Data Aggregation and Group Operations¶
In [2]:
import pandas as pd
import numpy as np
GroupBy Mechanics¶
그룹 연산은 쪼개고-적용하고-합치기(split-apply-combine) 과정으로 이루어진다. 쪼개기는 사용자가 지정한 키들에 따라 데이터프레임 또는 시리즈들을 그룹으로 분류한다. 분류된 그룹에 대해서 원하는 함수를 적용하여 결과를 만든다. 이 결과값을 다시 합쳐서 새로운 자료를 만들어낸다. 다음 그림을 참조하자.
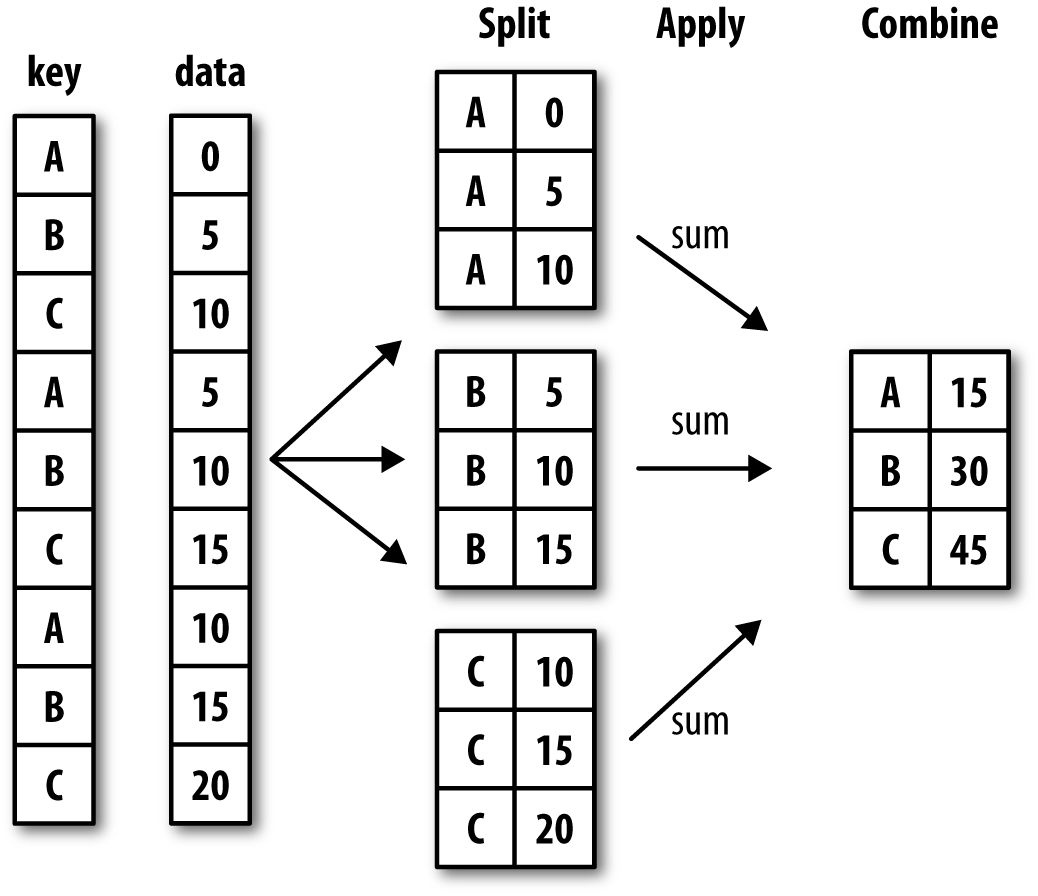
그룹으로 분류하는 키가 될 수 는 것으로는 다음과 같은 것이 있다/.
- 축과 같은 크기의 리스트 또는 넘파이 배열
- 데이터프레임의 열이름 리스트
- 사전형 또는 시리즈(행이름 또는 열이름에 대응되는 값으로 그룹 이름을 변경한다.)
