', 'ㄹ']순으로 만드시오.10가지 색깔을 담는 리스트를 만들고 마우스를 클릭하여 별을 그릴 때 별의 색깔을 리스트 중에서 무작위로 골라 칠하게 프로그램을 만드시오.
소행성 게임에서 소행성을 10개 만들어 리스트에 저장하고 “꽝”과 동시에 소행성을 리스트에서 제거하는 프로그램을 만드시오.
튜플(tuple)¶
튜플도 리스트와 마찬가지로 객체를 담는데 사용하는 데이터형입니다. 리스트
형과 다른 점은 리스트는 가변 객체이고 튜플은 불변(immutable) 객체라는
것입니다. 불변이란 객체가 일단 만들어지면 안의 성분들을 바꿀 수가 없습니다는
것입니다. 튜플도 열거형이기 때문에 열거형의 공통 연산자
+, *, 슬라이싱을 사용할 수 있습니다.
튜플 만들기¶
튜플은 소괄호 ()와 쉼표를 이용하여 성분들을 나열하여 만들 수 있습니다.
또는
tuple(반복가능객체)를
이용해서도 튜플을 만들어 낼 수도 있습니다.
튜플 = (1, 2, 3) # 소괄호를 이용해서 튜플 생성
print(tuple(range(5))) # 반복가능 객체 range() 이용 튜플 생성
(0, 1, 2, 3, 4)
튜플은 소괄호 없이 쉼표만으로도 만들 수 있습니다.
튜 = 1, 2, 3
튜
(1, 2, 3)
튜플은 중첩될 수 있습니다. 즉, 튜플이 튜플의 원소가 될 수 있습니다.
튜 = 1, 2, 3
플 = ("가", "나", "다")
튜플 = 튜, 플
튜플
((1, 2, 3), ('가', '나', '다'))
성분 한 개로 이루어진 튜플을 만들 때는 괄호를 닫기 전에 반드시 쉼표를 붙여야 합니다. 붙이지 않으면 순서를 나타내는 괄호로 인식해서 객체 자체로 인식합니다.
정수 = (1) # 정수
print(type(정수))
튜 = (1,) # 튜플: 괄호 닫기 전에 쉼표 필요
print(type(튜))
<class 'int'>
<class 'tuple'>
성분 접근¶
리스트와 마찬가지로 튜플의 특정 성분을 접근하기 위해서는 대괄호와 인덱스를 사용합니다.
양이 = ('러시안 블루', '페르시안', '브리티시 쇼트 헤어', '먼치킨', '스코티시 폴드', '페르시안')
양이
('러시안 블루', '페르시안', '브리티시 쇼트 헤어', '먼치킨', '스코티시 폴드', '페르시안')
양이[2]
'브리티시 쇼트 헤어'
부분적으로 선택하기 위해서 슬라이싱을 사용할 수 있습니다.
양이[2:5]
('브리티시 쇼트 헤어', '먼치킨', '스코티시 폴드')
index는 성분의 인덱스를 반환합니다.
양이.index('먼치킨')
3
count를 이용해 성분의 갯수를 센다.
양이.count('페르시안')
2
직접하기
양의 정수 5개로 이루어진 튜플
a와 또 다른 양의 정수 5개로 이루어진 튜플b를 만드시오.a와b의 성분들로 이루어진 튜플c를 만드시오.c를 정렬한 튜플d를 만드시오.d의 3번째 성분을 출력하시오.d의 마지막 3개 성분들을 출력하시오.d의 원소의 갯수를 출력하시오.
튜플 불변성¶
튜플은 불변하기 때문에 성분을 바꿀 수 없습니다.
튜플 = (1, 2, 3)
print('첫번째 성분:', 튜플[0])
튜플[0] = 100
첫번째 성분: 1
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-59-a714a5464dcb> in <module>()
1 튜플 = (1, 2, 3)
2 print('첫번째 성분:', 튜플[0])
----> 3 튜플[0] = 100
TypeError: 'tuple' object does not support item assignment
하지만 가변 객체를 성분으로 가질 수 있습니다.
