웹 데이터
HTML
웹페이지는 HTML이라는 언어로 작성되어 있습니다. HTML(Hyper Text Markup Language)이란 웹 페이지 작성에 사용되는 마크업(markup) 언어입니다. 마크업 언어란 태그(tag)를 이용하여 문서에 다양한 정보를 표현할 수 있게 해주는 언어입니다. 글자색을 바꾼다든지 그림, 소리를 삽입한다든지 링크를 삽입하는 등 여러 가지 기능들을 가능하게 해줍니다. 웹페이지는 구글 크롬(Google Chrome), 파이어폭스(Firefox), MS 엣지(edge), 사파리, 오페라, 인터넷 익스플로러(Internet Explorer) 등의 웹브라우저를 이용해서 볼 수 있습니다. 태그란 미리 약속된 문자열로 HTML에서는 화살표괄호 <과 > 사이에 위치합니다. HTML도 계속 발전되어 현재는 HTML5가 사용되고있습니다. HTML 문서의 기본 구조는 다음과 같습니다.
<!DOCTYPE html>
<html>
<head>
<title>웹 페이지 제목</title>
...
</head>
<body>
<h1>첫번째 제목</h1>
<p>첫번째 단락</p>
...
</body>
</html>
<!DOCTYPE html>은 문서의 제일 위에 한번만 사용하며 HTML5를 사용한다는 표시입니다.<html>은 HTML 문서의 시작을 알리는 태그입니다.<head>는 몸체(<body>)의 메타 정보를 포함합니다. 자바스크립트, 스타일, 제목 등이 들어갑니다.<title>은 웹 페이지 제목을 표시합니다.<body>는 브라우저를 통해 보는 내용들이 들어갑니다.<h1>은 가장 큰 글씨의 제목입니다.<p>는 단락을 나타냅니다.
태그
HTML 태그는 각각의 태그이름이 화살표괄호 <과 >에 의해 둘러 싸여 있습니다.
<태그이름>태그 안에 들어갈 내용들 ...</태그이름>
대부분의 태그는
<p>와</p>같이 쌍으로 이루어져 있습니다.앞에 있는 태그를 시작 태그(또는 여는 태그)라 하고 뒤에 있는 태그를 종료 태그(또는 닫는 태그)라고 합니다.
닫는 태그는 태그 이름 앞에 슬래시
/를 붙입니다.
HTML 페이지 구조를 도식화하면 다음과 같습니다.
<html>
<head>
<title>페이지 제목</title>
</head>
<body>
<h1>가장 큰 제목</h1>
<p>단락</p>
<p>또 다른 단락</p>
</body>
</html>
HTML 페이지 만들기
문서 편집기(메모장 또는 notepad++)를 엽니다.
새로운 문서를 열고 다음과 같이 입력합니다.
<!DOCTYPE html> <html> <body> <h1>첫번째 제목</h1> <p>이것은 첫번째 단락입니다.</p> </body> </html>
MyFirstWebPage.html이라고 저장합니다.저장된
MyFirstWebPage.html파일을 두번 클릭하여 엽니다.
그러면 다음 그림과 같이 보일 것입니다.