- 지정된 축에 해당하는 이름들에 대한 함수
In [2]:
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'one', 'two', 'one'],
'data1' : np.random.randn(5),
'data2' : np.random.randn(5)})
df
Out[2]:
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | 1.672060 | -0.102965 |
| 1 | a | two | -0.546818 | -0.950657 |
| 2 | b | one | 0.773815 | 0.664140 |
| 3 | b | two | 0.577333 | 1.571693 |
| 4 | a | one | 1.450435 | -0.163659 |
data1 열을 key1 열에 대응하는 그룹으로 분류를 하고 싶으면
In [8]:
grouped = df['data1'].groupby(by=df['key1'])
grouped
Out[8]:
<pandas.core.groupby.groupby.SeriesGroupBy object at 0x000001B6A73BDB70>
이것은 데이터프레임 df['data1']의 groupby 메소드를 이용해
GroupBy 객체를 얻는다. 여기서 by= 선택인자로 key1열
시리즈가 대응된다. by=에 시리즈가 대응되면 데이터프레임의
groupby하는 축(여기서는 axis=0)의 인덱스 이름과 시리즈의
인덱스이름이 같은 것에 대응되는 시리즈 값으로 분류가 된다.
분류된 그룹에 대해서 합을 구하려면 GroupBy 객체의 sum() 메소드를
호출하면 된다.
In [18]:
grouped.sum()
Out[18]:
key1
a -0.651169
b 0.129813
Name: data1, dtype: float64
GroupBy 객체의 groups 속성을 이용하면 내부를 알 수 있다.
In [9]:
grouped.groups
Out[9]:
{'a': Int64Index([0, 1, 4], dtype='int64'),
'b': Int64Index([2, 3], dtype='int64')}
by=[df['key1'], df['key2']]와 같이 두 시리즈
df['key1'], df['key2']의 리스트로 설정하면 두 시리즈의 순서쌍
그룹으로 분류를 한다.
In [27]:
df['data1'].groupby([df['key1'], df['key2']]).sum()
Out[27]:
key1 key2
a one -0.807013
two 0.155844
b one 0.462492
two -0.332679
Name: data1, dtype: float64
결과 자료의 인덱스는 다중 인덱스를 갖는다.
데이터프레임에서 groupby 메소드를 호출할 때는 by=의 값으로
열이름에 대한 리스트를 지정해도 된다.
In [29]:
df.groupby(by=['key1']).sum()
Out[29]:
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | -0.651169 | 2.538845 |
| b | 0.129813 | -1.459336 |
숫자가 아닌 열 key2는 합을 구할 때 자동적으로 제외되는 것을 알 수
있다. 다음과 같이 여러 개의 열이름을 나열해도 된다.
In [30]:
df.groupby(by=['key1', 'key2']).sum()
Out[30]:
| data1 | data2 | ||
|---|---|---|---|
| key1 | key2 | ||
| a | one | -0.807013 | 0.698372 |
| two | 0.155844 | 1.840472 | |
| b | one | 0.462492 | -0.621391 |
| two | -0.332679 | -0.837945 |
각 그룹의 갯수를 세기 위해서는 size() 또는 count() 메소드를
사용하면 된다. count()는 NaN을 세지 않는다.
In [31]:
grouped.size()
Out[31]:
key1
a 3
b 2
Name: data1, dtype: int64
Iterating over groups¶
GroupBy 객체는 그룹 이름과 그룹에 대응되는 자료로 이루어진 순서쌍을
반환하는 반복가능 객체를 반환한다.
In [36]:
for name, data in df.groupby('key1'):
print(name)
print(data)
a
key1 key2 data1 data2
0 a one -2.077828 0.698218
1 a two 0.155844 1.840472
4 a one 1.270814 0.000154
b
key1 key2 data1 data2
2 b one 0.462492 -0.621391
3 b two -0.332679 -0.837945
In [37]:
for name, data in df.groupby(['key1', 'key2']):
print(name)
print(data)
('a', 'one')
key1 key2 data1 data2
0 a one -2.077828 0.698218
4 a one 1.270814 0.000154
('a', 'two')
key1 key2 data1 data2
1 a two 0.155844 1.840472
('b', 'one')
key1 key2 data1 data2
2 b one 0.462492 -0.621391
('b', 'two')
key1 key2 data1 data2
3 b two -0.332679 -0.837945
그룹별 자료를 다음과 같이 접근할 수 있다.
In [73]:
pieces = dict(list(df.groupby('key1')))
In [74]:
pieces['a']
Out[74]:
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | -2.077828 | 0.698218 |
| 1 | a | two | 0.155844 | 1.840472 |
| 4 | a | one | 1.270814 | 0.000154 |
groupby는 기본적으로 axis=0에 대해서 연산을 한다. 열에
대해서 하고 싶으면 axis=1을 사용한다.