리스트 = ['가', '나']
튜플 = ([1, 2, 3], 리스트)
튜플
([1, 2, 3], ['가', '나'])
튜플의 성분 중 가변 객체의 성분은 바꿀 수 있습니다.
튜플[1][0] = '다'
튜플
([1, 2, 3], ['다', '나'])
튜플[1]은 리스트이므로 각각의 성분을 위에서와 같이
튜플[1][0] = '다'로 바꿔도 괜찮다. 하지만 튜플의 성분을 다음과
같이 다른 객체로 바꾸려고 하면 오류가 발생합니다.
튜플[1] = "불변"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-62-6f6436659694> in <module>()
----> 1 튜플[1] = "불변"
TypeError: 'tuple' object does not support item assignment
할당¶
튜플 할당문 =을 사용할 때 “튜플을 싸기(packing)” 또는 “튜플을
풀기(unpacking)” 두 가지로 생각할 수 있습니다. 우선 튜플을 싼다는 것은
튜플 객체를 하나의 변수에 넣는 것을 의미합니다.
학생 = ("윤지수", 11, "초등")
튜플을 푼다는 것은 이미 만들어진 튜플의 성분들을 각각의 변수에 할당하는 것을 의미합니다.
학생 = ("윤지수", 11, "초등")
(이름, 나이, 학력) = 학생
print("이름:", 이름, ", 나이:", 나이, ", 학력:", 학력, sep="")
이름:윤지수, 나이:11, 학력:초등
1번째 줄에서
학생튜플 객체를 만듭니다.2번째 줄에서 이미 만들어진
학생 = ("윤지수", 11, "초등")튜플의 각 성분"윤지수",11,"초등"을이름,나이,학력변수에 할당합니다.
두 객체의 값을 바꾸고 싶을 때 튜플 풀기를 이용하면 간단히 해결할 수 있습니다.
나 = "아름다움"
너 = "기쁨"
print("나에게는 ", 나, ", 너에게는 ", 너, "이 있습니다.", sep="")
너, 나 = 나, 너
print("나에게는 ", 나, ", 너에게는 ", 너, "이 있습니다.", sep="")
나에게는 아름다움, 너에게는 기쁨이 있습니다.
나에게는 기쁨, 너에게는 아름다움이 있습니다.
return 튜플¶
함수의 반환값은 오직 하나밖에 안됩니다. 그러나 여러 객체를 반환해야할 필요가 생긴다. 이럴 때 여러 객체를 하나의 튜플로 묶어서 반환하면 함수값을 받을 때 튜플을 풀어서 각각의 변수에 할당해서 사용할 수 있습니다.
def 합평(점수들):
합 = 0
for 항목 in 점수들:
합 += 항목
평 = 합 / len(점수들)
return 합, 평
합, 평 = 합평([90, 80, 95])
print("합계: {}, 평균: {:.1f}".format(합, 평))
합계: 265, 평균: 88.3
6번째 줄에서
return 합, 평과 같이 튜플로 함수값을 반환합니다.8번째 줄
합, 평 = 합평([90, 80, 95])에서 함수값을합, 평으로 튜플을 풀어서 받는다.
연습문제 2¶
함수
합평표(점수들)를 만들어 점수를 리스트로 입력하면 합계, 평균, 표준편차를 반환하도록 프로그램을 작성하고 실행하시오.
사전(dict)¶
국어 사전이 단어와 단어의 뜻을 나타내는 형식으로 이루어지듯이 파이썬 사전도 열쇠(key)와 값(value)의 쌍으로 이루어집니다. 사전은 유일한 키에 대응되는 값들을 저장하고 키에 대응되는 값들을 불러올 필요가 있을 때 사용됩니다. 사전을 사용하는 장점 중 하나는 빠르게 열쇠를 검색할 수 있습니다는 것입니다. 사전 열쇠의 순서는 해싱(hashing)에 의해서 결정되기 때문에 우리가 생각하는 것과 다르게 나올 수 있습니다.