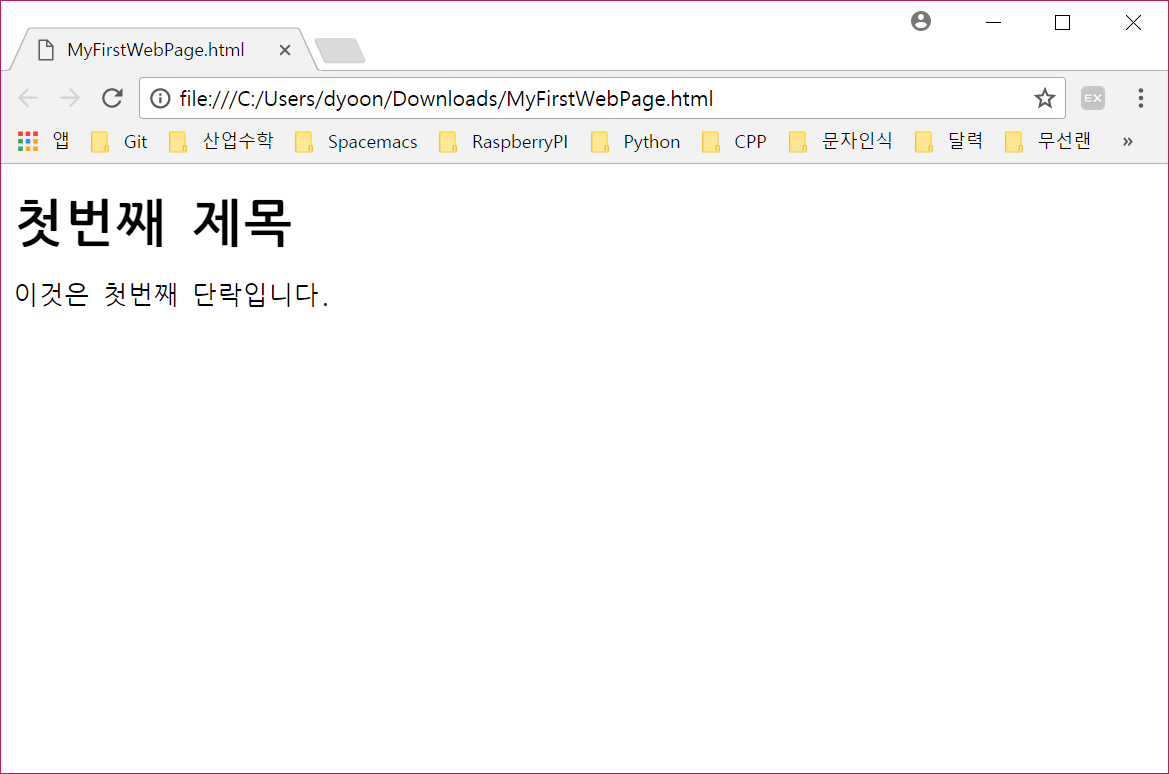
기본 태그들
헤딩(heading): 제목을 나타내는 헤딩은
<h1>,<h2>,…,<h6>까지 있습니다. 숫자가 커질수록 글자의 크기가 작아집니다.링크(link): 다른 곳을 가리키는 링크 태그는
<a>를 사용합니다. 여기서href를 태그<a>의 속성(attribute)이라고 합니다.<a href="https://www.google.com">구글 링크</a>
이미지: 그림을 삽입하는 태그는
<img>를 사용합니다. 여기서src, alt, width, height는<img>태그의 속성이라고 합니다.<img src="images/koala.jpg" alt="cute koala" width="104" height="142">
<img> 태그에서 보는 바와 같이 <img> 태그는 종료 태그가 없습니다. 태그 사이에 내용이 없을 경우는 종료 태그가 필요 없습니다. 새로운 줄로 이동하는 태그인 <br> 태그도 종료 태그가 없습니다.
HTML 성분(element)
HTML 성분(element) 또는 요소는 시작 태그, 태그 안의 내용과 종료 태그로 이루어집니다. 즉, 시작 태그부터 종료 태그까지를 태그의 성분이라고 합니다.
<태그이름> 태그 안의 내용 ... </태그이름>
다음은 태그 <p> 성분의 예입니다. 시작태그는 <p>, 내용은 이것은 단락을 나타냅니다., 종료태그는 </p> 입니다.
<p>이것은 단락을 나타냅니다.</p>
HTML 성분은 중첩될 수 있습니다. 다음 예에서 <html> 성분은 <body> 성분 전체로 이루어져 있습니다. <body> 성분은 시작 태그 <body>로부터 종료 태그 </body>까지 전체를 의미합니다.
<!DOCTYPE html>
<html>
<body>
<h1>첫번째 제목</h1>
<p>첫번째 단락</p>
</body>
</html>
HTML 태그는 대소문자를 구분하지 않습니다. 즉, 대문자 <P>와 소문자 <p>는 같은 의미입니다. XHTML에서는 소문자 태그만 유휴하므로 호환을 위해서 소문자 태그를 사용하는 것을 권합니다.