In [75]:
df.dtypes
Out[75]:
key1 object
key2 object
data1 float64
data2 float64
dtype: object
key1과 key2는 같은 object 형으로 하나의 그룹으로 묶고
data1과 data2는 float64로 하나의 그룹을 묶어 합을 하면
다음과 같이 각 행에 같은 그룹에 대해서 합을 계산한다.
In [77]:
df.groupby(df.dtypes, axis=1).sum()
Out[77]:
| float64 | object | |
|---|---|---|
| 0 | -1.379609 | aone |
| 1 | 1.996316 | atwo |
| 2 | -0.158899 | bone |
| 3 | -1.170624 | btwo |
| 4 | 1.270968 | aone |
Selecting a Column or Subset of Columns¶
그룹화된 자료 중 일부 열만 선택해서 함수를 적용할 수 있다. 다음은
data1에 대해서만 함수를 적용한 것이다.
In [79]:
df.groupby('key1')['data1'].sum()
Out[79]:
key1
a -0.651169
b 0.129813
Name: data1, dtype: float64
In [80]:
df.groupby(['key1', 'key2'])['data2'].sum()
Out[80]:
key1 key2
a one 0.698372
two 1.840472
b one -0.621391
two -0.837945
Name: data2, dtype: float64
Grouping with Dicts and Series¶
사전형과 시리즈형을 사용해서 그룹화하자.
In [82]:
people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
people.iloc[2:3, [1, 2]] = np.nan
people
Out[82]:
| a | b | c | d | e | |
|---|---|---|---|---|---|
| Joe | -1.928135 | -1.003535 | 0.163005 | 0.069764 | -1.190555 |
| Steve | 0.017499 | -2.051024 | -0.165791 | 1.632082 | -0.013469 |
| Wes | -0.586628 | NaN | NaN | -2.198450 | -0.343128 |
| Jim | -0.218038 | 0.597658 | 0.811994 | -0.488562 | 0.895896 |
| Travis | -1.078036 | -1.789211 | 2.072730 | 1.046389 | -1.066292 |
열이름에 대응하는 그룹이름이 다음과 같이 사전형으로 주어졌다.
In [83]:
mapping = {'a': 'red', 'b': 'red', 'c': 'blue', 'd': 'blue', 'e': 'red', 'f' : 'orange'}
이것을 그룹 분류 키로 사용하면 다음과 같이 red와 blue 그룹으로
합을 계산한다.
In [85]:
people.groupby(mapping, axis=1).sum()
Out[85]:
| blue | red | |
|---|---|---|
| Joe | 0.232768 | -4.122226 |
| Steve | 1.466292 | -2.046994 |
| Wes | -2.198450 | -0.929756 |
| Jim | 0.323432 | 1.275516 |
| Travis | 3.119119 | -3.933540 |
f에 대응되는 열이름이 존재하지 않으므로 아무런 결과가 나오질
않는다. 시리즈의 경우도 마찬가지이다.
In [86]:
map_series = pd.Series(mapping)
map_series
Out[86]:
a red
b red
c blue
d blue
e red
f orange
dtype: object
In [90]:
people.groupby(map_series, axis=1).count()
Out[90]:
| blue | red | |
|---|---|---|
| Joe | 2 | 3 |
| Steve | 2 | 3 |
| Wes | 1 | 2 |
| Jim | 2 | 3 |
| Travis | 2 | 3 |
Grouping with Functions¶
by= 값으로 함수를 지정할 수 있다. 이 함수는 각 축에 해당하는 인덱스
이름을 인자로 갖는 함수이다. 다음과 같이 len 함수를 지정하면 행
인덱스에 해당하는 사람 이름이 인자로 넘어가서 반환값은 문자열의 길이가
된다. 따라서 len(Joe) = len(Wes) = len(Jim) = 3 으로 같은 그룹에
속하게 된다.
In [91]:
people.groupby(len).sum()
Out[91]:
| a | b | c | d | e | |
|---|---|---|---|---|---|
| 3 | -2.732801 | -0.405878 | 0.974999 | -2.617249 | -0.637787 |
| 5 | 0.017499 | -2.051024 | -0.165791 | 1.632082 | -0.013469 |
| 6 | -1.078036 | -1.789211 | 2.072730 | 1.046389 | -1.066292 |
다음과 같이 함수, 리스트, 배열, 사전, 시리즈들의 결합된 리스트도 문제없다. 내부적으로 모두 배열로 변환된다.