사전을 만드는 방법은 중괄호 {} 안에 키와 값을 콜론을 사용하여 쌍을
만들고 쉼표로 항목들을 구분합니다.
사전 = {1:'가', 2:'나'}
콜론 앞에 있는 객체들 1, 2가 사전의 열쇠이고 콜론 뒤에 있는
객체들 가, 나가 값입니다. 또한 dict(키워드 인자) 메소드를
이용해서도 사전 객체를 만들 수 있습니다. 여기서 키워드는 식별자 조건을
만족해야 합니다. 즉, 숫자가 나올 수 없습니다.
사전 = dict(a = 'a', b = 'b')
print(사전)
{'a': 'a', 'b': 'b'}
다음은 숫자 1, 2를 키워드로 사용하고 있기 때문에 오류가
발생합니다. 숫자는 식별자로 사용할 수 없기 때문입니다.
dict(1='a', 2='b')
File "<ipython-input-112-5bd88143cd18>", line 1
dict(1='a', 2='b')
^
SyntaxError: keyword can't be an expression
열쇠로 사용될 수 있는 객체는 불변 객체만 가능하다. 즉, 문자열, 숫자형,
튜플 등은 열쇠로 사용될 수 있으나 가변 객체인 리스트는 사용될 수 없습니다.
사전의 열쇠로 리스트 [1, 2]를 사용했기 때문에 오류가 발생했다.
{[1, 2]: '불가능'}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-113-df43ebadf3c1> in <module>()
----> 1 {[1, 2]: '불가능'}
TypeError: unhashable type: 'list'
빈 사전은 {}을 사용하여 만들거나 dict() 메소드를 이용할 수
있습니다. 다음과 같이 {}를 이용하여 단어장이란 이름의 빈 사전을
만듭니다.
단어장 = {} # 빈 사전 만들기
사전은 열쇠를 통해서 값을 불러오거나 변경할 수 있습니다. 사전의 열쇠에 해당하는 값에 접근할 때는 리스트에서와 같이 대괄호를 이용합니다. 하지만 리스트와는 달리 인덱스를 사용하지 않고 열쇠를 사용합니다는 점이 다르다.
다음과 같이 단어장 사전에 열쇠 가와 값 '가나다' 쌍을
다음과 같이 추가합니다.
단어장['가'] = '가나다'
단어장
{'가': '가나다'}
사전에 동일한 열쇠가 이미 존재합니다면 기존의 값을 대체합니다.
단어장['가'] = '가을'
단어장
{'가': '가을'}
사전의 열쇠를 이용해서 값을 불러온다.
ㄱ = 단어장['가'] # 키 '가'에 해당하는 값 반환
ㄱ
'가을'
사전의 성분을 제거하고 싶으면 del() 함수를 사용하면 됩니다.
전화부 = {'과장': 1234, '부장': 2345}
전화부
{'과장': 1234, '부장': 2345}
del(전화부['과장'])
전화부
{'부장': 2345}
keys(),
values()
메소드를 이용해서 사전의 키와 값들에 대한 리스트를 얻을 수 있습니다. 두
메소드의 반환값은
view
객체이며 반복가능 객체입니다. 반복가능 객체이므로 for문에서 사용할
수 있습니다.
과일가격 = {"사과": 1000, "배": 1500}
과일가격.keys() # view 객체 반환
dict_keys(['사과', '배'])
list 함수를 이용해서 리스트로 변환할 수 있습니다.
list(과일가격.keys())
['사과', '배']
for 과일 in 과일가격.keys():
print("{}는 {}원 입니다.".format(과일, 과일가격[과일]))
사과는 1000원 입니다.
배는 1500원 입니다.
items()
메소드를 이용하면 키와 값들의 튜플 형식의 반복 객체를 얻을 수 있습니다.
items() 메소드도 keys(), values()와 마찬가지로
view
객체를 반환합니다.
for 과일, 가격 in 과일가격.items():
print("{}는 {}원 입니다.".format(과일, 가격))
사과는 1000원 입니다.
배는 1500원 입니다.