HTML 속성(attribute)
HTML 성분은 속성을 가질 수 있습니다. 속성은 성분의 추가 정보를 제공합니다. 속성은 시작 태그 안에 위치해 있어야 합니다. 속성은 속성이름="속성값" 형식으로 이루어집니다.
링크 태그
<a>는 다음과 같이 태그 내용물이 가리키는 주소href속성을 갖습니다.<a href="http://www.google.com">구글 링크</a>
이미지 태그
<img>는 이미지 파일의 위치를 가리키는 속성src및 가로, 세로의 크기를 나타내는width,height를 갖습니다. 크기의 기본 단위는 픽셀입니다.<img src="images/koala.jpg" width=500 height=500>
단락 태그
<p>의 속성style을 이용해 폰트, 글자색, 크기등을 지정할 수 있습니다.<p style="color:red">여기는 빨간색의 단락입니다.</p>
html태그의 속성 중lang을 이용하면 작성된 문서의 언어를 지정할 수 있습니다.<html lang="ko"> .... </html>
<p>태그의 속성 중title은 마우스를 단락 위에 올려 놓았을 때 보이는 문구입니다. 이것을 툴팁(tooltip)이라고도 부릅니다.<p title="간단한 단락 설명">이것은 단락입니다.</p>
CSS
CSS는 Cascading Style Sheets로 HTML 성분들이 보여지는 모습을 지정합니다. CSS를 이용하면 웹 페이지의 모습을 일관성있게 변경할 수 있으며 성분들을 개별적으로 수정하는 시간을 줄일 수 있습니다. 여기서는 CSS가 어떤 것이지에 대한 맛보기 정도로만 다룹니다. 자세한 것은 w3schools.com을 참조합니다.
CSS 접근
CSS를 구현하는 방법은 크게 3가지로 나눌 수 있습니다.
인라인 CSS: HTML 태그 속성으로 구현합니다.
내부 CSS: HTML head 안에 구현합니다.
외부 CSS: CSS 파일을 이용합니다.
인라인 CSS
HTML 성분의 속성으로 설정하는 것입니다. 다음과 같이 h1 태그의 속성 style을 이용해 글자색을 파란색으로 변경합니다.
<h1 style="color:blue;">파란색 제목</h1>
파란색 제목
내부 CSS
HTML 성분 <head> 안에 <style> 성분을 지정해서 <body> 전체에 영향을 미치게 할 수 있습니다.
<!DOCTYPE html>
<html>
<head>
<style>
body {background-color: powderblue;}
h1 {color: blue;}
p {color: red;}
</style>
</head>
<body>
<h1>제목</h1>
<p>이 부분이 단락입니다.</p>
</body>
</html>
<style>태그를 이용해서 CSS를 설정합니다.body {background-color: powderblue;}body태그의 속성background-color의 값을powderblue로 지정해서 배경색을 변경합니다. 다른 태그의 속성도 마찬가지로 적용합니다.
외부 CSS
외부 CSS를 이용하면 웹 사이트 전체의 외관을 변경할 수도 있습니다. 다음과 같이 head 태그 안에 link 태그를 이용해서 CSS 파일의 위치를 href 속성을 이용해서 알려줍니다.
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<h1>제목</h1>
<p>이 부분이 단락입니다.</p>
</body>
</html>
style.css 파일을 HTML 페이지 파일과 같은 곳에 하나 만들고 다음과 같이 CSS를 입력합니다.
body {
background-color: powderblue;
}
h1 {
color: blue;
}
p {
color: red;
}
이렇게 하면 위에서 내부 CSS와 같은 외관을 갖게됩니다.
CSS 선택자
css 구문은 다음과 같습니다. 선택자 다음에 중괄호를 열고 변경하고자 하는 속성 property들을 나열한 후 중괄호를 닫으면 됩니다. 속성은 속성이름 property name과 속성값 property name으로 이루어집니다. 중괄호 안에서 속성들을 구분하는 것으로 세미콜론 ;을 사용합니다.
