문서 데이터¶
데이터 수집 및 파싱(Parsing)¶
웹 페이지 읽기¶
requests 모듈을
이용하여 웹 페이지를 읽어 온다. requests 모듈은 http 요청및
응답을 처리하는 편리한 방법들을 제공한다.
다음(daum) 홈페이지 출력¶
다음(daum) 홈페이지에 접속해서 HTML 문서를 가져와 화면에 출력하는 예이다.
In [42]:
import requests
resp = requests.get('http://daum.net') # 웹 사이트 접속
if (resp.status_code == requests.codes.ok): # 응답이 정상
html = resp.text # 웹 페이지 읽기
print(html.split('\n')[0:10]) # 웹 페이지 10줄 출력
['<!DOCTYPE html>', '<html lang="ko" class="">', '<head>', '<meta charset="utf-8"/>', '<title>Daum</title>', '<meta property="og:url" content="https://www.daum.net/">', '<meta property="og:type" content="website">', '<meta property="og:title" content="Daum">', '<meta property="og:image" content="//i1.daumcdn.net/svc/image/U03/common_icon/5587C4E4012FCD0001">', '<meta property="og:description" content="나의 관심 콘텐츠를 가장 즐겁게 볼 수 있는 Daum">']
requests.get(사이트주소)은 요청 메시지의 get 메소드를 이용하여
사이트 주소의 페이지를 요청한다. resp.status_code는 응답 객체의
상태를 나타내는 것으로 정상이면 200을 반환한다.
requests.codes.ok는 정상 코드 200을 나타내는 상수이다.
resp.text은 웹 페이지의 html 페이지를 반환한다. 클라이언트의
잘못된 요청에 대해 서버는 여러 가지 에러를 반환할 수 있다.(에러 코드
4xx, 5xx) 이러한 응답에 대해서 Response.raise_for_status() 메소드를
이용해 예외를 발생시킬 수 있다.
구글 검색 결과 출력¶
구글에 접속해서 원하는 단어를 검색하여 출력할 수 있다. 구글에서 검색어를
입력하면 주소창에 search?q=검색어와 같은 문자열이 입력되어 있는
것을 확인할 수 있다. 이것을 이용해 다음과 같이 직접 검색어를 사이트
주소와 함께 입력해 주면 검색 결과를 얻을 수 있다.
In [43]:
import requests
resp = requests.get('https://google.co.kr/search?q=인공지능')
if (resp.status_code == requests.codes.ok):
html = resp.text
print(html[:100], '...중간 생략...', html[-100:], sep='\n')
<!doctype html><html itemscope="" itemtype="http://schema.org/SearchResultsPage" lang="ko"><head><me
...중간 생략...
"/client_204?&atyp=i&biw="+a+"&bih="+b+"&ei="+google.kEI);}).call(this);})();</script></body></html>
인공지능이란 단어를 검색한 결과를 출력한 것이다. 내용이 너무 길어 중간 생략을 했다.
직접하기
- 다음(daum) 사이트에서 “날씨”를 검색하여 결과를 출력하시오.
파싱(Beautiful Soup)¶
BeautifulSoup 모듈을 이용해서 웹 페이지에서 필요한 정보들을 찾아낼 수 있다. 포털 사이트에서 주요 뉴스 제목을 찾아내거나 검색 사이트에서 원하는 단어를 검색한 결과를 볼 수 있다.
설치¶
pip install beautifulsoup4 # 또는
conda install -c anaconda beautifulsoup4 # 아나콘다를 이용할 경우
BeautifulSoup 웹페이지 파싱¶
웹 문서를 입력받아 bs객체를 만든다. bs 객체를 이용하여 필요한 정보들에
접근해서 원하는 것들을 수집할 수 있다. 원하는 성분으로 접근하는 방법은
여러 가지가 있으나 select() 메소드를 이용하는 방법이 있다.
select 메소드의 인자는 CSS(Cascading Style
Sheets) selector 조합
문자열을 사용한다. css selector에 대한 자세한 설명은 W3 Schools CSS
Selector
Reference를
참조한다. 다음은 몇 가지 예를 보여준다.
html 성분(element 또는 tag)은 다음과 같은 형식으로 이루어져 있다.
<tag_or_element attribute="value">text</tag_or_element>
다음은 html 예제의 일부이다.