열쇠가 사전에 있는지를 판단하기 위해서 in과 not in 연산자를
사용할 수 있습니다.
'사과' in 과일가격
True
이 메소드는 키가 사전에 없으면 다음과 같은 오류를 발생하기 때문에 미리 오류 방지를 위해 사용될 수 있습니다.
과일가격['오징어']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-125-d060fac1c03e> in <module>()
----> 1 과일가격['오징어']
KeyError: '오징어'
for 과일 in ['사과', '배', '오징어']:
if 과일 in 과일가격:
print("{}는 {}원 입니다.".format(과일, 과일가격[과일]))
else:
print("{}는 과일이 아닌 것 같은데??".format(과일))
사과는 1000원 입니다.
배는 1500원 입니다.
오징어는 과일이 아닌 것 같은데??
사전의 값에 포함되어 있는지를 판단할 때는 다음과 같이 values()를
이용할 수 있습니다.
1500 in 과일가격.values()
True
그 밖에 get(), update 메소드들이 있습니다.
과일가격.get('사과')
1000
update는 사전형을 인자로 넘겨준다. 넘겨지는 사전의 열쇠가 이미
있으면 대응되는 값을 변경하고 없으면 열쇠와 값을 추가합니다.
과일가격.update({'사과': 1100, '파인애플': 5500})
과일가격
{'배': 1500, '사과': 1100, '파인애플': 5500}
사과는 기존 사전 과일가격의 열쇠이므로 값이 1000에서
1100으로 변경되었고 파인애플은 새로운 열쇠이므로 기존 사전에
추가된 것을 볼 수 있습니다.
연습문제 3¶
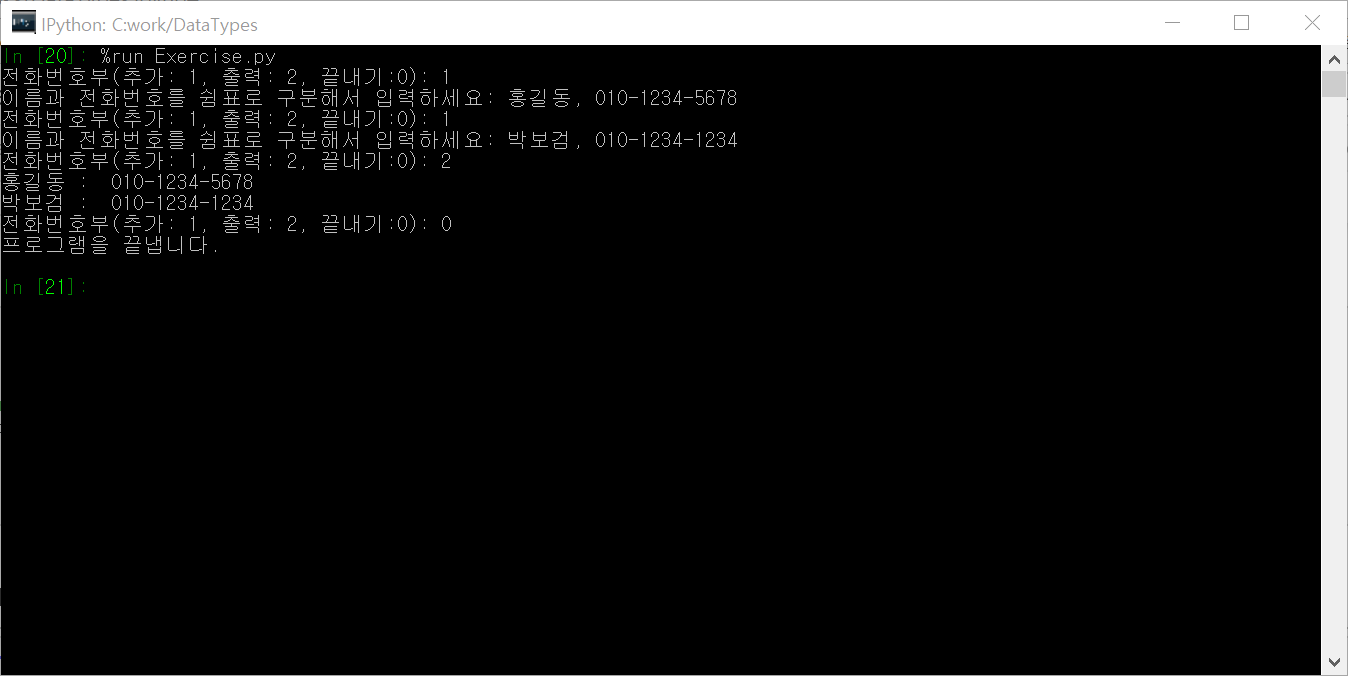
사용자로부터 이름과 전화번호를 입력받아 사전형으로 전화번호부를 만드시오. 아래 그림과 같이 추가, 출력, 끝내기 기능을 만드시오.