선택자 {속성이름1: 속성값1; 속성이름2: 속성값2; ....}
예를 들면 <p> 태그 글자를 빨간색으로 크기는 large로 변경하려면 다음과 같이 하면 됩니다.
p {color: red; font-size: large}
선택자로는 태그, 클래스, 아이디, 태그 속성 등을 사용할 수 있습니다.
CSS id 속성
HTML 성분을 유일한 id를 설정하여 접근할 수 있습니다. id 속성은 다음과 같이 합니다.
<p id="p01">I am different</p>
특정 id 성분의 스타일 설정은 id 속성값 앞에 #을 붙이면 됩니다.
#p01 {
color: blue;
}
class 속성
원하는 이름의 스타일의 이름을 지정하기 위해서 class 속성을 지정합니다.
<p class="error">I am different</p>
스타일 시트에서는 태그 이름과 .을 붙여서 사용합니다. 태그 이름을 붙이지 않아도 되는데 이때는 지정된 클래스 이름을 갖는 모든 성분에 적용이 됩니다.
p.error {
color: red;
}
다음 표는 선택자 문법 요약 일부 입니다.
Selector |
예제 |
설명 |
|---|---|---|
|
|
모든 성분 선택 |
|
|
|
|
|
속성이름이 |
|
|
속성이름이 |
|
|
|
|
|
속성이름이 |
|
|
속성이름이 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
부모가 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CSS 폰트(Font)
다음과 같이 각 성분의 폰트와 글자색, 글자 크기를 조정할 수 있습니다.
<!DOCTYPE html>
<html>
<head>
<style>
h1 {
color: blue;
font-family: verdana;
font-size: 300%;
}
p {
color: red;
font-family: courier;
font-size: 160%;
}
</style>
</head>
<body>
<h1>This is a heading</h1>
<p>This is a paragraph.</p>
</body>
</html>
CSS 테두리
border 속성을 이용해서 각 성분의 테두리를 설정합니다.
p {
border: 1px solid powderblue;
}
CSS 패딩
padding 속성을 이용해서 텍스트와 테두리 사이의 간격(패딩)을 설정합니다.
p {
border: 1px solid powderblue;
padding: 30px;
}
CSS 마진
margin 속성을 이용해서 성분의 테두리 바깥 간격(마진)을 설정합니다.
p {
border: 1px solid powderblue;
margin: 50px;
}
웹페이지 읽기
웹페이지에는 많은 양의 정보들이 담겨있습니다. 이러한 정보를 활용하는 방법에 대해서 알아봅니다.
requests 모듈 이용 웹 페이지 읽기
웹페이지는 HTML로 이루어졌기 때문에 파이썬 HTTP 라이브러리 requests 모듈을 이용하여 웹 페이지를 읽어 올 수 있습니다. requests 모듈은 http 요청및 응답을 처리하는 편리한 방법들을 제공합니다.
설치가 안되어 있으면 다음과 같이 설치를 합니다.
conda install requests
# 또는
python -m pip install requests
In [1]: import requests
...:
...: url = 'http://sejong.korea.ac.kr'
...: r = requests.get(url, verify=False)
...: print(r.headers)
...:
verify=False는 인증서 인증을 생략합니다.
파일로 저장하기 위해서는 open() 함수를 이용합니다.
In [2]: import requests
...:
...: url = 'http://sejong.korea.ac.kr'
...: r = requests.get(url, verify=False)
...: with open('sejong.html', 'w', encoding='utf-8') as f:
...: f.write(r.text)
...:
예제: HTML에서 자료 추출
다음은 www.worldclimate.com 에서 제공하는 1954년부터 1980년 사이의 서울 평균 강수량 자료입니다.
http://www.worldclimate.com/cgi-bin/data.pl?ref=N37E126+2100+4710801G1
여기서 테이블에 있는 평균 기온 자료들을 불러오도록 합니다. 우선 seoul.html 파일로 저장합니다.