<div class="intro"> <!-- div는 성분, class는 속성, "intro"는 class 속성값이다.-->
<p>My name is Donald <span id="Lastname">Duck.</span></p>
<p id="my-Address">I live in Duckburg</p>
<p>I have many friends:</p>
</div>
| Selector | 예제 | 설명 | CSS 버전 |
|---|---|---|---|
.class |
.intro |
class="intro"인 모든 성분
선택 |
1 |
#id |
#firstname |
id="firstname"인 모든 성분
선택 |
1 |
* |
* |
모든 성분 선택 | 2 |
element * |
div * |
div 안에 있는(자손) 모든 성분
선택. 중복하면서 선택된다. |
2 |
element |
p |
<p> 성분 모두 선택 |
1 |
element, elemen
t |
div, p |
<div> 또는 <p>를 갖는
모든 성분 선택. 중복을 허락하지
않는다. |
1 |
| ``element element `` | div p |
<div> 성분 안에(자손) 모든
<p> 성분 선택 |
1 |
element > eleme
nt |
div > p |
부모가 <div>인 모든 <p>
성분 선택 |
2 |
element + eleme
nt |
div + p |
<div>와 형제이며 <div>
바로 아래쪽에 붙어 있는 <p>
성분 선택 |
2 |
element1 ~ elem
ent2 |
p ~ ul |
<p> 와 형제이며 <p>
아래쪽에 있는 모든 <ul> 성분들
선택 |
3 |
[attribute] |
[target] |
속성이 target인 모든 성분
선택 |
2 |
[attribute=valu
e] |
[target=_bla
nk] |
속성이 target이고
target의 값이 _blank인
모든 성분 선택 |
2 |
[attribute~=val
ue] |
[title~=flow
er] |
title속성을 갖고 속성값이
flower를 포함하는 모든 성분들
선택 |
2 |
[attribute|=value] |
|
속성이 lang이고 속성의 값이
en 또는 en-로 시작하는
모든 성분 선택 |
2 |
| ``:nth-of-type(n) `` | p:nth-of-typ
e(2) |
<p>의 부모 아래에 있는 두번째
<p>성분 선택 |
3 |
import bs4
html = "<html><head><title>제목</title></head><body>...생략...</body></html>"
bs = bs4.BeautifulSoup(html, 'html.parser')
In [44]:
import bs4
html = """
<html>
<head>
</head>
<body>
<h1>Welcome to My Homepage</h1>
<div class="intro">
<p>My name is Donald <span id="Lastname">Duck.</span></p>
<p id="my-Address">I live in Duckburg</p>
<p>I have many friends:</p>
</div>
<ul id="Listfriends">
<li>Goofy</li>
<li>Mickey</li>
<li>Daisy</li>
<li>Pluto</li>
</ul>
<p>All my friends are great!<br>
But I really like Daisy!!</p>
<p lang="it" title="Hello beautiful">Ciao bella</p>
<h3>We are all animals!</h3>
<p><b>My latest discoveries have led me to believe that we are all animals:</b></p>
<table>
<thead>
<tr>
<th>Name</th> <th>Type of Animal</th>
</tr>
</thead>
<tr>
<td>Mickey</td> <td>Mouse</td>
</tr>
<tr>
<td>Goofey</td> <td>Dog</td>
</tr>
<tr>
<td>Daisy</td> <td>Duck</td>
</tr>
<tr>
<td>Pluto</td> <td>Dog</td>
</tr>
</table>
</body>
</html>
"""
bs = bs4.BeautifulSoup(html, 'html.parser')
bs.select('table')
Out[44]:
[<table>
<thead>
<tr>
<th>Name</th> <th>Type of Animal</th>
</tr>
</thead>
<tr>
<td>Mickey</td> <td>Mouse</td>
</tr>
<tr>
<td>Goofey</td> <td>Dog</td>
</tr>
<tr>
<td>Daisy</td> <td>Duck</td>
</tr>
<tr>
<td>Pluto</td> <td>Dog</td>
</tr>
</table>]
다음 html 문서를 이용해서 예제들을 살펴보자.
In [45]:
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister-act" id="link3">Tillie</a>;
<a href="https://example.com/tillie" class="sister">Secure Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
<div class="box clever">
<p>Box Office</p>
<p>Clever guy</p>
<p>Gorgeous actress</p>
</div>
</body>
</html>
"""
성분들을 찾는다.
In [46]:
soup = bs4.BeautifulSoup(html_doc, 'html.parser')
태그 이름이 title인 모든 성분을 찾는다.
In [47]:
soup.select('title')
Out[47]:
[<title>The Dormouse's story</title>]
p의 부모의 자식 중 3번째 p를 찾는다.
In [48]:
soup.select("p:nth-of-type(3)")
Out[48]:
[<p class="story">...</p>]
원래는 <p>Gorgeous actress</p>도 찾아야 하는데 버그인 것 같다.
CSS에서는 정상적으로 작동하는 것을 알 수 있다.
직접하기
soup.select("p:nth-of-type(3)")를 CSS에서 확인해보자.
성분 밑의 성분 찾기
body의 자손 중 a 성분을 모두 찾는다.
In [49]:
soup.select("body a")
Out[49]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
html 자손으로 head 자손 중 title 성분을 모두 찾는다.
In [50]:
soup.select("html head title")
Out[50]:
[<title>The Dormouse's story</title>]
성분 바로 밑의 성분 찾기
head 성분의 자식 중 title 성분을 모두 찾는다.
In [51]:
soup.select("head > title")
Out[51]:
[<title>The Dormouse's story</title>]
p의 자식 중 a인 성분 모두 찾는다.
In [52]:
soup.select("p > a")
Out[52]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
p의 자식 중 a 성분들 중에서 2번째 성분을 찾는다.
In [53]:
soup.select("p > a:nth-of-type(2)")
Out[53]:
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
p의 자식 중 id가 link1인 성분을 찾는다.
In [54]:
soup.select("p > #link1")
Out[54]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
body 자식 중 a 성분을 찾지만 없으므로 빈 리스트가 된다.
In [55]:
soup.select("body > a")
Out[55]:
[]
같은 수준의 성분들 찾기
id가 link1인 태그의 형제들 중 class 값이 sister인
모든 성분들을 찾는다.
In [56]:
soup.select("#link1 ~ .sister")
Out[56]:
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
id가 link1인 태그의 형제들 중 id가 link1인 성분
바로 아래 붙어있는 class 값이 sister인 성분을 찾는다.