집합(set)¶
순서가 필요없고 중복되지 않는 원소들의 모임을 표현하기 위해서 파이썬에서는 집합(set)이란 데이터 형을 제공합니다. 집합은 원소의 포함관계 및 중복된 원소들을 제거하는데 사용됩니다. 두 집합의 합집합, 교집합, 차집합 등의 연산을 할 수 있는 메소들들이 있습니다.
집합은 중괄호 {}와 쉼표를 이용하거나
set(반복객체)
메소드를 사용해서 만들 수 있습니다. 빈 집합을 만들기 위해서는
set()만을 사용해야 합니다. 중괄호 {}는 빈 사전(dict)
객체를 만듭니다.
철수집 = {'거실', '부엌', '화장실', '사랑방'}
순이집 = set(['거실', '부엌', '화장실', '안방'])
집합의 원소의 갯수는 len(집합)을 이용합니다.
len(철수집)
4
집합에 원소를 추가하기 위해서는 add(원소)를 이용합니다.
철수집.add('안방')
print(철수집)
{'안방', '거실', '사랑방', '부엌', '화장실'}
합집합¶
print(철수집.union(순이집))
# 또는
print(철수집 | 순이집)
{'거실', '사랑방', '부엌', '안방', '화장실'}
{'거실', '사랑방', '부엌', '안방', '화장실'}
교집합¶
print(철수집.intersection(순이집))
# 또는
print(철수집 & 순이집)
{'안방', '거실', '화장실', '부엌'}
{'안방', '거실', '화장실', '부엌'}
차집합¶
print(철수집.difference(순이집))
# 또는
print(철수집 - 순이집)
{'사랑방'}
{'사랑방'}
포함관계¶
집합의 원소인지 아닌지를 판단하는 연산자는 in 또는 not in을
사용합니다.
'부엌' in 철수집
True
A가 B에 포함됩니다를 판단하는 메소드는 A.issubset(B) 또는
A <= B를 사용합니다. 진부분집합을 판단할 때는 A < B를
이용합니다. B가 A에 포함됩니다는 것을 판단할 때는 A.issuperset(B) 또는
A >= B를 사용합니다.
바 = {'사과', '배'}
구 = {'사과', '배', '감'}
바 < 구
True
열거형(Sequence)¶
리스트, 튜플, 문자열등과 같이 순서가 있는 항목들을 담고 있는 데이터 형을 열거형이라고 합니다. 열거형의 항목은 인덱스를 통해서 접근할 수 있습니다.
공통 연산¶
아래 표에서 s와 t는 열거형 객체입니다. i, j, k,
n은 정수입니다.