In [3]: import requests
...:
...: url = 'http://www.worldclimate.com/cgi-bin/data.pl?ref=N37E126+2100+4710801G1'
...: r = requests.get(url)
...: with open('src/seoul.html', 'w', encoding='utf-8') as f:
...: f.write(r.text)
...:
seoul.html 파일 중에서 다음과 같이 시작하는 부분이 표부분입니다.
<p>Weather station <strong>SEOUL INT. AIRPORT</strong> ...
<table width=90% border=1>
<tr><th align=right><th> Jan<th> Feb<th> ... <br>
<tr><td> mm <td align=right> 20.7 <td align=right> 27.9 ... <br>
<tr><td>inches <td align=right>0.8<td align=right>1.1 ... <br>
In [4]: with open('src/seoul.html', 'r') as infile:
...: rainfall = []
...: for line in infile:
...: if 'Weather station' in line:
...: station = line.split('</strong>')[0].split('<strong>')[1]
...: if '<td> mm <td' in line:
...: data = line.split('<td align=right>')
...:
...: data
...:
Out[4]:
['<tr><td> mm ',
' 20.7 ',
' 27.9 ',
' 49.0 ',
'104.9 ',
' 88.4 ',
'150.8 ',
'383.5 ',
'262.7 ',
'160.4 ',
' 48.5 ',
' 43.0 ',
' 24.4 ',
'1364.8<br> \n']
data 에서 <br>... 부분을 제거합니다.
In [5]: data[-1] = data[-1].split('<br>')[0]
...: data
...:
Out[5]:
['<tr><td> mm ',
' 20.7 ',
' 27.9 ',
' 49.0 ',
'104.9 ',
' 88.4 ',
'150.8 ',
'383.5 ',
'262.7 ',
'160.4 ',
' 48.5 ',
' 43.0 ',
' 24.4 ',
'1364.8']
그리고 실수형으로 변경하여 저장하면 됩니다.
In [6]: data = [float(x) for x in data[1:]]
...: data
...:
Out[6]:
[20.7,
27.9,
49.0,
104.9,
88.4,
150.8,
383.5,
262.7,
160.4,
48.5,
43.0,
24.4,
1364.8]
더 전문적인 웹페이지 분석 라이브러리로는 Beautifulsoup, lxml, Selenium 등이 있습니다.
다음(daum) 홈페이지 출력
다음(daum) 홈페이지에 접속해서 HTML 문서를 가져와 화면에 출력하는 예입니다.
import requests
resp = requests.get('http://daum.net') # 웹 사이트 접속
if (resp.status_code == requests.codes.ok): # 응답이 정상
resp.encoding = resp.apparent_encoding # 인코딩 설정
html = resp.text # 웹 페이지 읽기
print(html.split('\n')[0:10]) # 웹 페이지 10줄 출력
['<!DOCTYPE html>', '<html lang="ko" class="">', '<head>', '<meta charset="utf-8"/>', '<title>Daum</title>', '<meta property="og:url" content="https://www.daum.net/">', '<meta property="og:type" content="website">', '<meta property="og:title" content="Daum">', '<meta property="og:image" content="//i1.daumcdn.net/svc/image/U03/common_icon/5587C4E4012FCD0001">', '<meta property="og:description" content="나의 관심 콘텐츠를 가장 즐겁게 볼 수 있는 Daum">']
requests.get(사이트주소)은 요청 메시지의get메소드를 이용하여 사이트 주소의 페이지를 요청합니다.resp.status_code는 응답 객체의 상태를 나타내는 것으로 정상이면200을 반환합니다.requests.codes.ok는 정상 코드200을 나타내는 상수입니다.resp.text은 웹 페이지의html페이지를 반환합니다.클라이언트의 잘못된 요청에 대해 서버는 여러 가지 에러를 반환할 수 있습니다.(에러 코드 4xx, 5xx) 이러한 응답에 대해서
Response.raise_for_status()메소드를 이용해 예외를 발생시킬 수 있습니다.