In [92]:
key_list = ['one', 'one', 'one', 'two', 'two']
In [94]:
people.groupby([len, key_list]).min()
Out[94]:
| a | b | c | d | e | ||
|---|---|---|---|---|---|---|
| 3 | one | -1.928135 | -1.003535 | 0.163005 | -2.198450 | -1.190555 |
| two | -0.218038 | 0.597658 | 0.811994 | -0.488562 | 0.895896 | |
| 5 | one | 0.017499 | -2.051024 | -0.165791 | 1.632082 | -0.013469 |
| 6 | two | -1.078036 | -1.789211 | 2.072730 | 1.046389 | -1.066292 |
Grouping by Index Levels¶
다중 인덱스일 때는 level= 인자를 지정함으로 그룹화할 수 있다.
In [95]:
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'],
[1, 3, 5, 1, 3]],
names=['cty', 'tenor'])
hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df
Out[95]:
| cty | US | JP | |||
|---|---|---|---|---|---|
| tenor | 1 | 3 | 5 | 1 | 3 |
| 0 | -0.136924 | 0.581110 | -1.720461 | -0.477307 | -1.197030 |
| 1 | -2.292118 | -1.074455 | -0.795925 | 0.709886 | -2.028176 |
| 2 | -1.478699 | 0.231938 | 0.398400 | 1.913787 | 0.322614 |
| 3 | 1.749851 | -0.285183 | 0.876492 | -1.288788 | -0.205515 |
In [97]:
hier_df.groupby(level='cty', axis=1).count()
Out[97]:
| cty | JP | US |
|---|---|---|
| 0 | 2 | 3 |
| 1 | 2 | 3 |
| 2 | 2 | 3 |
| 3 | 2 | 3 |
자료 집계(Data Aggregation)¶
자표 집계(aggregation)란 배열을 변형해서 결과로 스칼라값을 만들어 내는
것을 의미한다. 앞에서 보았던 mean, sum, count, min 등이
집계의 예들이다.
다음은 `GroupBy`에 의해서 최적화된 메소드들이다.
| 함수 이름 | Description |
|---|---|
count |
Number of non-NA values in the group |
sum |
Sum of non-NA values |
mean |
Mean of non-NA values |
median |
Arithmetic median of non-NA values |
std, var |
Unbiased (n – 1 denominator) standard deviation and variance |
min, max |
Minimum and maximum of non-NA values |
prod |
Product of non-NA values |
first, last |
First and last non-NA values |
이것들뿐만아니라 자신만의 집계 함수를 만들어 적용할 수 있다.
quantile 함수는 GroupBy 객체에 의해서 구현된 함수는 아니지만
시리즈와 데이터프레임의 열에 대해서 적용할 수 있기 때문에 사용가능하다.
In [3]:
df
Out[3]:
| key1 | key2 | data1 | data2 | |
|---|---|---|---|---|
| 0 | a | one | 1.672060 | -0.102965 |
| 1 | a | two | -0.546818 | -0.950657 |
| 2 | b | one | 0.773815 | 0.664140 |
| 3 | b | two | 0.577333 | 1.571693 |
| 4 | a | one | 1.450435 | -0.163659 |
In [4]:
grouped = df.groupby('key1')
grouped.quantile(0.9)
Out[4]:
| 0.9 | data1 | data2 |
|---|---|---|
| key1 | ||
| a | 1.627735 | -0.115104 |
| b | 0.754166 | 1.480937 |
자신이 만든 함수를 사용하려면 aggregate 또는 agg 메소드를
이용한다. 사용자 집계함수는 배열을 인자로 갖고 반환값은 스칼라가 되게
만든다.
In [5]:
def peak_to_peak(arr):
return arr.max() - arr.min()
In [6]:
grouped.agg(peak_to_peak)
Out[6]:
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | 2.218878 | 0.847692 |
| b | 0.196482 | 0.907553 |
집계함수가 아닌 describe 함수 같은 것도 적용이되는 것을 알 수 있는데
이것은 다음 절에 나오는 apply 메소드를 사용한 것이다.