연산 |
결과 |
참고 |
|---|---|---|
|
|
|
|
|
|
|
|
(6)(7) |
|
|
(2)(7) |
|
|
|
|
|
(3)(4) |
|
|
(3)(5) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
참고
일반적으로
in,not in연산은 성분이 포함되어 있는지를 판단할 때 사용하지만str,bytesbytesarray열거형 같은 경우에는 문자열이 포함되어 있는지를 판단할 때 사용될 수 있습니다.>>> "gg" in "eggs" True
n이0보다 작거나 같을 때는 빈 객체를 반환합니다.s의 성분들이 복사되는 것이 아니라 참조가 되는 것에 주의해야 합니다.>>> lists = [[]] * 3 >>> lists [[], [], []] >>> lists[0].append(3) >>> lists [[3], [3], [3]]
[[]]은 빈 리스트[]를 성분으로 갖는 리스트입니다.[[]] * 3은 빈 리스트[]에 대한 3개의 참조를 성분으로 갖는다. 따라서 빈 리스트에 성분을 추가하면lists[0].append(3)모든 3개의 성분이 같이 바뀌는 것입니다.i또는j가 음수이면len(s) + i또는len(s) + j로 대체됩니다.-0은0입니다.len(s) + i또는len(s) + j가0보다 작으면 모두0을 사용하는 것 같다.s[i:j]란i보다 크거나 같고j보다 작은 인덱스에 대한 항목들을 나열합니다. 만약i또는j가len(s)보다 크면len(s)를 사용합니다. 만일i가 빠져있거나None이면0을 사용합니다. 만일j가 빠져있거나None이면len(s)를 사용합니다. 만일i가j보다 크거나 같으면, 빈 항목을 반환합니다.s[i:j:k]은i + n*k항목들의 나열입니다.n은0 <= n < (j-i)/k을 만족하는 정수입니다. 즉,i,i + k,i + 2*k,i + 3*k인덱스에 해당하는 항목들의 나열입니다.k가 양수일 때,i와j가len(s)보다 크면,i와j는len(s)를 사용합니다.k가 음수일 때,i와j가len(s)보다 크면,i와j는len(s) - 1를 사용합니다. 만일i또는j가 빠져 있으면 각각 끝 값을 사용합니다(k가 양수이면i는0,j는len(s)이고,k가 음수이면i는len(s) - 1이고j는-1처럼 계산해야 합니다).k는0이 될 수 없고,k가None이면1로 간주합니다.불변 열거형의 덧셈 연산 결과는 항상 새로운 객체입니다.
range열거형은 덧셈, 곱셈 연산을 지원하지 않는다.x가s안에 없으면index()함수는ValueError를 발생 시킨다.
가변 열거형 연산¶
연산 |
결과 |
참고 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
참고
반복가능 객체의 크기가 인덱스 갯수보다 작으면
s의 크기가t의 갯수에 맞추어 작아집니다. 반대로 크면s의 크기가 늘어난다. 만일j가i보다 작으면 반복가능 객체가i의 위치에 삽입됩니다. 버그?t의 갯수와s[i:j:k]의 갯수와 같아야 합니다.
다차원 열거형¶
이제까지는 일차원 열거형들에 대해서만 살펴봤다. 행과 열을 갖는 이차원 자료 구조를 표현하는 가장 쉬운 방법은 리스트의 리스트를 만드는 것입니다. 예를 들어 보자.
표 = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12]]
표
[[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
바깥 리스트는 4개의 리스트들로 이루어 졌고 안쪽 리스트들은 3개의 숫자들로 이루어졋다. 각 성분에 접근하려면 두 개의 인덱스가 필요하다. 첫번째는 바깥쪽 리스트의 성분을 접근하는 인덱스이고 다음은 선택된 리스트의 성분을 접근하는 인덱스가 필요하다. 즉 바깥쪽 리스트의 첫번째 성분은 다음과 같이 접근합니다.
표[0]
[1, 2, 3]
다음으로 그 안에 있는 첫번째 숫자 1은 다음과 같이 접근합니다.
표[0][0]
1
리스트는 안에 있는 성분을 변경할 수 있습니다.
표[0][0] = 100
표
[[100, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
일반적으로 이차원 구조를 만들 때 열의 갯수는 같도록 만들지만 꼭 그럴 필요는 없습니다. 다음과 같은 이차원 구조를 만들수도 있습니다.
표2 = [[1],
[2, 3, 4],
[5, 6]]
표2
[[1], [2, 3, 4], [5, 6]]
또한 3차원 구조도 다음과 같이 만들 수 있습니다.