만일 한글이 깨져 보이면 다음과 같이 인코딩을 변경해봅니다.
resp.encoding = resp.apparent_encoding
Response.apparent_encoding은 페이지의 charset으로부터 추정한 인코딩입니다.
구글 검색 결과 출력
구글에 접속해서 원하는 단어를 검색하여 출력할 수 있습니다. 구글에서 검색어를 입력하면 주소창에 search?q=검색어와 같은 문자열이 입력되어 있는
것을 확인할 수 있습니다. 이것을 이용해 다음과 같이 직접 검색어를 사이트 주소와 함께 입력해 주면 검색 결과를 얻을 수 있습니다.
import requests
resp = requests.get('https://google.co.kr/search?q=인공지능')
if (resp.status_code == requests.codes.ok):
html = resp.text
print(html[:100], '...중간 생략...', html[-100:], sep='\n')
<!doctype html><html itemscope="" itemtype="http://schema.org/SearchResultsPage" lang="ko"><head><me
...중간 생략...
"/client_204?&atyp=i&biw="+a+"&bih="+b+"&ei="+google.kEI);}).call(this);})();</script></body></html>
인공지능이란 단어를 검색한 결과를 출력한 것입니다. 내용이 너무 길어 중간 생략을 했습니다.
파일로 저장하려면 다음과 같이합니다.
with open('g.html', 'w', encoding='utf-8') as f:
f.write(resp.text)
직접하기
다음(daum) 사이트에서 “날씨”를 검색하여 결과를 출력하시오.
검색 결과를 파일로 저장하여 웹 브라우저로 열어 보세요.
파싱(Beautiful Soup)
Beautiful Soup 모듈을 이용해서 웹 페이지에서 필요한 정보들을 찾아낼 수 있습니다. 포털 사이트에서 주요 뉴스 제목을 찾아내거나 검색 사이트에서 원하는 단어를 검색한 결과를 볼 수 있습니다.
설치
pip install beautifulsoup4 # 또는
conda install -c anaconda beautifulsoup4 # 아나콘다를 이용할 경우
BeautifulSoup 웹페이지 파싱
웹 문서를 입력받아 bs객체를 만든다. bs 객체를 이용하여 필요한 정보들에 접근해서 원하는 것들을 수집할 수 있습니다. 원하는 성분으로 접근하는 방법은 여러 가지가 있으나 select() 메소드를 이용하는 방법이 있습니다. select 메소드의 인자는 CSS(Cascading Style Sheets) selector 조합 문자열을 사용합니다. css selector에 대한 자세한 설명은 W3 Schools CSS Selector Reference를 참조합니다. 다음은 몇 가지 예를 보여줍니다.
html 성분(element 또는 tag)은 다음과 같은 형식으로 이루어져 있습니다.
<tag_or_element attribute="value">text</tag_or_element>
다음은 html 예제의 일부입니다.
<div class="intro"> <!-- div는 성분, class는 속성, "intro"는 class 속성값입니다.-->
<p>My name is Donald <span id="Lastname">Duck.</span></p>
<p id="my-Address">I live in Duckburg</p>
<p>I have many friends:</p>
</div>
In [7]: import bs4
...:
...: html = "<html><head><title>제목</title></head><body>...생략...</body></html>"
...: bs = bs4.BeautifulSoup(html, 'html.parser')
...:
html.parser는 bs4가 어떤 파서를 이용해서 파싱을 할 것인가를 선택하게 되어 있습니다. 기본값으로 html.parser 이지만 틀리게 파싱하는 경우가 발생할 수 있습니다. 그럴때는 html5lib 파서를 사용하던지 lxml 파서를 이용하도록 합니다. 파서에 대한 설명은 이곳 을 참조하세요.