In [7]:
grouped.describe()
Out[7]:
| data1 | data2 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | |
| key1 | ||||||||||||||||
| a | 3.0 | 0.858559 | 1.222126 | -0.546818 | 0.451808 | 1.450435 | 1.561247 | 1.672060 | 3.0 | -0.405761 | 0.472869 | -0.950657 | -0.557158 | -0.163659 | -0.133312 | -0.102965 |
| b | 2.0 | 0.675574 | 0.138934 | 0.577333 | 0.626453 | 0.675574 | 0.724694 | 0.773815 | 2.0 | 1.117916 | 0.641737 | 0.664140 | 0.891028 | 1.117916 | 1.344804 | 1.571693 |
Column-Wise and Multiple Function Application¶
In [8]:
tips = pd.read_csv('data/tips.csv')
tips.head()
Out[8]:
| total_bill | tip | smoker | day | time | size | |
|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 |
In [9]:
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()
Out[9]:
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
In [10]:
grouped = tips.groupby(['day', 'smoker'])
In [11]:
grouped_pct = grouped['tip_pct']
In [12]:
grouped_pct.agg('mean')
Out[12]:
day smoker
Fri No 0.151650
Yes 0.174783
Sat No 0.158048
Yes 0.147906
Sun No 0.160113
Yes 0.187250
Thur No 0.160298
Yes 0.163863
Name: tip_pct, dtype: float64
집계함수를 여러 개 건네주면 각각에 대응하는 열을 만들어 데이터프레임이 반환된다.
In [13]:
grouped_pct.agg(['mean', 'std', peak_to_peak])
Out[13]:
| mean | std | peak_to_peak | ||
|---|---|---|---|---|
| day | smoker | |||
| Fri | No | 0.151650 | 0.028123 | 0.067349 |
| Yes | 0.174783 | 0.051293 | 0.159925 | |
| Sat | No | 0.158048 | 0.039767 | 0.235193 |
| Yes | 0.147906 | 0.061375 | 0.290095 | |
| Sun | No | 0.160113 | 0.042347 | 0.193226 |
| Yes | 0.187250 | 0.154134 | 0.644685 | |
| Thur | No | 0.160298 | 0.038774 | 0.193350 |
| Yes | 0.163863 | 0.039389 | 0.151240 |
(함수이름, 함수) 순서쌍을 건네면 열이름에 함수이름이 지정된다.
In [17]:
grouped_pct.agg([('평균', 'mean'), ('표준편차', np.std)])
Out[17]:
| 평균 | 표준편차 | ||
|---|---|---|---|
| day | smoker | ||
| Fri | No | 0.151650 | 0.028123 |
| Yes | 0.174783 | 0.051293 | |
| Sat | No | 0.158048 | 0.039767 |
| Yes | 0.147906 | 0.061375 | |
| Sun | No | 0.160113 | 0.042347 |
| Yes | 0.187250 | 0.154134 | |
| Thur | No | 0.160298 | 0.038774 |
| Yes | 0.163863 | 0.039389 |
데이터프레임에 더 많은 일을 할 수 있다. 즉, 여러 개의 함수들을 각각의 열에 동시에 적용할 수 있을 뿐 아니라 각 열에 다른 함수들을 적용할 수도 있다. 우선 여러 개의 함수들을 열에 동시에 적용하는 예를 보자.
In [20]:
functions = ['count', 'mean' ,'max']
result = grouped['tip_pct', 'total_bill'].agg(functions)
result
Out[20]:
| tip_pct | total_bill | ||||||
|---|---|---|---|---|---|---|---|
| count | mean | max | count | mean | max | ||
| day | smoker | ||||||
| Fri | No | 4 | 0.151650 | 0.187735 | 4 | 18.420000 | 22.75 |
| Yes | 15 | 0.174783 | 0.263480 | 15 | 16.813333 | 40.17 | |
| Sat | No | 45 | 0.158048 | 0.291990 | 45 | 19.661778 | 48.33 |
| Yes | 42 | 0.147906 | 0.325733 | 42 | 21.276667 | 50.81 | |
| Sun | No | 57 | 0.160113 | 0.252672 | 57 | 20.506667 | 48.17 |
| Yes | 19 | 0.187250 | 0.710345 | 19 | 24.120000 | 45.35 | |
| Thur | No | 45 | 0.160298 | 0.266312 | 45 | 17.113111 | 41.19 |
| Yes | 17 | 0.163863 | 0.241255 | 17 | 19.190588 | 43.11 | |
보는바와같이 결과는 다중 인덱스로 되어 있다. 각 열이름으로 접근할 수 있다.