표3 = [[[1, 2], [3, 4]],
[[5, 6], [7, 8]]]
표3
[[[1, 2], [3, 4]], [[5, 6], [7, 8]]]
표3[0][0][1]
2
다차원 열거형을 * 연산을 사용해서 만드는 것에 주의해야 합니다. *
연산은 객체들의 참조들을 만듭니다. 예를 들어 다음과 같이 빈 리스트 3개를
성분으로 갖는 리스트를 만들 때 * 연산을 사용해보자.
x = [[]] * 3
x
[[], [], []]
겉으로 보기에는 별다른 것을 알 수 없을 것입니다. 그런데 첫번째 빈 리스트에 값을 하나 추가해보자.
x[0].append('a')
x
[['a'], ['a'], ['a']]
첫번째 리스트에만 'a'를 추가했는데 나머지 빈 리스트에도 똑같은
값이 추가된 것을 알 수 있습니다. 이것은 [[]] * 3 연산은 안에 있는 빈
리스트 []의 참조를 3개 만들기 때문에 한 곳이 변해도 모든 곳이 같이
변하게 됩니다.
만일 서로 다른 빈 리스트들을 만들려면 리스트 축약을 이용하면 됩니다.
for문이 한 번 반복될 때마다 새로운 빈 리스트가 만들어집니다.
y = [[] for i in range(3)]
y
[[], [], []]
따라서 첫번째 성분 리스트를 변경하더라도 다른 것은 변하지 않는다.
y[0].append('yy')
y
[['yy'], [], []]
참조(reference)¶
객체를 생성하고 객체를 변수에 할당하는 것은 객체가 있는 메모리의 위치를 변수에 알려주는 것입니다. 이 변수는 객체를 참조합니다고 합니다. 마찬가지로 하나의 변수를 다른 변수에 할당함으로 두 변수가 모두 같은 객체를 참조하는 것입니다.
a = 10
print(id(a))
b = 10
print(id(b))
1652256512
1652256512
id(객체) 함수는 객체의 주소를 반환합니다. 위에서 같은 값을
반환한 것을 보니 a와 b는 같은 객체를 가리키고 있는 것입니다.
다음과 같이 리스트 객체를 만들어 목록이라는 변수에 할당하자.
목록 = ['양배추', '파', '마늘', '고구마']
그리고 새로운 변수 장바구니를 만들어 기존변수 목록을
할당하면 둘 다 같은 객체를 가리키는 것을 볼 수 있습니다.
장바구니 = 목록
목록
['양배추', '파', '마늘', '고구마']
id 함수를 이용해서 확인해봐도 같은 객체를 가리키는 것을 알 수 있습니다.
id(목록)
2402500363912
id(장바구니)
2402500363912
따라서 장바구니 변수에서 내용을 변경하면 목록의 내용도 함께
변경된 것을 알 수 있습니다.
장바구니[0] = '감자'
목록
['감자', '파', '마늘', '고구마']
다음은 [:]를 이용해서 기존의 리스트를 복사해서 새로운 리스트를
만들어 사용할 수 있습니다.
목록 = ['양배추', '파', '마늘', '고구마']
장바구니 = 목록[:]
장바구니는 같은 내용을 가지고 있지만 서로 다른 객체임을 알 수 있습니다.
장바구니
['양배추', '파', '마늘', '고구마']
id(목록)
2402500283656
id(장바구니)
2402500239624
따라서 한 쪽의 내용을 변경해도 다른 쪽은 아무런 영향을 받지 않는다.
장바구니[0] = '감자'
장바구니의 성분을 바꿨지만 목록은 변화가 없는 것을 알 수
있습니다. 장바구니와 목록이 가리키는 것은 서로 다른 객체이기
때문에 아무런 영향을 미치지 못하는 것입니다.
목록
['양배추', '파', '마늘', '고구마']
연습문제 4¶
다음 코드에서
import turtle
태현 = turtle.Turtle()
아미 = 태현
아미.color("hotpink")
태현과 아미는 서로 다른 거북이 인스턴스인가? 아미의 색깔을 바꾸면 태현의 색깔도 바뀌나?