In [57]:
soup.select("#link1 + .sister")
Out[57]:
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
CSS 클래스에 의한 성분 찾기
클래스 값이 sister인 성분들 모두 찾는다.
In [58]:
soup.select(".sister")
Out[58]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
클래스 속성값이 단어 sister를 포함하는 모든 성분을 찾는다.
In [59]:
soup.select("[class~=sister]")
Out[59]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
|는 뒤에 하이픈(-)이 있어도 찾는다.
In [60]:
soup.select("[class|=sister]")
Out[60]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
클래스 속성값이 si를 포함하는 모든 성분을 찾는다. ~와 다른
점은 ~는 단어 전체를 찾고 *는 부분 문자열이 포함된 것을
찾는다.
In [61]:
soup.select("[class*=si]")
Out[61]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
ID에 의한 성분 찾기
id가 link1인 성분을 찾는다.
In [62]:
soup.select("#link1")
Out[62]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
아이디가 link2이며 태그가 a인 성분을 찾는다.
In [63]:
soup.select("a#link2")
Out[63]:
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
속성에 의해 찾기
href 속성을 갖는 모든 a 태그들을 찾는다.
In [64]:
soup.select('a[href]')
Out[64]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
속성값에 의한 찾기
a 태그의 속성 href의 값이 http://example.com/elsie인
모든 성분을 찾는다.
In [65]:
soup.select('a[href="http://example.com/elsie"]')
Out[65]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
href 속성값 중 http로 시작하는 a 태그들 모두를 찾는다.
In [66]:
soup.select('a[href^="http"]')
Out[66]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
태그 a의 속성이 href이고 href의 속성값이
tillie로 끝나는 성분들을 찾는다.
In [67]:
soup.select('a[href$="tillie"]')
Out[67]:
[<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
속성 href의 값이 .com/el을 포함하는 태그 a들을 모두
찾는다.
In [68]:
soup.select('a[href*=".com/el"]')
Out[68]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
네이버 금융 사이트에서 헤드라인 뉴스 제목 발췌¶
In [14]:
import requests, bs4
resp = requests.get('http://finance.naver.com/')
resp.raise_for_status()
resp.encoding='euc-kr'
html = resp.text
bs = bs4.BeautifulSoup(html, 'html.parser')
print(bs.prettify()[0:100], "\n.\n.\n.\n", bs.prettify()[-100:])
tags = bs.select('div.news_area h2 a') # 헤드라인 뉴스 제목
title = tags[0].getText()
print("헤드라인 제목: ", title)
<html lang="ko">
<head>
<title>
네이버 금융
</title>
<meta content="text/html; charset=utf-8" h
.
.
.
, 이미지 리플레시
jindo.$Fn(mainPageDomReadyFn).attach(document, "domready");
</script>
</body>
</html>
헤드라인 제목: "한국 기업 이익 증가 추세 지속"…유..
직접하기
- 다음(daum) 사이트의 실시간 이슈 검색어를 추출해 보시오.
- 네이버 사이트에서 코스피 실시간 지수를 출력하시오.
- 네이버 환율
사이트에서
엔화 현찰 살때 팔때 환율을 출력하시오.
iframe으로 연결되어 있어서 사이트 주소를 정확히 입력해야 한다.
셀레늄(Selenium)¶
Selenium은 웹 브라우저의 기능을 하도록 하는 모듈이다. 브라우저를 직접 실행하지 않고 selenium 메소드들을 이용해서 웹 브라우저 기능을 대신할 수 있게 한다. Selenium은 Selenium 2(Selenium WebDriver), Selenium 1(Selenium RC), Selenium IDE, Selenium-Grid 툴로 이루어 졌다. 우리가 사용하는 것은 Selenium 2(Selenium WebDriver)이다. 이것은 프로그래밍 언어(Java, C#, Python, Javascript등)에 맞는 인터페이스를 제공하여 프로그래밍을 이용하여 사용하기 편리하다. Selenium 2를 이용하기 위해서는 웹 브라우저에 맞는 드라이버를 다운로드 해야 한다. 드라이버는 크롬, 파이어폭스, PhantomJS등이 있다. 여기서는 브라우저를 실행시키지 않고 사용할 수 있는 크롬 드라이버(headless 옵션 사용)를 이용한다. 파이썬에서 사용하는 selenium에 대한 문서는 http://selenium-python.readthedocs.io/index.html을 참고한다. 더 자세한 사용법은 Selenium 파이썬 웹드라이버 API를 참조하자.
드라이버 다운로드¶
크롬 드라이버를 인터넷으로부터 다운받아 작업 디렉토리 아래 drivers
폴더에 넣는다. 다운로드하는데 약간의 시간이 걸린다.
In [1]:
import urllib.request
import os
driver_dir = 'drivers'
if not os.path.exists(driver_dir):
os.makedirs(driver_dir)
url = 'https://chromedriver.storage.googleapis.com/2.38/chromedriver_win32.zip'
_, zip_file = os.path.split(url)
zip_path = os.path.join(driver_dir, zip_file)
if not os.path.exists(zip_path):
urllib.request.urlretrieve(url, zip_path)
압축해제¶
다운받은 파일을 압축해제한다.