In [8]: html = """
...: <html>
...:
...: <head>
...: </head>
...:
...: <body>
...: <h1>Welcome to My Homepage</h1>
...: <div class="intro">
...: <p>My name is Donald <span id="Lastname">Duck.</span></p>
...:
...: <p id="my-Address">I live in Duckburg</p>
...:
...: <p>I have many friends:</p>
...: </div>
...:
...: <ul id="Listfriends">
...: <li>Goofy</li>
...: <li>Mickey</li>
...: <li>Daisy</li>
...: <li>Pluto</li>
...: </ul>
...:
...: <p>All my friends are great!<br>
...: But I really like Daisy!!</p>
...:
...: <p lang="it" title="Hello beautiful">Ciao bella</p>
...:
...: <h3>We are all animals!</h3>
...:
...: <p><b>My latest discoveries have led me to believe that we are all animals:</b></p>
...:
...: <table>
...: <thead>
...: <tr>
...: <th>Name</th> <th>Type of Animal</th>
...: </tr>
...: </thead>
...: <tr>
...: <td>Mickey</td> <td>Mouse</td>
...: </tr>
...: <tr>
...: <td>Goofey</td> <td>Dog</td>
...: </tr>
...: <tr>
...: <td>Daisy</td> <td>Duck</td>
...: </tr>
...: <tr>
...: <td>Pluto</td> <td>Dog</td>
...: </tr>
...: </table>
...:
...: </body>
...: </html>
...: """
...:
...: bs = bs4.BeautifulSoup(html, 'html.parser')
...: bs.select('table')
...:
Out[8]:
[<table>
<thead>
<tr>
<th>Name</th> <th>Type of Animal</th>
</tr>
</thead>
<tr>
<td>Mickey</td> <td>Mouse</td>
</tr>
<tr>
<td>Goofey</td> <td>Dog</td>
</tr>
<tr>
<td>Daisy</td> <td>Duck</td>
</tr>
<tr>
<td>Pluto</td> <td>Dog</td>
</tr>
</table>]
다음 html 문서를 이용해서 예제들을 살펴봅니다.
In [9]: html_doc = """
...: <html><head><title>The Dormouse's story</title></head>
...: <body>
...: <p class="title"><b>The Dormouse's story</b></p>
...:
...: <p class="story">Once upon a time there were three little sisters; and their names were
...: <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
...: <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
...: <a href="http://example.com/tillie" class="sister-act" id="link3">Tillie</a>;
...: <a href="https://example.com/tillie" class="sister">Secure Tillie</a>;
...: and they lived at the bottom of a well.</p>
...:
...: <p class="story">...</p>
...: <div class="box clever">
...: <p>Box Office</p>
...: <p>Clever guy</p>
...: <p>Gorgeous actress</p>
...: </div>
...: </body>
...: </html>
...: """
...:
성분들을 찾습니다.
In [10]: soup = bs4.BeautifulSoup(html_doc, 'html.parser')
태그 이름이 title인 모든 성분을 찾습니다.
In [11]: soup.select('title')
Out[11]: [<title>The Dormouse's story</title>]
p의 부모의 자식 중 3번째 p를 찾습니다.
In [12]: soup.select("p:nth-of-type(3)")
Out[12]: [<p class="story">...</p>, <p>Gorgeous actress</p>]
직접하기
soup.select("p:nth-of-type(3)")를 CSS에서 확인해봅니다.
성분 밑의 성분 찾기
body의 자손 중 a 성분을 모두 찾습니다.
In [13]: soup.select("body a")
Out[13]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
html 자손으로 head 자손 중 title 성분을 모두 찾습니다.
In [14]: soup.select("html head title")
Out[14]: [<title>The Dormouse's story</title>]
성분 바로 밑의 성분 찾기
head 성분의 자식 중 title 성분을 모두 찾습니다.
In [15]: soup.select("head > title")
Out[15]: [<title>The Dormouse's story</title>]
p의 자식 중 a인 성분 모두 찾습니다.
In [16]: soup.select("p > a")
Out[16]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
p의 자식 중 a 성분들 중에서 2번째 성분을 찾습니다.
In [17]: soup.select("p > a:nth-of-type(2)")
Out[17]: [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
p의 자식 중 id가 link1인 성분을 찾습니다.
In [18]: soup.select("p > #link1")
Out[18]: [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
body 자식 중 a 성분을 찾지만 없으므로 빈 리스트가 됩니다.