In [21]:
result['tip_pct']
Out[21]:
| count | mean | max | ||
|---|---|---|---|---|
| day | smoker | |||
| Fri | No | 4 | 0.151650 | 0.187735 |
| Yes | 15 | 0.174783 | 0.263480 | |
| Sat | No | 45 | 0.158048 | 0.291990 |
| Yes | 42 | 0.147906 | 0.325733 | |
| Sun | No | 57 | 0.160113 | 0.252672 |
| Yes | 19 | 0.187250 | 0.710345 | |
| Thur | No | 45 | 0.160298 | 0.266312 |
| Yes | 17 | 0.163863 | 0.241255 |
함수이름과 함수의 튜플로도 접근가능하다.
In [28]:
ftuples = [('평균', 'mean'), ('분산', np.var)]
In [29]:
grouped['tip_pct', 'total_bill'].agg(ftuples)
Out[29]:
| tip_pct | total_bill | ||||
|---|---|---|---|---|---|
| 평균 | 분산 | 평균 | 분산 | ||
| day | smoker | ||||
| Fri | No | 0.151650 | 0.000791 | 18.420000 | 25.596333 |
| Yes | 0.174783 | 0.002631 | 16.813333 | 82.562438 | |
| Sat | No | 0.158048 | 0.001581 | 19.661778 | 79.908965 |
| Yes | 0.147906 | 0.003767 | 21.276667 | 101.387535 | |
| Sun | No | 0.160113 | 0.001793 | 20.506667 | 66.099980 |
| Yes | 0.187250 | 0.023757 | 24.120000 | 109.046044 | |
| Thur | No | 0.160298 | 0.001503 | 17.113111 | 59.625081 |
| Yes | 0.163863 | 0.001551 | 19.190588 | 69.808518 | |
원하는 열들에 원하는 함수들을 적용할 수도 있다. 다음은 tip 열에
np.max 함수를 size 열에 sum 함수를 적용한 것이다.
In [30]:
grouped.agg({'tip': np.max, 'size': 'sum'})
Out[30]:
| tip | size | ||
|---|---|---|---|
| day | smoker | ||
| Fri | No | 3.50 | 9 |
| Yes | 4.73 | 31 | |
| Sat | No | 9.00 | 115 |
| Yes | 10.00 | 104 | |
| Sun | No | 6.00 | 167 |
| Yes | 6.50 | 49 | |
| Thur | No | 6.70 | 112 |
| Yes | 5.00 | 40 |
뿐만아니라 한 열에 여러 개의 함수들을 적용할 수도 있다.
In [31]:
grouped.agg({'tip_pct': ['min', 'max', 'mean'], 'size': 'sum'})
Out[31]:
| tip_pct | size | ||||
|---|---|---|---|---|---|
| min | max | mean | sum | ||
| day | smoker | ||||
| Fri | No | 0.120385 | 0.187735 | 0.151650 | 9 |
| Yes | 0.103555 | 0.263480 | 0.174783 | 31 | |
| Sat | No | 0.056797 | 0.291990 | 0.158048 | 115 |
| Yes | 0.035638 | 0.325733 | 0.147906 | 104 | |
| Sun | No | 0.059447 | 0.252672 | 0.160113 | 167 |
| Yes | 0.065660 | 0.710345 | 0.187250 | 49 | |
| Thur | No | 0.072961 | 0.266312 | 0.160298 | 112 |
| Yes | 0.090014 | 0.241255 | 0.163863 | 40 | |
Returning Aggregated Data Without Row Indexes¶
그룹할 키들은 기본적으로 행 인덱스에 위치하게 된다. 이것을 열로 남게하고
싶으면 as_index=False로 한다.
In [32]:
tips.groupby(['day', 'smoker'], as_index=False).mean()
Out[32]:
| day | smoker | total_bill | tip | size | tip_pct | |
|---|---|---|---|---|---|---|
| 0 | Fri | No | 18.420000 | 2.812500 | 2.250000 | 0.151650 |
| 1 | Fri | Yes | 16.813333 | 2.714000 | 2.066667 | 0.174783 |
| 2 | Sat | No | 19.661778 | 3.102889 | 2.555556 | 0.158048 |
| 3 | Sat | Yes | 21.276667 | 2.875476 | 2.476190 | 0.147906 |
| 4 | Sun | No | 20.506667 | 3.167895 | 2.929825 | 0.160113 |
| 5 | Sun | Yes | 24.120000 | 3.516842 | 2.578947 | 0.187250 |
| 6 | Thur | No | 17.113111 | 2.673778 | 2.488889 | 0.160298 |
| 7 | Thur | Yes | 19.190588 | 3.030000 | 2.352941 | 0.163863 |
물론 as_index=True로 한 결과에 대해서 reset_index()를 해도
같은 결과가 나온다.