In [9]:
import zipfile
if not os.path.exists(zip_path):
zip_ref = zipfile.ZipFile(zip_path, 'r')
for fname in zip_ref.namelist():
fpath = os.path.join(driver_dir, fname)
if os.path.exists(fpath):
os.remove(fpath)
zip_ref.extract(fname, driver_dir)
# zip_ref.extractall(driver_dir)
zip_ref.close()
드라이버 경로 설정¶
In [10]:
chrome_path = os.path.join(driver_dir, 'chromedriver.exe')
간단한 사용법¶
먼저 driver를 설정한다. 드라이버는 웹 브라우저에 해당하는 것이라고
생각할 수 있다. 드라이버는 브라우저의 종류에 따라 설치되어 있어야 한다.
위에서 PhantomJS 드라이버를 설치했다. 드라이버 연결할 때는 드라이버의
위치를 알려주는 방법과 운영체제의 경로에 있으면 된다. 아래는 크롬
브라우저를 이용해서 접근하기 위해 크롬
드라이버를
사용했다. 크롬 드라이버를 링크된 사이트에서 최신 버전으로 다운받아
drivers 디렉토리에 압축해제 시킨다. 그러면 chromedriver.exe 파일이
생긴다. 이것을 이용해 아래와 같이 사용할 수 있다.
In [12]:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
assert os.path.exists(chrome_path)
driver = webdriver.Chrome(chrome_path)
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.clear()
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_source
driver.close()
위의 것을 실행하면 새창에서 크롬 브라우저가 뜨고 파이썬 홈페이지에
접속해서 pycon을 검색한 후 자동으로 종료된다.
크롬 드라이버 위치를 지정한다.
chrome_path = 'drivers/chromedriver.exe'
지정된 경로가 올바르면 통과하고 그렇지 않으면 예외를 발생시키고 프로그램이 종료된다.
assert os.path.exists(chrome_path)
크롬 드라이버를 이용해 웹드라이버 인스턴스를 만든다.
driver = webdriver.Chrome(chrome_path)
get() 메소드를 이용해 사이트에 접속한다.
driver.get("http://www.python.org")
접속한 페이지 제목에 Python이 있는지 확인한다.
assert "Python" in driver.title
웹드라이버는 find_element_by_* 메소드를 이용해 성분을 찾아낼 수
있다. name 속성을 가진 input 성분은 find_element_by_name
메소드를 이용해서 찾을 수 있다. 아래는 속성이 name이고 속성값이
q인 성분을 찾아낸다.
elem = driver.find_element_by_name("q")
clear()는 텍스트가 있으면 없앤다. send_keys() 메소드는 텍스트
입력란에 원하는 텍스트를 입력하는 것이다. Keys.Return은 엔터키를
치는 것과 같다.
elem.clear()
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
close() 메소드는 현재 탭을 닫는다. quit() 메소드는 현재 창을
닫는다.
driver.close()
직접하기
- 크롬 드라이버를 다운로드받아 압축해제해서 위 프로그램을 실행하시오.
사이트에서 원하는 자료 가져오기¶
셀레늄을 이용해서 행정안전부
지방물가정보
사이트에 있는 2017년 10월 농축산물 평균가격을 가져와보자. 페이지 소스
보기를 하면 웹 페이지 상에 보이던 표가 보이지 않는 것을 알 수 있다.
이것은 표를 보여주는 부분이
iframe으로
처리되었기 때문이다. iframe은 inline frame으로 다른 위치에 있는 웹
페이지를 현재 위치에 보이게 하는 것이다. 따라서 iframe 위치로
이동하는 것이 필요하다.
In [15]:
import bs4
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import pandas as pd
options = webdriver.ChromeOptions()
options.add_argument('headless')
driver = webdriver.Chrome(chrome_path, chrome_options=options)
# 사이트에서 웹 문서 수집
site = 'http://www.mois.go.kr/frt/sub/a02/farmProductPriceList/screen.do'
driver.get(site)
# iframe 으로 이동
iframe = driver.find_element_by_css_selector('iframe')
driver.switch_to.frame(iframe)
# 2017년 10월 클릭
elem = driver.find_element_by_id('year')
select = Select(elem)
select.select_by_value("2017")
elem = driver.find_element_by_id('month')
select = Select(elem)
select.select_by_value("10")
driver.find_element_by_id('srch').click()
html = driver.page_source
driver.close()
bs = bs4.BeautifulSoup(html, 'html.parser')
tables = bs.select('div > table > tbody')
rows = tables[0].find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
print(cols)
['서울', '10,253', '2,337', '6,477', '2,030', '3,844', '2,602', '7,914', '4,049', '11,861', '54,003']
['부산', '9,591', '2,073', '5,753', '2,719', '4,216', '2,226', '7,207', '3,972', '9,397', '51,038']
['대구', '8,545', '2,152', '6,459', '2,025', '4,156', '2,239', '7,389', '3,645', '9,281', '50,006']
['인천', '8,768', '2,166', '6,040', '1,653', '3,843', '2,171', '7,536', '3,154', '9,350', '48,248']
['광주', '9,641', '2,125', '5,056', '1,944', '3,761', '2,041', '8,232', '4,248', '9,308', '49,167']
['대전', '8,167', '1,969', '5,365', '2,663', '3,385', '2,043', '8,687', '4,133', '9,532', '48,218']
['울산', '9,080', '2,060', '6,865', '2,402', '4,108', '2,253', '8,413', '4,656', '10,380', '51,747']
['경기', '9,485', '2,154', '5,992', '2,033', '3,973', '2,520', '7,571', '4,096', '10,134', '51,240']
['강원', '8,504', '1,940', '5,846', '1,774', '4,755', '2,656', '6,632', '3,593', '9,787', '50,420']
['충북', '9,577', '2,271', '5,450', '2,372', '4,093', '2,279', '7,682', '3,610', '10,348', '49,670']
['충남', '9,018', '1,995', '5,482', '1,760', '4,395', '2,503', '7,527', '4,541', '8,269', '50,291']
['전북', '8,678', '1,924', '5,595', '2,420', '3,282', '2,312', '7,142', '3,657', '8,313', '48,301']
['전남', '8,841', '1,926', '5,673', '2,547', '3,891', '2,103', '7,468', '3,304', '7,015', '46,352']
['경북', '7,768', '1,813', '5,714', '2,499', '4,253', '2,163', '7,461', '2,847', '9,127', '48,829']
['경남', '8,571', '2,033', '5,579', '2,392', '3,589', '2,249', '7,835', '3,175', '8,281', '47,036']
['제주', '8,508', '1,763', '6,291', '2,555', '4,692', '2,141', '7,115', '3,556', '8,752', '48,581']
직접하기
- 행정안전부 지방물가정보 사이트의 지방 공공 요금 페이지에서 2016년 1월 평균요금을 출력하시오.