In [19]: soup.select("body > a")
Out[19]: []
같은 수준의 성분들 찾기
id가 link1인 태그의 형제들 중 class 값이 sister인 모든 성분들을 찾습니다.
In [20]: soup.select("#link1 ~ .sister")
Out[20]:
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
id가 link1인 태그의 형제들 중 id가 link1인 성분 바로 아래 붙어있는 class 값이 sister인 성분을 찾습니다.
In [21]: soup.select("#link1 + .sister")
Out[21]: [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
CSS 클래스에 의한 성분 찾기
클래스 값이 sister인 성분들 모두 찾습니다.
In [22]: soup.select(".sister")
Out[22]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
클래스 속성값이 단어 sister를 포함하는 모든 성분을 찾습니다.
In [23]: soup.select("[class~=sister]")
Out[23]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
|는 뒤에 하이픈(-)이 있어도 찾습니다.
In [24]: soup.select("[class|=sister]")
Out[24]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
클래스 속성값이 si를 포함하는 모든 성분을 찾습니다. ~와 다른 점은 ~는 단어 전체를 찾고 *는 부분 문자열이 포함된 것을 찾습니다.
In [25]: soup.select("[class*=si]")
Out[25]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
ID에 의한 성분 찾기
id가 link1인 성분을 찾습니다.
In [26]: soup.select("#link1")
Out[26]: [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
아이디가 link2이며 태그가 a인 성분을 찾습니다.
In [27]: soup.select("a#link2")
Out[27]: [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
속성에 의해 찾기
href 속성을 갖는 모든 a 태그들을 찾습니다.
In [28]: soup.select('a[href]')
Out[28]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
속성값에 의한 찾기
a 태그의 속성 href의 값이 http://example.com/elsie인 모든 성분을 찾습니다.
In [29]: soup.select('a[href="http://example.com/elsie"]')
Out[29]: [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
href 속성값 중 http로 시작하는 a 태그들 모두를 찾습니다.
In [30]: soup.select('a[href^="http"]')
Out[30]:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
태그 a의 속성이 href이고 href의 속성값이 tillie로 끝나는 성분들을 찾습니다.
In [31]: soup.select('a[href$="tillie"]')
Out[31]:
[<a class="sister-act" href="http://example.com/tillie" id="link3">Tillie</a>,
<a class="sister" href="https://example.com/tillie">Secure Tillie</a>]
속성 href의 값이 .com/el을 포함하는 태그 a들을 모두 찾습니다.
In [32]: soup.select('a[href*=".com/el"]')
Out[32]: [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
네이버 금융 사이트에서 주요 뉴스 제목 발췌
다음 코드는 최근 페이지가 적용이 되지 않아 작동하지 않을수도 있습니다. 참고로만 사용하세요.
import requests, bs4
resp = requests.get('http://finance.naver.com/')
resp.raise_for_status()
resp.encoding = resp.apparent_encoding
html = resp.text
bs = bs4.BeautifulSoup(html, 'html.parser')
print(bs.prettify()[0:100], "\n.\n.\n.\n", bs.prettify()[-100:])
tags = bs.select('div.news_area h2 a') # 헤드라인 뉴스 제목
title = tags[0].getText()
print("헤드라인 제목: ", title)
<html lang="ko">
<head>
<title>
네이버 금융
</title>
<meta content="text/html; charset=utf-8" h
.
.
.
, 이미지 리플레시
jindo.$Fn(mainPageDomReadyFn).attach(document, "domready");
</script>
</body>
</html>
헤드라인 제목: "한국 기업 이익 증가 추세 지속"…유..
직접하기
다음(daum) 뉴스에서 주요 뉴스 제목들을 추출해 보세요.
네이버 사이트에서 코스피 실시간 지수를 출력하고 100을 더한 값도 출력해 보세요.
네이버 환율 사이트에서 엔화 현찰 살때 팔때 환율을 출력하세요.
iframe으로 연결되어 있어서 사이트 주소를 정확히 입력해야 합니다.위에서 구한 환율 테이블을 넘파이 배열로 변환해 보세요.