- 평균요금을 숫자로 바꾸시오.
- 고려대 세종 캠퍼스 홈페이지에 있는 셔틀버스 시간표를 출력하시오.
- 네이버 로그인을 해서 이메일 제목을 출력하시오.
분석¶
pandas¶
pandas 모듈은 데이터를 다루기 편리한 메소드들을 제공한다.
생성¶
엑셀 데이터 읽기
In [93]:
import pandas as pd
pd.options.display.max_rows = 10
df_excel = pd.read_excel('http://qrc.depaul.edu/Excel_Files/Presidents.xls'); df_excel
Out[93]:
| President | Years in office | Year first inaugurated | Age at inauguration | State elected from | # of electoral votes | # of popular votes | National total votes | Total electoral votes | Rating points | Political Party | Occupation | College | % electoral | % popular | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | George Washington | 8.0 | 1789 | 57 | Virginia | 69 | NA() | NA() | 69 | 842.0 | None | Planter | None | 100.000000 | NA() |
| 1 | John Adams | 4.0 | 1797 | 61 | Massachusetts | 132 | NA() | NA() | 139 | 598.0 | Federalist | Lawyer | Harvard | 94.964029 | NA() |
| 2 | Thomas Jefferson | 8.0 | 1801 | 57 | Virginia | 73 | NA() | NA() | 137 | 711.0 | Democratic-Republican | Planter, Lawyer | William and Mary | 53.284672 | NA() |
| 3 | James Madison | 8.0 | 1809 | 57 | Virginia | 122 | NA() | NA() | 176 | 567.0 | Democratic-Republican | Lawyer | Princeton | 69.318182 | NA() |
| 4 | James Monroe | 8.0 | 1817 | 58 | Virginia | 183 | NA() | NA() | 221 | 602.0 | Democratic-Republican | Lawyer | William and Mary | 82.805430 | NA() |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 30 | Ronald Reagan | 8.0 | 1981 | 69 | California | 489 | 43904153 | 86515221 | 538 | 634.0 | Republican | Actor | Eureka College | 90.892193 | 50.7473 |
| 31 | George Bush | 4.0 | 1989 | 64 | Texas | 426 | 48886097 | 91584820 | 538 | 548.0 | Republican | Businessman | Yale | 79.182156 | 53.3779 |
| 32 | Bill Clinton | 8.0 | 1993 | 46 | Arkansas | 370 | 44909326 | 104425014 | 538 | 539.0 | Democrat | Lawyer | Georgetown | 68.773234 | 43.0063 |
| 33 | George W. Bush | 8.0 | 2001 | 54 | Texas | 271 | 50460110 | 105417258 | 538 | NaN | Republican | Businessman | Yale | 50.371747 | 47.867 |
| 34 | Barack Obama | NaN | 2009 | 47 | Illinois | 365 | 69492376 | 129438754 | 538 | NaN | Democrat | Lawyer | Columbia University | 67.843866 | 53.6875 |
35 rows × 15 columns
웹페이지 표 읽기(행정안전부 지방 물가 정보)
행정안전부 지방물가 정보 사이트 http://www.mois.go.kr/frt/sub/a02/mulMain/screen.do에서 농축산물 전월 평균 가격정보를 가져오자.
In [16]:
import bs4, requests
import pandas as pd
# 행정 안전부 지방 물가 정보 - 농축산물
site = 'http://www.mois.go.kr/frt/sub/a02/farmProductPriceList/screen.do'
# driver = webdriver.PhantomJS(executable_path=phantom_path)
options = webdriver.ChromeOptions()
options.add_argument('headless')
driver = webdriver.Chrome(chrome_path, chrome_options=options)
# 사이트에서 웹 문서 수집
driver.get(site)
# iframe 으로 이동
iframe = driver.find_element_by_css_selector('iframe')
driver.switch_to.frame(iframe)
# 2017년 10월 클릭
elem = driver.find_element_by_id('year')
select = Select(elem)
select.select_by_value("2017")
elem = driver.find_element_by_id('month')
select = Select(elem)
select.select_by_value("10")
driver.find_element_by_id('srch').click()
html = driver.page_source
driver.close()
df = pd.read_html(html, na_values=['-'])[0]
print(df)
구분 쇠고기 돼지고기 닭고기 달걀 배추 무 감자 고추가루 콩 쌀
0 서울 10253 2337 6477 2030 3844 2602 7914 4049 11861 54003
1 부산 9591 2073 5753 2719 4216 2226 7207 3972 9397 51038
2 대구 8545 2152 6459 2025 4156 2239 7389 3645 9281 50006
3 인천 8768 2166 6040 1653 3843 2171 7536 3154 9350 48248
4 광주 9641 2125 5056 1944 3761 2041 8232 4248 9308 49167
5 대전 8167 1969 5365 2663 3385 2043 8687 4133 9532 48218
6 울산 9080 2060 6865 2402 4108 2253 8413 4656 10380 51747
7 경기 9485 2154 5992 2033 3973 2520 7571 4096 10134 51240
8 강원 8504 1940 5846 1774 4755 2656 6632 3593 9787 50420
9 충북 9577 2271 5450 2372 4093 2279 7682 3610 10348 49670
10 충남 9018 1995 5482 1760 4395 2503 7527 4541 8269 50291
11 전북 8678 1924 5595 2420 3282 2312 7142 3657 8313 48301
12 전남 8841 1926 5673 2547 3891 2103 7468 3304 7015 46352
13 경북 7768 1813 5714 2499 4253 2163 7461 2847 9127 48829
14 경남 8571 2033 5579 2392 3589 2249 7835 3175 8281 47036
15 제주 8508 1763 6291 2555 4692 2141 7115 3556 8752 48581
참고: pd.read_html(웹페이지)은 웹 페이지에 있는 표(table)를 pandas
DataFrame 리스트로 변환한다.
직접하기
- 국가 지표 체계 홈페이지 http://www.index.go.kr/potal/main/EachDtlPageDetail.do?idx_cd=1007에서 지역별 인구 및 인구밀도 표를 출력하시오.
- 가져온 데이터의 열이름을
df.columns를 이용하여 변경하시오. 예를 들어2012인구,2012인구밀도등으로 바꾸시오.
데이터 프레임 내용 출력
In [77]:
df['구분'] # Series 형으로 출력
Out[77]:
0 서울
1 부산
2 대구
3 인천
4 광주
5 대전
6 울산
7 경기
8 강원
9 충북
10 충남
11 전북
12 전남
13 경북
14 경남
15 제주
Name: 구분, dtype: object
In [78]:
df[['구분', '쇠고기', '감자']] # DataFrame형 출력
Out[78]:
| 구분 | 쇠고기 | 감자 | |
|---|---|---|---|
| 0 | 서울 | 9864 | 3622 |
| 1 | 부산 | 9382 | 2929 |
| 2 | 대구 | 9428 | 3428 |
| 3 | 인천 | 8691 | 3761 |
| 4 | 광주 | 10433 | 3730 |
| 5 | 대전 | 8013 | 3876 |
| 6 | 울산 | 9160 | 3581 |
| 7 | 경기 | 9627 | 3713 |
| 8 | 강원 | 9251 | 3186 |
| 9 | 충북 | 9851 | 3132 |
| 10 | 충남 | 8258 | 3008 |
| 11 | 전북 | 8892 | 3557 |
| 12 | 전남 | 8716 | 3217 |
| 13 | 경북 | 7675 | 3006 |
| 14 | 경남 | 8795 | 3189 |
| 15 | 제주 | 8425 | 2910 |
직접하기
- 2012년 인구와 2017년 인구 밀도를 각각 출력하시오.
값 출력
정당에 속해 있는 사람들의 수를 센다.
In [79]:
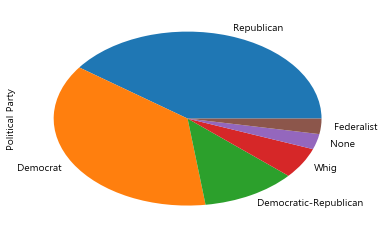
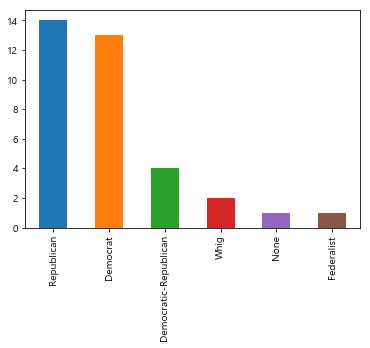
df_excel['Political Party'].value_counts()
Out[79]:
Republican 14
Democrat 13
Democratic-Republican 4
Whig 2
None 1
Federalist 1
Name: Political Party, dtype: int64
기본 통계¶
- 요약
describe() 함수를 이용하여 기본적인 통계량을 관찰할 수 있다.
describe(include='all')을 이용해서 모든 열에 대해서 통계량을
관찰할 수 있다.
In [80]:
df_excel.describe()
Out[80]:
| Years in office | Year first inaugurated | Age at inauguration | # of electoral votes | Total electoral votes | Rating points | % electoral | |
|---|---|---|---|---|---|---|---|
| count | 34.000000 | 35.000000 | 35.000000 | 35.000000 | 35.000000 | 33.000000 | 35.000000 |
| mean | 5.185294 | 1892.542857 | 55.085714 | 261.114286 | 385.085714 | 552.606061 | 68.048420 |
| std | 2.638426 | 64.758530 | 6.381828 | 118.620198 | 143.817567 | 159.117280 | 15.092928 |
| min | 0.500000 | 1789.000000 | 43.000000 | 69.000000 | 69.000000 | 259.000000 | 32.183908 |
| 25% | 4.000000 | 1843.000000 | 51.000000 | 176.000000 | 292.000000 | 444.000000 | 57.123855 |
| 50% | 4.000000 | 1885.000000 | 55.000000 | 234.000000 | 401.000000 | 564.000000 | 66.459627 |
| 75% | 8.000000 | 1943.000000 | 57.500000 | 343.000000 | 531.000000 | 632.000000 | 80.756370 |
| max | 12.000000 | 2009.000000 | 69.000000 | 489.000000 | 538.000000 | 900.000000 | 100.000000 |
In [81]:
df_excel.describe(include='all')
Out[81]:
| President | Years in office | Year first inaugurated | Age at inauguration | State elected from | # of electoral votes | # of popular votes | National total votes | Total electoral votes | Rating points | Political Party | Occupation | College | % electoral | % popular | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 35 | 34.000000 | 35.000000 | 35.000000 | 35 | 35.000000 | 35 | 35 | 35.000000 | 33.000000 | 35 | 35 | 35 | 35.000000 | 35 |
| unique | 34 | NaN | NaN | NaN | 15 | NaN | 30 | 30 | NaN | NaN | 6 | 10 | 20 | NaN | 30 |
| top | Grover Cleveland | NaN | NaN | NaN | New York | NaN | NA() | NA() | NaN | NaN | Republican | Lawyer | None | NaN | NA() |
| freq | 2 | NaN | NaN | NaN | 6 | NaN | 6 | 6 | NaN | NaN | 14 | 21 | 8 | NaN | 6 |
| mean | NaN | 5.185294 | 1892.542857 | 55.085714 | NaN | 261.114286 | NaN | NaN | 385.085714 | 552.606061 | NaN | NaN | NaN | 68.048420 | NaN |
| std | NaN | 2.638426 | 64.758530 | 6.381828 | NaN | 118.620198 | NaN | NaN | 143.817567 | 159.117280 | NaN | NaN | NaN | 15.092928 | NaN |
| min | NaN | 0.500000 | 1789.000000 | 43.000000 | NaN | 69.000000 | NaN | NaN | 69.000000 | 259.000000 | NaN | NaN | NaN | 32.183908 | NaN |
| 25% | NaN | 4.000000 | 1843.000000 | 51.000000 | NaN | 176.000000 | NaN | NaN | 292.000000 | 444.000000 | NaN | NaN | NaN | 57.123855 | NaN |
| 50% | NaN | 4.000000 | 1885.000000 | 55.000000 | NaN | 234.000000 | NaN | NaN | 401.000000 | 564.000000 | NaN | NaN | NaN | 66.459627 | NaN |
| 75% | NaN | 8.000000 | 1943.000000 | 57.500000 | NaN | 343.000000 | NaN | NaN | 531.000000 | 632.000000 | NaN | NaN | NaN | 80.756370 | NaN |
| max | NaN | 12.000000 | 2009.000000 | 69.000000 | NaN | 489.000000 | NaN | NaN | 538.000000 | 900.000000 | NaN | NaN | NaN | 100.000000 | NaN |
- 열별 평균, 합계
mean()함수를 이용하여 평균을 구할 수 있다. 숫자형에 대해서만 계산한다.sum()을 이용하여 열별 합계를 구할 수 있다. 문자열일 경우 각 행의 문자열들을 연결한다.
In [82]:
df.mean() # Series형 반환
Out[82]:
쇠고기 9028.8125
돼지고기 2364.6875
닭고기 5763.4375
달걀 2710.1875
배추 4160.1875
무 1897.2500
감자 3365.3125
고추가루 3325.9375
콩 9150.8750
쌀 43186.5000
dtype: float64
In [83]:
df.sum()
Out[83]:
구분 서울부산대구인천광주대전울산경기강원충북충남전북전남경북경남제주
쇠고기 144461
돼지고기 37835
닭고기 92215
달걀 43363
배추 66563
무 30356
감자 53845
고추가루 53215
콩 146414
쌀 690984
dtype: object
df.iloc[행슬라이싱, 열슬라이싱] 을 이용하여 파이썬 슬라이싱 문법을
사용할 수 있다.
In [84]:
df.iloc[:, 1:].sum()
Out[84]:
쇠고기 144461
돼지고기 37835
닭고기 92215
달걀 43363
배추 66563
무 30356
감자 53845
고추가루 53215
콩 146414
쌀 690984
dtype: int64
또한 이름으로도 가능한다. df.loc[:, '쇠고기':'닭고기']를 이용하여
쇠고기 열부터 닭고기 열까지를 잘라낼 수 있다.
In [85]:
df.loc[:5, '쇠고기':'닭고기']
Out[85]:
| 쇠고기 | 돼지고기 | 닭고기 | |
|---|---|---|---|
| 0 | 9864 | 2619 | 6353 |
| 1 | 9382 | 2370 | 5962 |
| 2 | 9428 | 2455 | 6423 |
| 3 | 8691 | 2438 | 5652 |
| 4 | 10433 | 2447 | 5219 |
| 5 | 8013 | 2599 | 5091 |
- 정렬
sort_values(by=['colname'])을 이용해서 지정된 열로 데이터프레임을 정렬할 수 있다.
In [86]:
df.sort_values(by=['쇠고기'])
Out[86]:
| 구분 | 쇠고기 | 돼지고기 | 닭고기 | 달걀 | 배추 | 무 | 감자 | 고추가루 | 콩 | 쌀 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 13 | 경북 | 7675 | 2136 | 5941 | 2953 | 4611 | 2032 | 3006 | 2588 | 9240 | 41505 |
| 5 | 대전 | 8013 | 2599 | 5091 | 3169 | 2905 | 1589 | 3876 | 4131 | 9329 | 42780 |
| 10 | 충남 | 8258 | 2146 | 5626 | 2400 | 4161 | 1914 | 3008 | 3784 | 8169 | 44093 |
| 15 | 제주 | 8425 | 2528 | 6298 | 2860 | 5522 | 2070 | 2910 | 3087 | 8152 | 43017 |
| 3 | 인천 | 8691 | 2438 | 5652 | 2179 | 3797 | 1622 | 3761 | 2783 | 9317 | 42322 |
| 12 | 전남 | 8716 | 2098 | 5391 | 3072 | 4268 | 2188 | 3217 | 3210 | 7373 | 40663 |
| 14 | 경남 | 8795 | 2165 | 5327 | 2960 | 3904 | 1917 | 3189 | 3027 | 8056 | 41187 |
| 11 | 전북 | 8892 | 2196 | 5353 | 2954 | 3270 | 1857 | 3557 | 3509 | 8580 | 42440 |
| 6 | 울산 | 9160 | 2196 | 6485 | 2587 | 4608 | 1935 | 3581 | 3957 | 10523 | 42880 |
| 8 | 강원 | 9251 | 2410 | 5627 | 2208 | 4249 | 1871 | 3186 | 3445 | 8535 | 45319 |
| 1 | 부산 | 9382 | 2370 | 5962 | 3497 | 5046 | 1961 | 2929 | 3329 | 9601 | 43952 |
| 2 | 대구 | 9428 | 2455 | 6423 | 2447 | 4345 | 1691 | 3428 | 3071 | 9373 | 41517 |
| 7 | 경기 | 9627 | 2389 | 5917 | 2542 | 4263 | 1860 | 3713 | 3304 | 9848 | 44653 |
| 9 | 충북 | 9851 | 2643 | 5550 | 2908 | 4044 | 2019 | 3132 | 3279 | 9297 | 42971 |
| 0 | 서울 | 9864 | 2619 | 6353 | 2281 | 3330 | 1769 | 3622 | 3329 | 11153 | 48638 |
| 4 | 광주 | 10433 | 2447 | 5219 | 2346 | 4240 | 2061 | 3730 | 3382 | 9868 | 43047 |
시각화¶
In [87]:
get_ipython().magic('matplotlib inline')
import matplotlib.pyplot as plt
import numpy as np
- line
In [88]:
%matplotlib inline
import numpy as np
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
df.set_index('구분').plot(kind='line', xticks=np.arange(len(df['구분'])), rot=90)
Out[88]:
<matplotlib.axes._subplots.AxesSubplot at 0x1c459a0cd68>
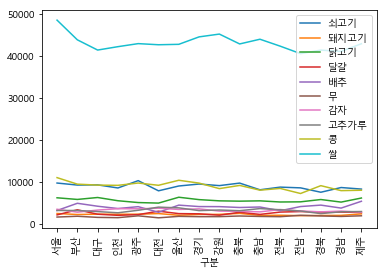
xticks=np.arange(16)는 xtick이 보여질 위치를 지정하는 것이다.
- boxplot
In [89]:
get_ipython().magic('matplotlib inline')
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
df.boxplot()
Out[89]:
<matplotlib.axes._subplots.AxesSubplot at 0x1c459ba8208>
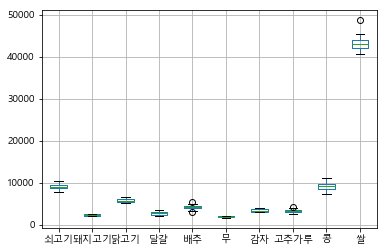
- 파이 그래프
In [90]:
get_ipython().magic('matplotlib inline')
df_excel['Political Party'].value_counts().plot(kind="pie")
Out[90]:
<matplotlib.axes._subplots.AxesSubplot at 0x1c45828d748>
- 바차트
In [91]:
df_excel['Political Party'].value_counts().plot(kind="bar")
Out[91]:
<matplotlib.axes._subplots.AxesSubplot at 0x1c459f66f98>
참고 사이트¶
- Beautiful Soup: https://www.crummy.com/software/BeautifulSoup/bs4/doc/#
- requests: http://pythonstudy.xyz/python/article/403-%ED%8C%8C%EC%9D%B4%EC%8D%AC-Web-Scraping
- urllib: https://www.acmicpc.net/blog/view/16
- Python for Data Analysis by Wes McKinney: https://github.com/wesm/pydata-book
- http://www.hanbit.co.kr/channel/category/category_view.html?cms_code=CMS9481416663
- Python for Data Analysis by Wes McKinney: https://github.com/wesm/pydata-book
- Pandas Documentation: http://pandas.pydata.org/pandas-docs/stable/